EmbBERT-Q: Breaking Memory Barriers in Embedded NLP
作者: Riccardo Bravin, Massimo Pavan, Hazem Hesham Yousef Shalby, Fabrizio Pittorino, Manuel Roveri
分类: cs.CL, cs.AR, cs.DC, cs.LG
发布日期: 2025-02-14
备注: 24 pages, 4 figures, 14 tables
🔗 代码/项目: GITHUB
💡 一句话要点
EmbBERT-Q:突破嵌入式NLP的内存壁垒,专为资源受限设备设计。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 嵌入式NLP 微型语言模型 模型量化 低资源设备 Transformer TinyML 自然语言处理
📋 核心要点
- 现有大型语言模型内存需求高,难以在可穿戴设备和物联网等资源受限的微型设备上部署。
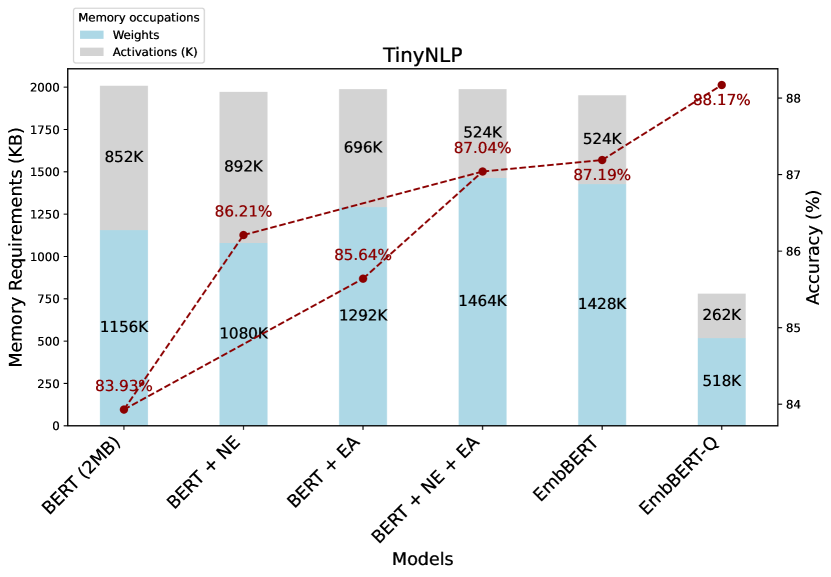
- EmbBERT-Q通过架构创新和8位量化,显著降低模型大小,实现在微型设备上的高效部署。
- 实验表明,EmbBERT-Q在TinyNLP和GLUE基准测试中,以极小的内存占用实现了有竞争力的精度。
📝 摘要(中文)
大型语言模型(LLMs)彻底改变了自然语言处理,并在广泛的应用中设定了新的标准。然而,它们显著的内存和计算需求使其无法部署在技术受限的微型设备上,例如可穿戴设备和物联网单元。为了解决这个限制,我们引入了EmbBERT-Q,一种专为具有严格内存约束的微型设备设计的新型微型语言模型。EmbBERT-Q在这种场景下实现了自然语言处理任务中最先进(SotA)的精度,总内存占用(权重和激活)仅为781 kB,与SotA模型相比,尺寸缩小了25倍。通过将架构创新与硬件兼容的8位量化相结合,EmbBERT-Q始终优于缩减到2 MB内存预算(即微型设备中通常可用的最大内存)的几个基线模型,包括BERT和MAMBA的重度压缩版本。在专门用于评估NLP任务中微型语言模型的TinyNLP基准数据集和真实场景以及GLUE基准上的大量实验评估表明,EmbBERT-Q能够提供与现有方法相比具有竞争力的精度,并在内存和性能之间实现无与伦比的平衡。为了确保我们所有结果的完整和即时可重复性,我们在https://github.com/RiccardoBravin/tiny-LLM上发布了所有代码、脚本和模型检查点。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在资源受限的微型设备上部署的问题。现有LLMs的巨大内存占用和计算需求使其无法在这些设备上运行,限制了NLP技术在物联网、可穿戴设备等领域的应用。
核心思路:论文的核心思路是通过模型架构创新和硬件兼容的量化技术,大幅度降低模型的大小,同时保持较高的精度。通过减小模型尺寸,使其能够在内存受限的设备上运行,从而实现嵌入式NLP应用。
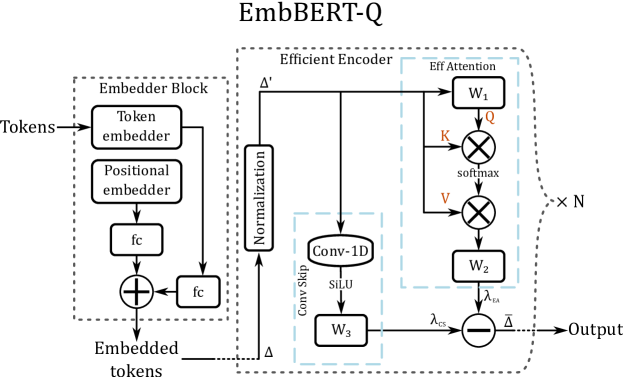
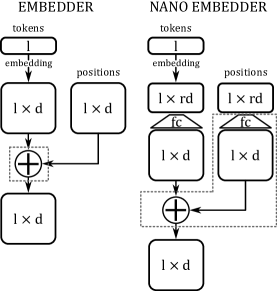
技术框架:EmbBERT-Q的技术框架主要包括以下几个部分:首先,设计一种轻量级的Transformer模型架构,减少参数数量。其次,采用硬件兼容的8位量化技术,进一步压缩模型大小。最后,在TinyNLP和GLUE等基准数据集上进行评估,验证模型的性能。
关键创新:EmbBERT-Q的关键创新在于其在极小的内存占用下实现了与现有方法相比具有竞争力的精度。通过结合架构创新和8位量化,该模型在内存效率方面取得了显著的提升,突破了嵌入式NLP的内存壁垒。
关键设计:EmbBERT-Q的关键设计包括:特定的Transformer层配置,例如减少层数、隐藏层大小等;采用均匀量化方法,将模型权重和激活值量化为8位整数;针对目标硬件平台进行优化,确保量化后的模型能够高效运行。
🖼️ 关键图片
📊 实验亮点
EmbBERT-Q实现了仅781KB的内存占用,相比SOTA模型缩小了25倍。在2MB内存预算下,EmbBERT-Q优于压缩后的BERT和MAMBA模型。在TinyNLP和GLUE基准测试中,EmbBERT-Q实现了与现有方法相比具有竞争力的精度,在内存和性能之间取得了良好的平衡。所有代码、脚本和模型检查点均已开源。
🎯 应用场景
EmbBERT-Q适用于各种资源受限的嵌入式NLP应用,例如可穿戴设备上的语音助手、物联网设备上的智能传感器、以及其他需要本地化自然语言处理能力的场景。该研究的实际价值在于降低了NLP技术的使用门槛,使得更多设备能够具备智能化的语言理解能力。未来,EmbBERT-Q有望推动嵌入式人工智能的发展,实现更广泛的应用。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized natural language processing, setting new standards across a wide range of applications. However, their relevant memory and computational demands make them impractical for deployment on technologically-constrained tiny devices such as wearable devices and Internet-of-Things units. To address this limitation, we introduce EmbBERT-Q, a novel tiny language model specifically designed for tiny devices with stringent memory constraints. EmbBERT-Q achieves state-of-the-art (SotA) accuracy in Natural Language Processing tasks in this scenario, with a total memory footprint (weights and activations) of just 781 kB, representing a 25x reduction in size with respect to SotA models. By combining architectural innovations with hardware-compatible 8-bit quantization, EmbBERT-Q consistently outperforms several baseline models scaled down to a 2 MB memory budget (i.e., the maximum memory typically available in tiny devices), including heavily compressed versions of BERT and MAMBA. Extensive experimental evaluations on both a selected benchmark dataset, TinyNLP, specifically curated to evaluate Tiny Language Models in NLP tasks and real-world scenarios, and the GLUE benchmark, demonstrate EmbBERT-Q ability to deliver competitive accuracy with respect to existing approaches, achieving an unmatched balance between memory and performance. To ensure the complete and immediate reproducibility of all our results, we release all code, scripts, and model checkpoints at https://github.com/RiccardoBravin/tiny-LLM.