LaRA: Benchmarking Retrieval-Augmented Generation and Long-Context LLMs -- No Silver Bullet for LC or RAG Routing
作者: Kuan Li, Liwen Zhang, Yong Jiang, Pengjun Xie, Fei Huang, Shuai Wang, Minhao Cheng
分类: cs.CL, cs.AI
发布日期: 2025-02-14 (更新: 2025-03-05)
备注: 22 pages
🔗 代码/项目: GITHUB
💡 一句话要点
LaRA:基准测试检索增强生成与长文本LLM,揭示长文本处理或RAG路由并非万能解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 长文本LLM 基准测试 知识融合 大型语言模型
📋 核心要点
- 现有研究在RAG和长文本LLM的对比上存在不足,主要是因为基准测试设计存在局限性,难以得出明确结论。
- 论文提出了LaRA基准,旨在系统性地比较RAG和长文本LLM在不同任务和模型上的表现,从而指导实际应用。
- 实验结果表明,RAG和长文本LLM的选择取决于多种因素的复杂交互,包括模型大小、长文本能力和任务类型等。
📝 摘要(中文)
将外部知识有效融入大型语言模型(LLMs)对于增强其能力和满足实际需求至关重要。检索增强生成(RAG)通过检索最相关的片段到LLMs中,提供了一种有效的方法来实现这一点。然而,LLMs上下文窗口大小的进步提供了一种替代方法,引发了RAG对于有效处理外部知识是否仍然必要的疑问。由于基准设计的局限性,现有的一些研究对RAG和长文本(LC)LLMs的比较尚无定论。在本文中,我们提出了LaRA,这是一个专门为严格比较RAG和LC LLMs而设计的新基准。LaRA包含跨四个实际QA任务类别和三种自然发生的文本类型的2326个测试用例。通过对七个开源和四个专有LLMs的系统评估,我们发现RAG和LC之间的最佳选择取决于多种因素的复杂相互作用,包括模型的参数大小、长文本能力、上下文长度、任务类型和检索块的特征。我们的发现为从业者提供了有效的指导,以在开发和部署LLM应用程序中有效地利用RAG和LC方法。我们的代码和数据集可在https://github.com/Alibaba-NLP/LaRA获得。
🔬 方法详解
问题定义:论文旨在解决如何有效利用外部知识增强大型语言模型(LLM)能力的问题。现有方法,如检索增强生成(RAG)和长文本LLM,各有优缺点,但在实际应用中如何选择仍然缺乏明确指导。现有的基准测试设计存在局限性,无法充分评估RAG和长文本LLM的性能差异。
核心思路:论文的核心思路是构建一个更全面、更严格的基准测试LaRA,用于系统性地比较RAG和长文本LLM在不同任务和模型上的表现。通过分析不同因素(如模型大小、长文本能力、任务类型等)对性能的影响,为实际应用提供更具体的指导。
技术框架:LaRA基准测试包含以下几个主要组成部分: 1. 数据集:包含2326个测试用例,涵盖四个实际QA任务类别和三种自然发生的文本类型。 2. 评估指标:使用多种评估指标来衡量RAG和长文本LLM的性能,包括准确率、召回率等。 3. 模型:评估了七个开源和四个专有LLM。 4. 实验设置:设计了多种实验设置,以比较RAG和长文本LLM在不同条件下的表现。
关键创新:LaRA基准测试的关键创新在于其全面性和严格性。它不仅涵盖了多种任务类型和文本类型,还考虑了多种因素对性能的影响。此外,LaRA还提供了一个统一的评估平台,方便研究人员进行比较和分析。
关键设计:LaRA的关键设计包括: 1. 任务选择:选择了四个实际QA任务类别,以确保基准测试的实用性。 2. 文本选择:选择了三种自然发生的文本类型,以确保基准测试的真实性。 3. 评估指标选择:选择了多种评估指标,以全面衡量RAG和长文本LLM的性能。 4. 模型选择:选择了多个开源和专有LLM,以确保基准测试的代表性。
🖼️ 关键图片
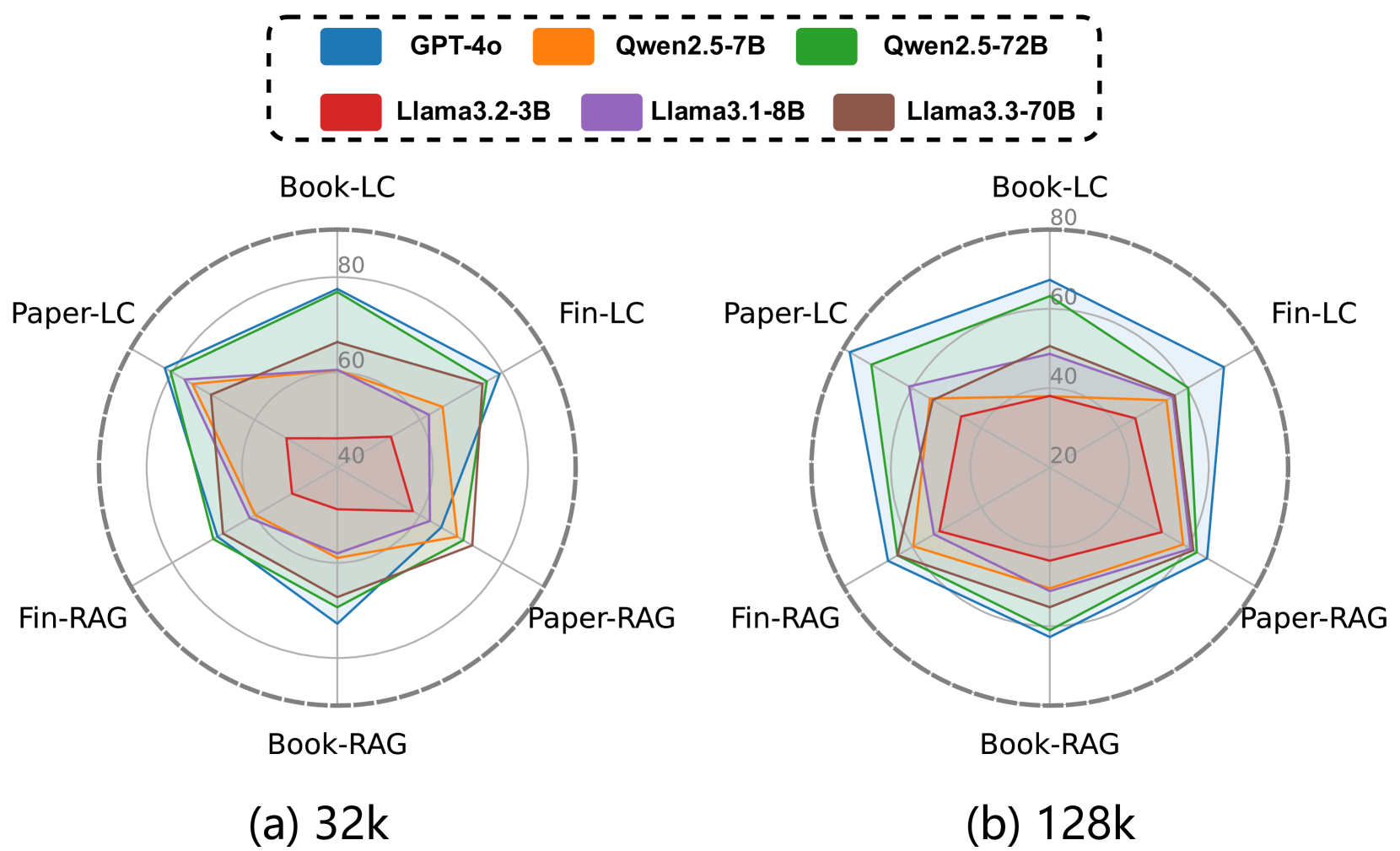
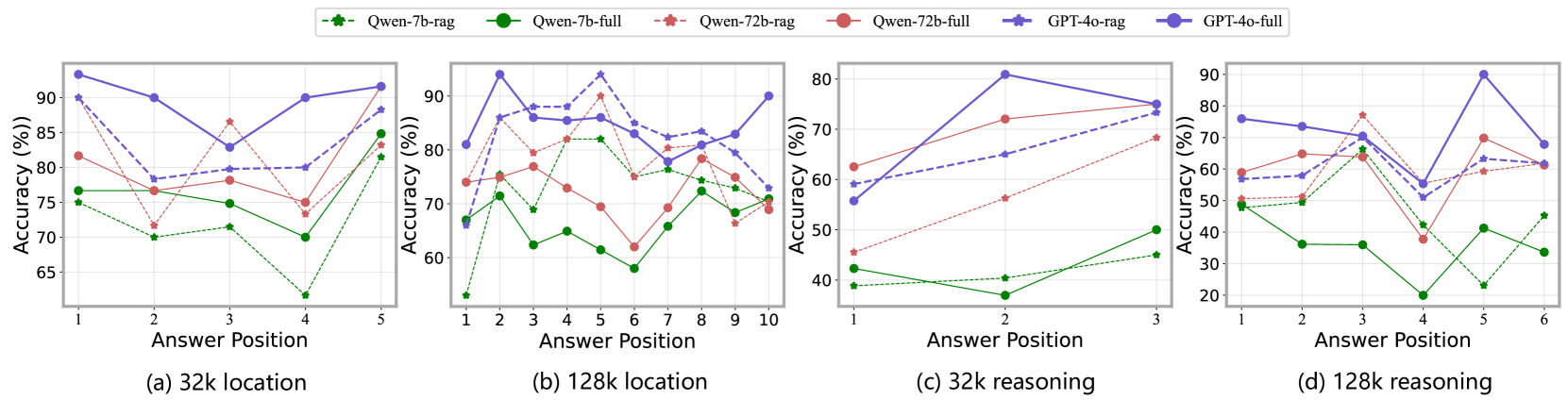
📊 实验亮点
LaRA基准测试的实验结果表明,RAG和长文本LLM的选择取决于多种因素的复杂交互,包括模型的参数大小、长文本能力、上下文长度、任务类型和检索块的特征。没有一种方法是万能的,需要根据具体情况进行选择。该研究为从业者提供了有效的指导,以在开发和部署LLM应用程序中有效地利用RAG和长文本方法。
🎯 应用场景
该研究成果可应用于各种需要利用外部知识增强LLM能力的场景,例如智能问答、文档摘要、知识库构建等。通过LaRA基准测试,开发者可以更好地选择和配置RAG和长文本LLM,从而提高LLM应用的性能和效率。该研究还有助于推动RAG和长文本LLM技术的发展。
📄 摘要(原文)
Effectively incorporating external knowledge into Large Language Models (LLMs) is crucial for enhancing their capabilities and addressing real-world needs. Retrieval-Augmented Generation (RAG) offers an effective method for achieving this by retrieving the most relevant fragments into LLMs. However, the advancements in context window size for LLMs offer an alternative approach, raising the question of whether RAG remains necessary for effectively handling external knowledge. Several existing studies provide inconclusive comparisons between RAG and long-context (LC) LLMs, largely due to limitations in the benchmark designs. In this paper, we present LaRA, a novel benchmark specifically designed to rigorously compare RAG and LC LLMs. LaRA encompasses 2326 test cases across four practical QA task categories and three types of naturally occurring long texts. Through systematic evaluation of seven open-source and four proprietary LLMs, we find that the optimal choice between RAG and LC depends on a complex interplay of factors, including the model's parameter size, long-text capabilities, context length, task type, and the characteristics of the retrieved chunks. Our findings provide actionable guidelines for practitioners to effectively leverage both RAG and LC approaches in developing and deploying LLM applications. Our code and dataset is provided at: \href{https://github.com/Alibaba-NLP/LaRA}{\textbf{https://github.com/Alibaba-NLP/LaRA}}.