KGGen: Extracting Knowledge Graphs from Plain Text with Language Models
作者: Belinda Mo, Kyssen Yu, Joshua Kazdan, Joan Cabezas, Proud Mpala, Lisa Yu, Chris Cundy, Charilaos Kanatsoulis, Sanmi Koyejo
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-02-14 (更新: 2025-11-06)
💡 一句话要点
KGGen:利用语言模型从纯文本中抽取高质量知识图谱,解决知识图谱数据稀缺问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱抽取 语言模型 实体聚类 文本到知识图谱 基准测试
📋 核心要点
- 现有知识图谱构建方法依赖人工标注或早期NLP技术,导致高质量知识图谱数据稀缺。
- KGGen利用语言模型从纯文本中生成知识图谱,并通过实体聚类降低图谱稀疏性。
- KGGen在MINE基准测试中表现出色,显著优于现有知识图谱抽取工具。
📝 摘要(中文)
构建知识图谱基础模型的需求日益增长,但面临着知识图谱数据相对稀缺的根本挑战。现有的知识图谱主要由人工标注、模式匹配或早期自然语言处理技术提取而来。人工生成的知识图谱供应不足,而自动提取的知识图谱质量存疑。为了解决这一数据稀缺问题,我们提出了一个文本到知识图谱生成器(KGGen),该工具包利用语言模型从纯文本中创建高质量的图谱。与其他知识图谱抽取器不同,KGGen对相关实体进行聚类,以减少抽取出的知识图谱中的稀疏性。KGGen以Python库( exttt{pip install kg-gen})的形式提供,方便用户使用。此外,我们还发布了首个基准测试,节点和边信息度量(MINE),用于评估抽取器从纯文本生成有用知识图谱的能力。我们将KGGen与现有抽取器进行了基准测试,结果表明KGGen的性能远超其他工具。
🔬 方法详解
问题定义:论文旨在解决知识图谱数据稀缺的问题,特别是高质量知识图谱的获取。现有方法,如人工标注成本高昂,模式匹配泛化能力弱,早期NLP技术准确率有限,导致自动提取的知识图谱质量不高,难以满足知识图谱基础模型的需求。
核心思路:论文的核心思路是利用预训练语言模型强大的文本理解和生成能力,直接从纯文本中抽取知识图谱。通过语言模型识别实体和关系,并进行实体聚类,从而构建高质量且稠密的知识图谱。这种方法避免了对人工标注数据的依赖,并能从海量文本数据中挖掘知识。
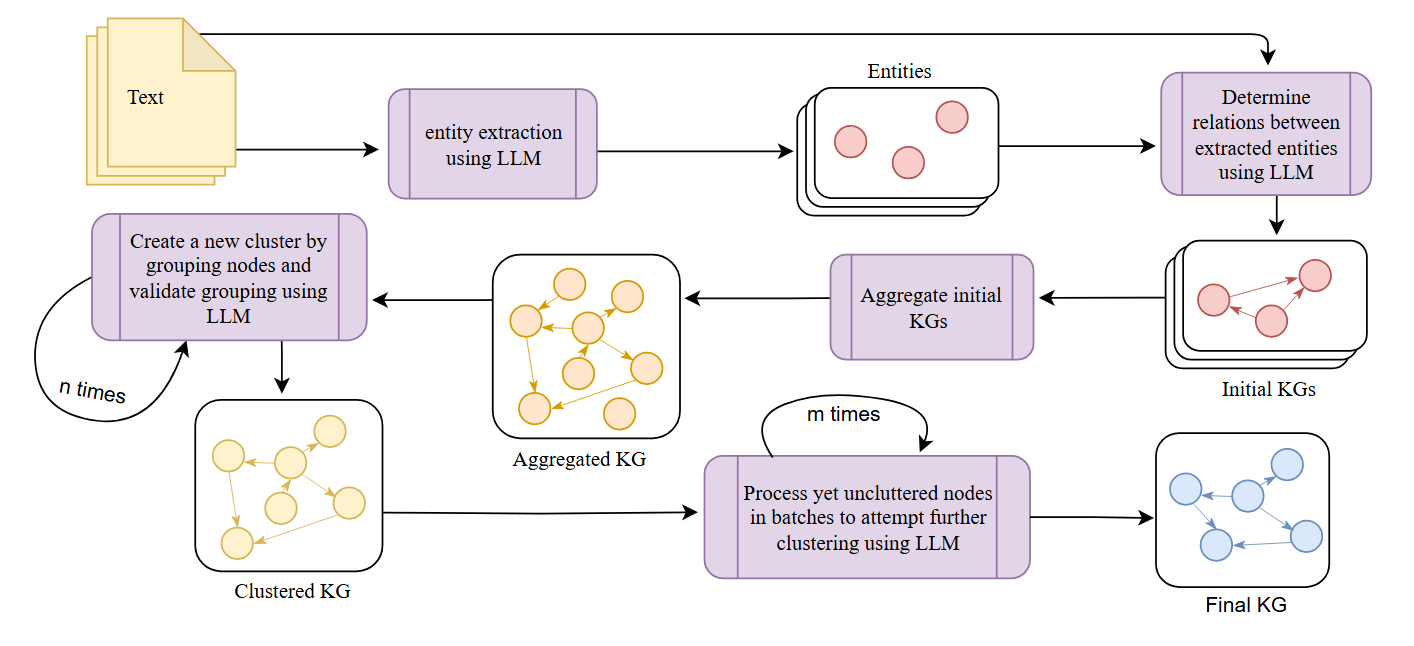
技术框架:KGGen的整体框架包含以下几个主要模块:1) 实体识别:利用语言模型识别文本中的实体;2) 关系抽取:利用语言模型抽取实体之间的关系;3) 实体聚类:将语义相关的实体进行聚类,减少图谱的稀疏性;4) 图谱构建:将抽取出的实体和关系构建成知识图谱。整个流程以纯文本作为输入,输出高质量的知识图谱。
关键创新:KGGen的关键创新在于结合了语言模型和实体聚类技术。语言模型能够准确地识别实体和关系,而实体聚类能够将语义相关的实体合并,从而减少图谱的稀疏性,提高图谱的质量。此外,KGGen还提出了一个新的基准测试MINE,用于评估知识图谱抽取器的性能。与现有方法相比,KGGen能够更有效地从纯文本中抽取高质量的知识图谱。
关键设计:KGGen的具体实现细节未知,摘要中没有详细说明语言模型的选择、实体聚类的算法、损失函数的设计等。这些细节可能在论文正文中有所描述,但摘要中没有提及。
🖼️ 关键图片
📊 实验亮点
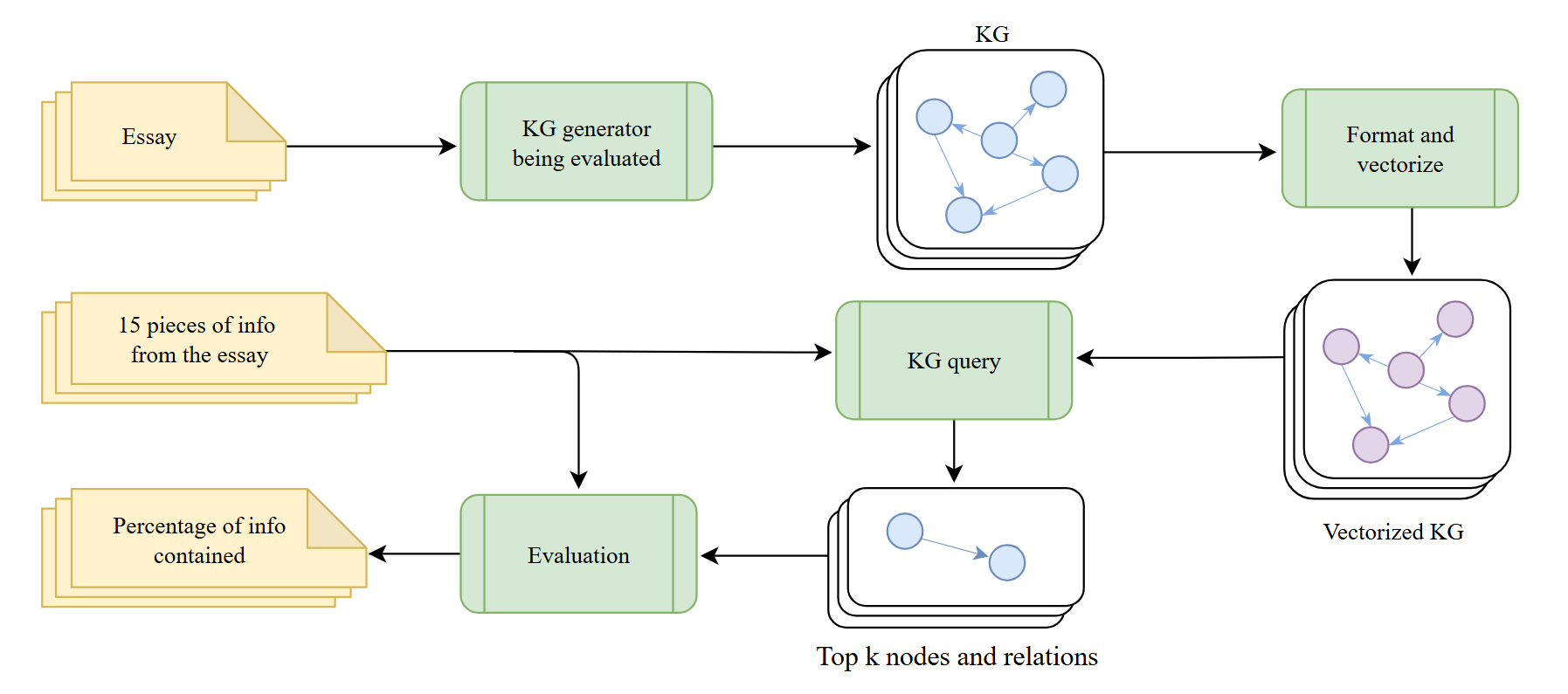
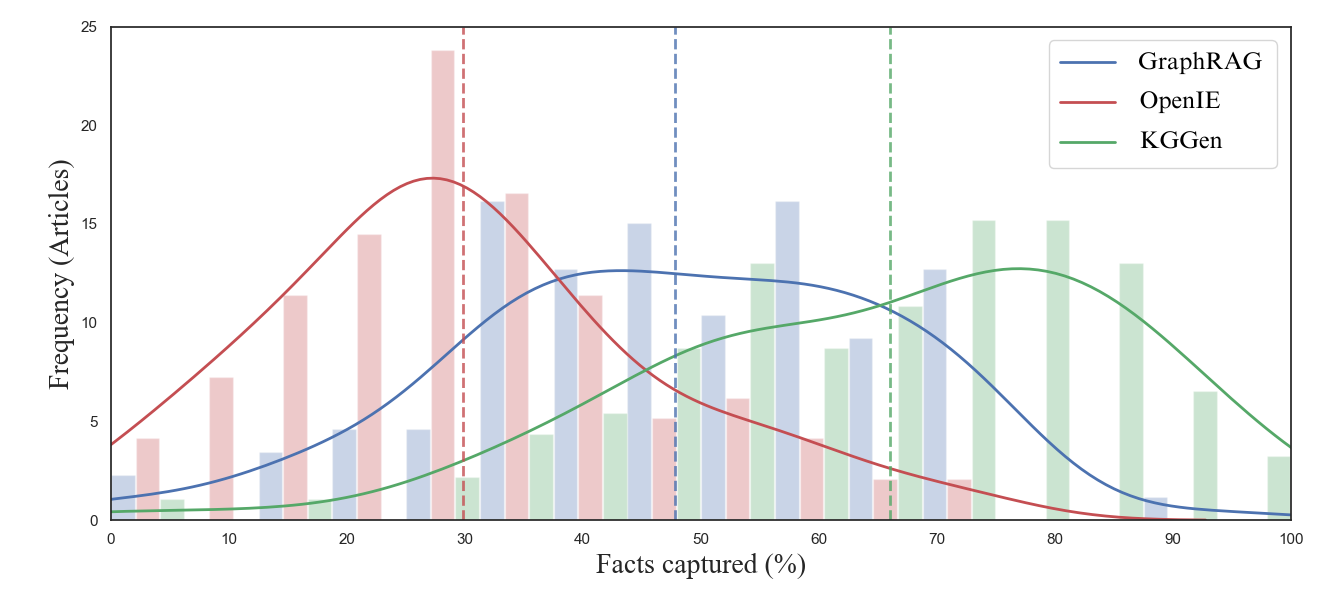
KGGen在MINE基准测试中表现出显著优势,表明其能够从纯文本中提取出比现有方法更高质量的知识图谱。具体的性能数据和提升幅度在摘要中没有给出,需要在论文正文中查找。但摘要明确指出KGGen的性能远超其他工具,证明了其有效性。
🎯 应用场景
KGGen可应用于多种场景,例如知识图谱构建、问答系统、信息检索、推荐系统等。通过从海量文本数据中自动抽取知识,KGGen可以构建大规模的知识图谱,为各种应用提供知识支持。该研究的潜在价值在于降低知识图谱构建的成本,提高知识图谱的质量,并促进知识图谱在各个领域的应用。
📄 摘要(原文)
Recent interest in building foundation models for KGs has highlighted a fundamental challenge: knowledge-graph data is relatively scarce. The best-known KGs are primarily human-labeled, created by pattern-matching, or extracted using early NLP techniques. While human-generated KGs are in short supply, automatically extracted KGs are of questionable quality. We present a solution to this data scarcity problem in the form of a text-to-KG generator (KGGen), a package that uses language models to create high-quality graphs from plaintext. Unlike other KG extractors, KGGen clusters related entities to reduce sparsity in extracted KGs. KGGen is available as a Python library (\texttt{pip install kg-gen}), making it accessible to everyone. Along with KGGen, we release the first benchmark, Measure of of Information in Nodes and Edges (MINE), that tests an extractor's ability to produce a useful KG from plain text. We benchmark our new tool against existing extractors and demonstrate far superior performance.