RefineCoder: Iterative Improving of Large Language Models via Adaptive Critique Refinement for Code Generation
作者: Changzhi Zhou, Xinyu Zhang, Dandan Song, Xiancai Chen, Wanli Gu, Huipeng Ma, Yuhang Tian, Mengdi Zhang, Linmei Hu
分类: cs.CL, cs.AI
发布日期: 2025-02-13 (更新: 2025-08-21)
💡 一句话要点
RefineCoder:通过自适应评价改进迭代提升大语言模型的代码生成能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 自适应评价改进 迭代学习 自监督学习
📋 核心要点
- 现有代码生成模型依赖于教师模型蒸馏,限制了模型性能,且忽略了自生成代码迭代改进的潜力。
- 提出自适应评价改进(ACR)方法,利用自生成代码和外部评价迭代提升模型性能,避免直接模仿教师模型。
- 通过迭代应用ACR构建RefineCoder系列,在多个代码生成基准测试中,使用更少数据达到可比甚至更优的性能。
📝 摘要(中文)
随着大型语言模型(LLMs)的兴起,代码生成受到了越来越多的关注。许多研究通过合成代码相关的指令数据并应用监督微调来开发强大的代码LLMs。然而,这些方法受到教师模型知识蒸馏的限制,并且忽略了通过自生成代码进行迭代改进的潜力。在本文中,我们提出了自适应评价改进(ACR),它使模型能够通过自生成的代码和外部评价来改进自身,而不是直接模仿教师模型的代码响应。具体而言,ACR包括一个使用LLM-as-a-Judge的综合评分系统来评估代码响应的质量,以及一个使用LLM-as-a-Critic的选择性评价策略来评价自生成的低质量代码响应。我们通过迭代应用ACR开发了RefineCoder系列,在多个代码生成基准测试中实现了持续的性能改进。与相同规模的基线相比,我们提出的RefineCoder系列可以使用更少的数据实现可比甚至更优越的性能。
🔬 方法详解
问题定义:现有代码生成模型主要依赖于监督微调,通过模仿教师模型生成代码。这种方法的痛点在于,模型的能力受到教师模型的限制,难以突破其性能上限。此外,现有方法忽略了模型自身生成代码并从中学习的潜力,无法充分利用自监督信息进行迭代改进。
核心思路:RefineCoder的核心思路是通过自适应评价改进(ACR)机制,让模型能够基于自身生成的代码和外部评价进行迭代学习和优化。模型不再仅仅是模仿教师模型,而是通过不断地生成、评价和改进代码,逐步提升自身的代码生成能力。这种方法类似于人类学习的过程,通过实践和反馈不断提升技能。
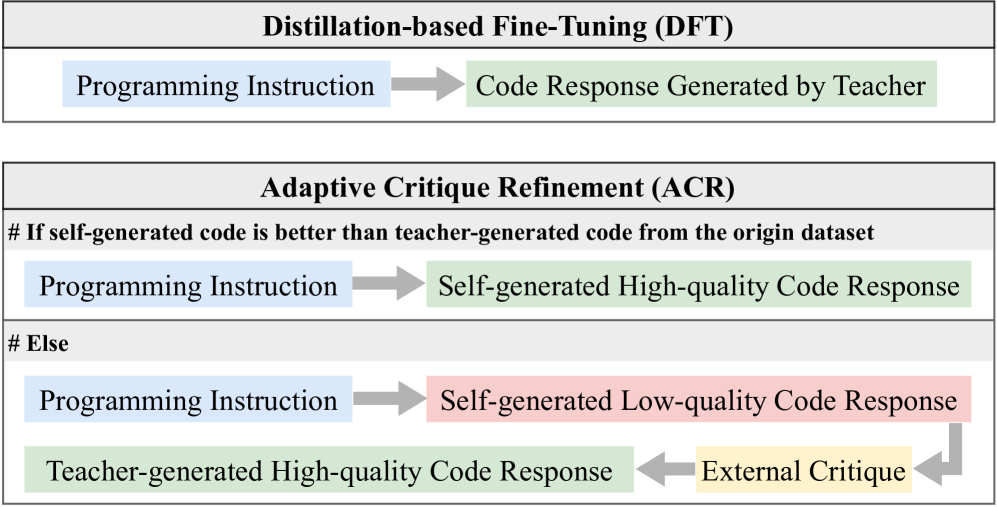
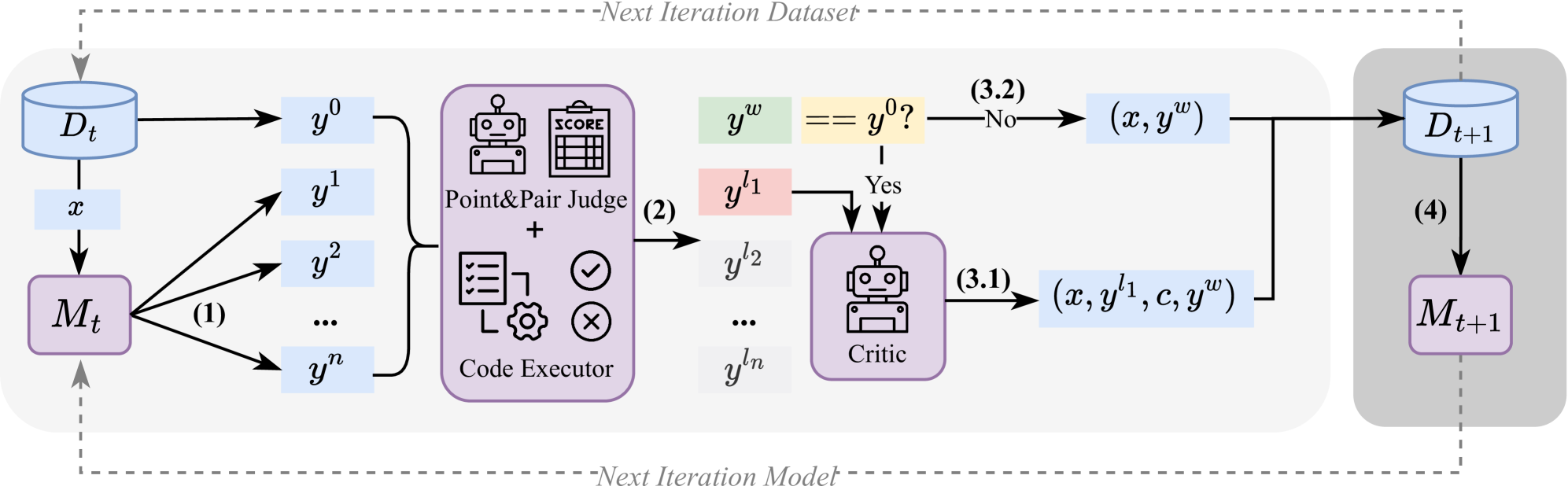
技术框架:RefineCoder的整体框架包含以下几个主要模块:1) 代码生成模块:使用LLM生成代码响应。2) 综合评分模块:使用LLM-as-a-Judge对生成的代码进行质量评估,形成综合评分。3) 选择性评价模块:使用LLM-as-a-Critic对低质量的代码响应进行评价,给出改进建议。4) 代码改进模块:基于评价结果,对代码进行迭代改进。整个流程迭代进行,不断提升代码质量。
关键创新:RefineCoder的关键创新在于自适应评价改进(ACR)机制。与传统的监督学习方法不同,ACR允许模型利用自身生成的代码进行学习,并结合外部评价进行指导。这种自监督和外部监督相结合的方式,能够更有效地提升模型的代码生成能力。此外,选择性评价策略能够集中精力改进低质量代码,提高学习效率。
关键设计:ACR的关键设计包括:1) LLM-as-a-Judge的综合评分系统,用于准确评估代码质量。评分标准可能包括代码的正确性、效率、可读性等方面。2) LLM-as-a-Critic的选择性评价策略,用于识别和评价低质量代码。评价策略需要能够给出具体的改进建议。3) 迭代改进的策略,需要设计合适的迭代次数和学习率,以保证模型能够稳定地提升性能。
🖼️ 关键图片

📊 实验亮点
RefineCoder在多个代码生成基准测试中取得了显著的性能提升。与相同规模的基线模型相比,RefineCoder可以使用更少的数据达到可比甚至更优越的性能。这表明ACR机制能够有效地利用自生成代码进行学习,并提升模型的代码生成能力。具体性能数据未知,但论文强调了在数据效率方面的优势。
🎯 应用场景
RefineCoder具有广泛的应用前景,可用于自动化软件开发、代码辅助生成、智能编程教育等领域。它可以帮助开发者更高效地编写代码,降低开发成本,并提高软件质量。此外,RefineCoder还可以作为智能编程助手,为初学者提供代码建议和错误诊断,辅助他们学习编程。
📄 摘要(原文)
Code generation has attracted increasing attention with the rise of Large Language Models (LLMs). Many studies have developed powerful code LLMs by synthesizing code-related instruction data and applying supervised fine-tuning. However, these methods are limited by teacher model distillation and ignore the potential of iterative refinement by self-generated code. In this paper, we propose Adaptive Critique Refinement (ACR), which enables the model to refine itself by self-generated code and external critique, rather than directly imitating the code responses of the teacher model. Concretely, ACR includes a composite scoring system with LLM-as-a-Judge to evaluate the quality of code responses and a selective critique strategy with LLM-as-a-Critic to critique self-generated low-quality code responses. We develop the RefineCoder series by iteratively applying ACR, achieving continuous performance improvement on multiple code generation benchmarks. Compared to the baselines of the same size, our proposed RefineCoder series can achieve comparable or even superior performance using less data.