CoSER: A Comprehensive Literary Dataset and Framework for Training and Evaluating LLM Role-Playing and Persona Simulation
作者: Xintao Wang, Heng Wang, Yifei Zhang, Xinfeng Yuan, Rui Xu, Jen-tse Huang, Siyu Yuan, Haoran Guo, Jiangjie Chen, Shuchang Zhou, Wei Wang, Yanghua Xiao
分类: cs.CL, cs.AI
发布日期: 2025-02-13 (更新: 2026-01-04)
备注: Accepted by ICML 2025
💡 一句话要点
CoSER:构建综合文学数据集与框架,用于训练和评估LLM的角色扮演和人物模拟能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 角色扮演 大型语言模型 数据集构建 人物模拟 情境表演
📋 核心要点
- 现有角色扮演语言智能体缺乏高质量、多样化的角色数据集,难以进行有效的训练和评估。
- CoSER通过构建包含大量角色的数据集,并引入给定情境表演方法,提升LLM的角色扮演能力。
- 实验结果表明,基于CoSER训练的LLM在角色扮演任务上表现出色,甚至超越了GPT-4o等先进模型。
📝 摘要(中文)
角色扮演语言智能体(RPLAs)已成为大型语言模型(LLMs)极具潜力的应用。然而,由于缺乏真实的角色数据集以及使用此类数据的细致评估方法,模拟已建立的角色对RPLAs来说是一项具有挑战性的任务。本文提出了CoSER,它包含高质量数据集、开放模型和评估协议,旨在实现有效的已建立角色RPLA。CoSER数据集涵盖了来自771本著名书籍的17,966个角色,提供了具有真实世界复杂性的真实对话,以及对话设置、角色经历和内心想法等多样的数据类型。借鉴表演方法,我们引入了给定情境表演,用于训练和评估角色扮演LLM,其中LLM按顺序描绘书籍场景中的多个角色。使用我们的数据集,我们开发了CoSER 8B和CoSER 70B,即基于LLaMA-3.1模型构建的先进的开放角色扮演LLM。大量实验证明了CoSER数据集在RPLA训练、评估和检索方面的价值。此外,CoSER 70B在我们的评估和三个现有基准测试中表现出最先进的性能,超过或匹配GPT-4o,即在InCharacter和LifeChoice基准测试中分别达到75.80%和93.47%的准确率。
🔬 方法详解
问题定义:现有角色扮演语言模型(RPLM)在模拟已建立的角色时面临挑战,主要痛点在于缺乏高质量、多样化的角色数据集,以及缺乏细致的评估方法。现有方法难以捕捉角色的细微差别和真实世界的复杂性,导致RPLM的表现不够逼真和自然。
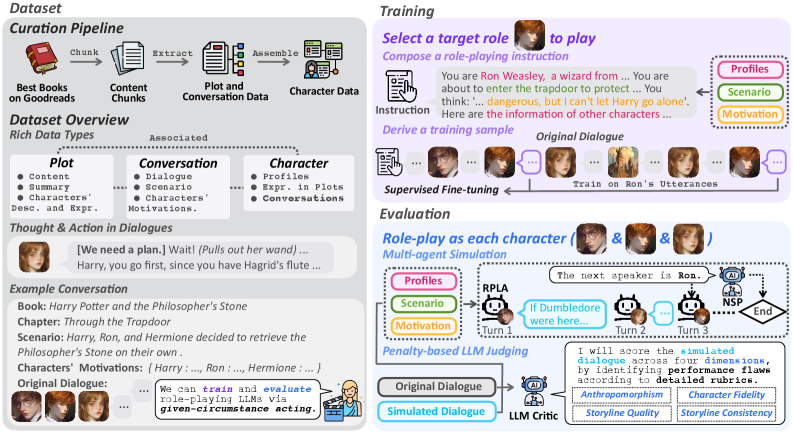
核心思路:CoSER的核心思路是构建一个大规模、高质量的角色扮演数据集,并结合表演方法中的“给定情境表演”来训练和评估LLM。通过提供丰富的角色信息和情境设置,使LLM能够更好地理解和模拟角色的行为和思维方式。
技术框架:CoSER框架主要包含三个部分:数据集构建、模型训练和评估。数据集构建阶段,从大量书籍中提取角色信息和对话,并进行清洗和标注。模型训练阶段,使用CoSER数据集训练LLM,并采用给定情境表演方法,让LLM按顺序扮演多个角色。评估阶段,使用CoSER数据集和现有基准测试评估LLM的角色扮演能力。
关键创新:CoSER的关键创新点在于:1) 构建了一个大规模、高质量的角色扮演数据集,包含丰富的角色信息和情境设置;2) 引入了给定情境表演方法,使LLM能够更好地理解和模拟角色的行为和思维方式;3) 开发了CoSER 8B和CoSER 70B,即基于LLaMA-3.1模型构建的先进的开放角色扮演LLM。
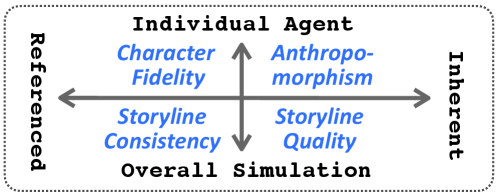
关键设计:CoSER数据集包含对话设置、角色经历和内心想法等多种数据类型,以提供更全面的角色信息。给定情境表演方法要求LLM按顺序扮演多个角色,并根据情境的变化调整角色的行为和思维方式。CoSER 8B和CoSER 70B模型基于LLaMA-3.1模型进行微调,并采用了特定的训练策略,以提高角色扮演能力。具体参数设置和损失函数等细节未知。
🖼️ 关键图片

📊 实验亮点
CoSER 70B在CoSER评估和三个现有基准测试中表现出最先进的性能,超过或匹配GPT-4o。具体而言,在InCharacter和LifeChoice基准测试中,CoSER 70B分别达到了75.80%和93.47%的准确率,显著优于其他基线模型,证明了CoSER数据集和训练方法的有效性。
🎯 应用场景
CoSER的研究成果可广泛应用于游戏开发、虚拟助手、教育娱乐等领域。通过提供更逼真、更自然的角色扮演体验,可以提升用户在这些应用中的沉浸感和互动性。未来,CoSER有望推动角色扮演语言智能体的进一步发展,并为相关领域带来更多创新应用。
📄 摘要(原文)
Role-playing language agents (RPLAs) have emerged as promising applications of large language models (LLMs). However, simulating established characters presents a challenging task for RPLAs, due to the lack of authentic character datasets and nuanced evaluation methods using such data. In this paper, we present CoSER, a collection of a high-quality dataset, open models, and an evaluation protocol towards effective RPLAs of established characters. The CoSER dataset covers 17,966 characters from 771 renowned books. It provides authentic dialogues with real-world intricacies, as well as diverse data types such as conversation setups, character experiences and internal thoughts. Drawing from acting methodology, we introduce given-circumstance acting for training and evaluating role-playing LLMs, where LLMs sequentially portray multiple characters in book scenes. Using our dataset, we develop CoSER 8B and CoSER 70B, i.e., advanced open role-playing LLMs built on LLaMA-3.1 models. Extensive experiments demonstrate the value of the CoSER dataset for RPLA training, evaluation and retrieval. Moreover, CoSER 70B exhibits state-of-the-art performance surpassing or matching GPT-4o on our evaluation and three existing benchmarks, i.e., achieving 75.80% and 93.47% accuracy on the InCharacter and LifeChoice benchmarks respectively.