Enhancing RAG with Active Learning on Conversation Records: Reject Incapables and Answer Capables
作者: Xuzhao Geng, Haozhao Wang, Jun Wang, Wei Liu, Ruixuan Li
分类: cs.CL
发布日期: 2025-02-13
💡 一句话要点
提出AL4RAG,通过主动学习提升RAG在对话记录上的抗幻觉能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 主动学习 幻觉抑制 对话系统 样本选择
📋 核心要点
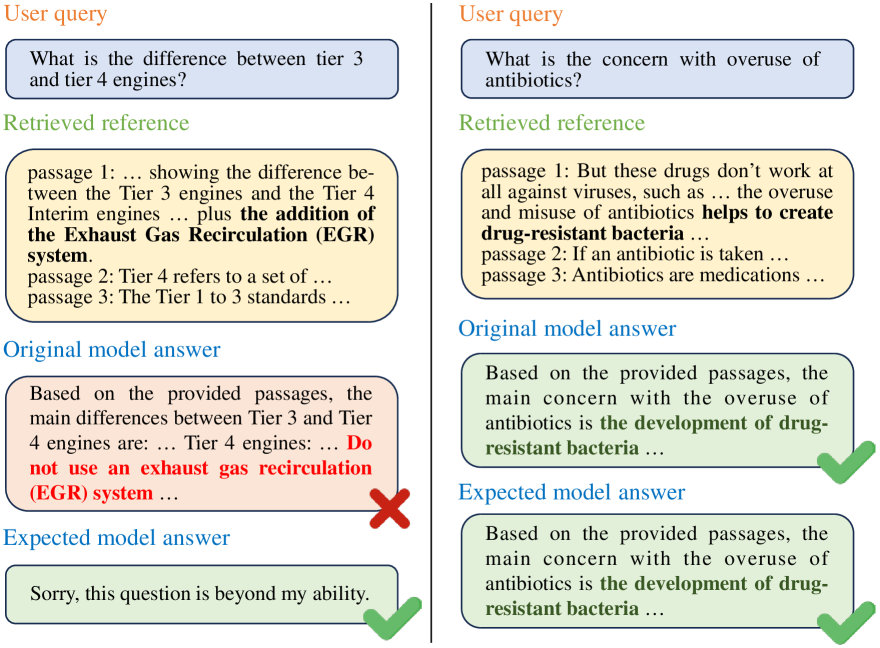
- RAG技术虽能利用外部知识,但仍存在幻觉问题,需要高质量数据集来训练模型避免。
- AL4RAG利用主动学习从海量对话记录中筛选最具价值的样本进行标注,降低标注成本。
- 针对RAG的特殊性,设计了新的样本距离度量方法,提升了主动学习的性能。
📝 摘要(中文)
检索增强生成(RAG)是利用外部知识并减少大型语言模型(LLM)幻觉的关键技术。然而,RAG仍然难以完全避免幻觉响应。为了解决这个问题,识别容易产生幻觉的样本或引导LLM给出正确的响应至关重要,专家可以标注这些样本,从而开发高质量的数据集来改进LLM。然而,此类数据集日益稀缺,使得创建它们充满挑战。本文提出利用LLM广泛使用中产生的大量对话来构建这些数据集,训练LLM避免容易产生幻觉的问题,同时准确回答可管理的问题。考虑到专家标注所有对话记录是不切实际的,本文引入了AL4RAG,它使用主动学习来选择最适合标注的对话样本,从而在标注预算内优化性能。此外,由于传统的积极学习方法由于不合适的距离度量而与RAG不完全兼容,我们为RAG主动学习开发了一种新的样本距离度量。大量实验表明,我们的方法在多个指标上始终优于基线。
🔬 方法详解
问题定义:RAG在实际应用中,尤其是在对话场景下,仍然存在生成幻觉的问题。现有方法依赖于大量人工标注数据来训练模型,以减少幻觉。然而,获取高质量的标注数据成本高昂,特别是对于长尾和复杂的对话场景。传统的RAG主动学习方法采用的距离度量不适用于RAG的特性,导致样本选择效率不高。
核心思路:本文的核心思路是利用主动学习,从大量的LLM对话记录中选择最具信息量的样本进行标注,从而在有限的标注预算下,最大程度地提升RAG模型的抗幻觉能力。通过训练模型区分并拒绝容易产生幻觉的问题,同时准确回答可处理的问题,从而提高RAG的整体性能。
技术框架:AL4RAG框架主要包含以下几个阶段:1) 从LLM对话记录中收集大量的对话样本。2) 使用设计的样本距离度量方法计算样本之间的距离。3) 利用主动学习算法,根据样本距离和模型预测的不确定性,选择一批最具价值的样本进行人工标注。4) 使用标注后的数据训练RAG模型,提升其抗幻觉能力。5) 重复步骤2-4,直到达到标注预算或模型性能收敛。
关键创新:本文的关键创新在于提出了一个针对RAG的主动学习框架AL4RAG,并设计了一种新的样本距离度量方法。该距离度量方法考虑了RAG的特殊性,能够更准确地评估样本之间的相似性和差异性,从而提高主动学习的样本选择效率。
关键设计:样本距离度量方法是AL4RAG的关键。具体来说,该方法可能结合了语义相似度、模型预测置信度、以及检索到的文档的相关性等因素。损失函数的设计可能包括一个分类损失,用于区分可回答和不可回答的问题,以及一个生成损失,用于优化RAG模型的生成质量。具体的网络结构细节未知,但可以推测使用了Transformer架构,并针对RAG进行了优化。
🖼️ 关键图片

📊 实验亮点
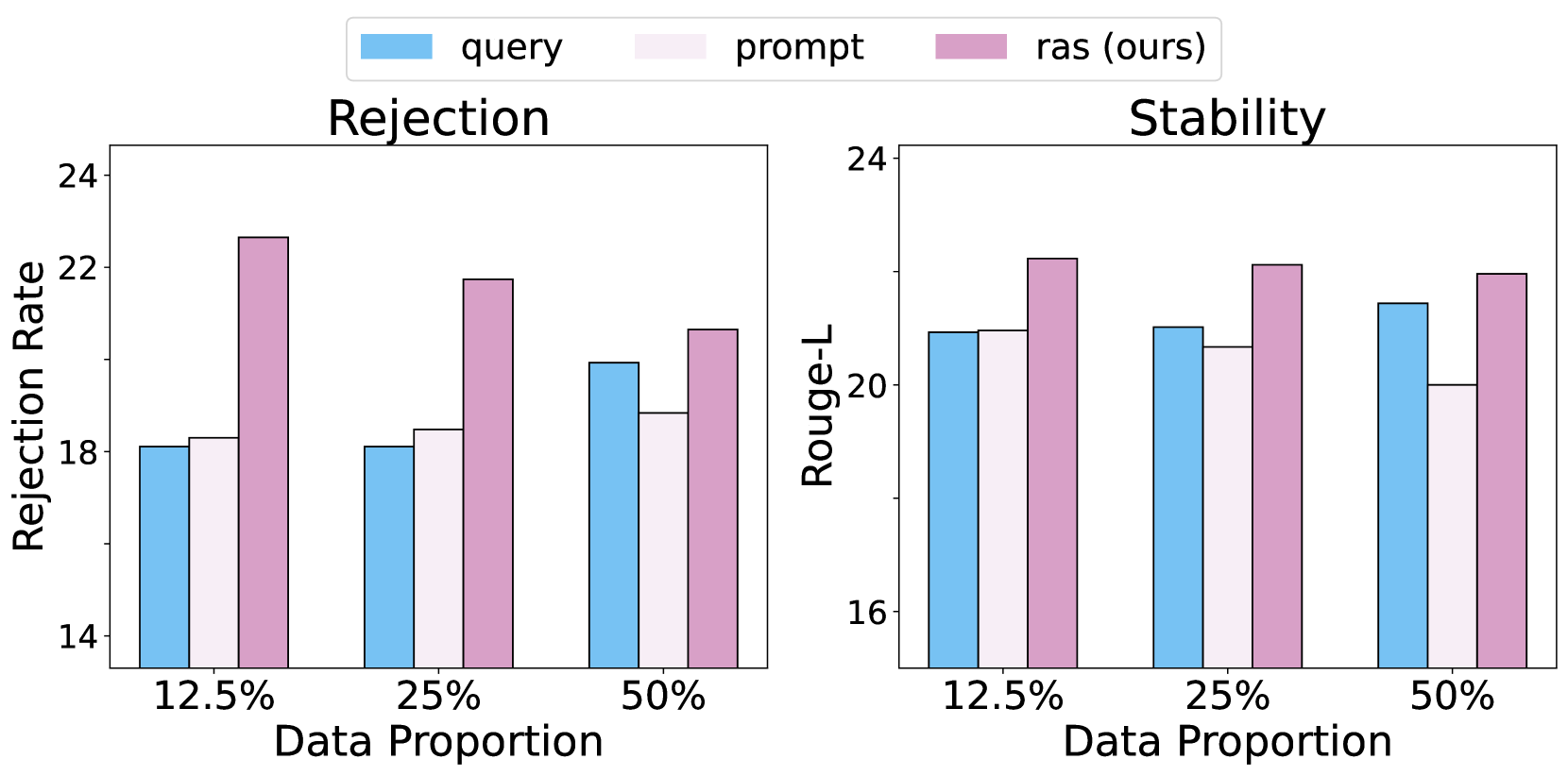
实验结果表明,AL4RAG在多个指标上显著优于基线方法。具体的性能数据未知,但可以推断,AL4RAG在相同标注预算下,能够获得更高的模型准确率和更低的幻觉率。通过对比实验,验证了所提出的样本距离度量方法的有效性,以及主动学习策略的优越性。
🎯 应用场景
该研究成果可应用于各种基于LLM的对话系统,例如智能客服、聊天机器人等。通过主动学习和高质量数据标注,可以显著提升这些系统在复杂对话场景下的可靠性和准确性,减少幻觉的产生,从而提高用户体验和信任度。未来,该方法还可以扩展到其他RAG应用场景,例如知识库问答、文档摘要等。
📄 摘要(原文)
Retrieval-augmented generation (RAG) is a key technique for leveraging external knowledge and reducing hallucinations in large language models (LLMs). However, RAG still struggles to fully prevent hallucinated responses. To address this, it is essential to identify samples prone to hallucination or guide LLMs toward correct responses, which experts then annotate to develop high-quality datasets for refining LLMs. However, the growing scarcity of such datasets makes their creation challenging. This paper proposes using the vast amount of conversations from widespread LLM usage to build these datasets, training LLMs to avoid hallucination-prone questions while accurately responding to manageable ones. Given the impracticality of expert-annotating all conversation records, the paper introduces AL4RAG, which uses active learning to select the most suitable conversation samples for annotation, optimizing performance within an annotation budget. Additionally, recognizing that traditional active learning methods are not fully compatible with RAG due to unsuitable distance metrics, we develop a novel sample distance measurement for RAG active learning. Extensive experiments show that our method consistently outperforms baselines across multiple metrics.