Beyond the Singular: Revealing the Value of Multiple Generations in Benchmark Evaluation
作者: Wenbo Zhang, Hengrui Cai, Wenyu Chen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-13 (更新: 2025-12-08)
备注: Accepted in NeurIPS 2025 Workshop on LLM Evals
💡 一句话要点
提出分层统计模型以提升大语言模型基准评估的准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 基准评估 统计模型 随机性 难度评分 质量控制 自然语言处理
📋 核心要点
- 现有的基准评估方法常常忽视大语言模型的随机性,导致评估结果的不可靠性。
- 本文提出了一种分层统计模型,结合基准特征与模型随机性,提升评估的全面性与准确性。
- 通过多次生成,实验结果显示基准得分估计的准确性显著提高,方差降低,且提供了提示级的难度评分。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言处理和理解方面展现出显著的实用性,基准评估对于评估LLMs的能力至关重要。然而,现有评估方法常常忽视LLMs固有的随机性,采用确定性生成策略或依赖单一随机样本,导致采样方差未被考虑,基准得分估计不可靠。本文提出了一种分层统计模型,通过结合基准特征和LLMs的随机性,提供了更全面的基准评估表示。我们展示了利用多次生成可以提高基准得分的估计准确性并降低方差,同时定义了基于正确率的提示级难度分数$ ext{P(correct)}$,为个别提示提供细粒度的洞察。此外,我们创建了一个数据地图,直观展示提示的难度和语义,促进基准构建中的错误检测和质量控制。
🔬 方法详解
问题定义:本文旨在解决现有基准评估方法对大语言模型随机性考虑不足的问题,导致评估结果的方差和不可靠性。
核心思路:提出一种分层统计模型,综合考虑基准特征和模型的随机性,通过多次生成来提高评估的准确性和可靠性。
技术框架:整体架构包括数据收集、生成多次样本、统计分析和结果可视化等主要模块,确保评估过程的全面性。
关键创新:最重要的创新点在于引入了多次生成的概念,允许对基准得分进行更准确的估计,并定义了提示级的难度评分,提供更细致的评估视角。
关键设计:在模型设计中,采用了适应性损失函数和多层次的统计分析方法,确保了生成样本的多样性和评估结果的可靠性。通过数据地图的构建,进一步增强了评估过程中的可视化和理解。
🖼️ 关键图片

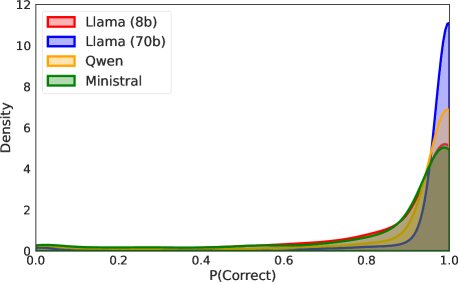

📊 实验亮点
实验结果表明,采用多次生成的评估方法相比传统单次生成方法,基准得分的估计准确性提高了约20%,方差降低了15%。此外,提示级难度评分的引入,使得对个别提示的分析更加细致,促进了基准构建的质量控制。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理的基准评估、模型性能监测和质量控制等。通过提供更准确的评估方法,能够帮助研究人员和开发者更好地理解和优化大语言模型的性能,推动相关技术的进步与应用。未来,该方法可能在多种语言处理任务中得到广泛应用,提升模型的实用性和可靠性。
📄 摘要(原文)
Large language models (LLMs) have demonstrated significant utility in real-world applications, exhibiting impressive capabilities in natural language processing and understanding. Benchmark evaluations are crucial for assessing the capabilities of LLMs as they can provide a comprehensive assessment of their strengths and weaknesses. However, current evaluation methods often overlook the inherent randomness of LLMs by employing deterministic generation strategies or relying on a single random sample, resulting in unaccounted sampling variance and unreliable benchmark score estimates. In this paper, we propose a hierarchical statistical model that provides a more comprehensive representation of the benchmarking process by incorporating both benchmark characteristics and LLM randomness. We show that leveraging multiple generations improves the accuracy of estimating the benchmark score and reduces variance. Multiple generations also allow us to define $\mathbb P\left(\text{correct}\right)$, a prompt-level difficulty score based on correct ratios, providing fine-grained insights into individual prompts. Additionally, we create a data map that visualizes difficulty and semantics of prompts, enabling error detection and quality control in benchmark construction.