The Science of Evaluating Foundation Models
作者: Jiayi Yuan, Jiamu Zhang, Andrew Wen, Xia Hu
分类: cs.CL, cs.AI
发布日期: 2025-02-12
💡 一句话要点
构建评估框架以应对大型模型在多样化应用中的挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型评估 评估框架 伦理考量 可操作性 可重复性
📋 核心要点
- 现有评估方法未能将多样化用例与伦理、操作因素整合,缺乏统一的评估流程。
- 论文提出结构化评估框架,提供清单和模板等工具,确保评估彻底、可重复且实用。
- 论文调研了LLM评估的最新进展,重点关注实际应用,为模型评估提供参考。
📝 摘要(中文)
大型预训练模型(Foundation Models)的涌现彻底改变了自然语言处理领域。然而,由于这些模型规模庞大、能力多样以及在各种应用中的部署,评估它们面临着巨大的挑战。现有的文献通常侧重于单个方面,例如基准性能或特定任务,但未能提供一个连贯的过程,将不同用例的细微差别与更广泛的伦理和操作考虑因素相结合。本文侧重于三个关键方面:(1)形式化评估过程,提供针对特定用例上下文量身定制的结构化框架;(2)提供可操作的工具和框架,例如清单和模板,以确保彻底、可重复和实用的评估;(3)通过对LLM评估进展的有针对性的回顾,强调实际应用,来调研最近的工作。
🔬 方法详解
问题定义:论文旨在解决大型预训练模型(LLM)评估中存在的挑战。现有方法通常只关注模型在特定基准测试上的性能,而忽略了模型在实际应用中的表现,以及伦理和社会影响。此外,缺乏一个统一的、结构化的评估流程,使得模型评估难以复现和比较。
核心思路:论文的核心思路是构建一个全面的、可操作的评估框架,该框架能够考虑到模型在不同用例中的表现,以及伦理和社会影响。该框架包括形式化的评估流程、可操作的工具和框架(如清单和模板),以及对LLM评估最新进展的调研。通过该框架,可以更全面、更准确地评估LLM的性能和风险。
技术框架:论文提出的评估框架主要包括以下几个阶段:1. 定义评估目标:明确评估的目的和范围,例如评估模型在特定任务上的性能、评估模型的伦理风险等。2. 选择评估指标:选择合适的评估指标来衡量模型的性能和风险,例如准确率、召回率、公平性指标等。3. 构建评估数据集:构建能够代表实际应用场景的评估数据集。4. 执行评估:使用选定的评估指标和数据集来评估模型的性能和风险。5. 分析评估结果:分析评估结果,识别模型的优点和缺点,以及潜在的风险。6. 改进模型:根据评估结果,对模型进行改进,例如调整模型参数、修改模型结构等。
关键创新:论文的关键创新在于提出了一个全面的、可操作的评估框架,该框架能够考虑到模型在不同用例中的表现,以及伦理和社会影响。该框架不仅包括形式化的评估流程,还提供了可操作的工具和框架(如清单和模板),使得模型评估更加容易复现和比较。
关键设计:论文中提出的评估框架的关键设计包括:1. 针对特定用例上下文量身定制的结构化评估流程。2. 提供可操作的工具和框架(如清单和模板),以确保评估彻底、可重复和实用。3. 对LLM评估最新进展的调研,重点关注实际应用。
🖼️ 关键图片

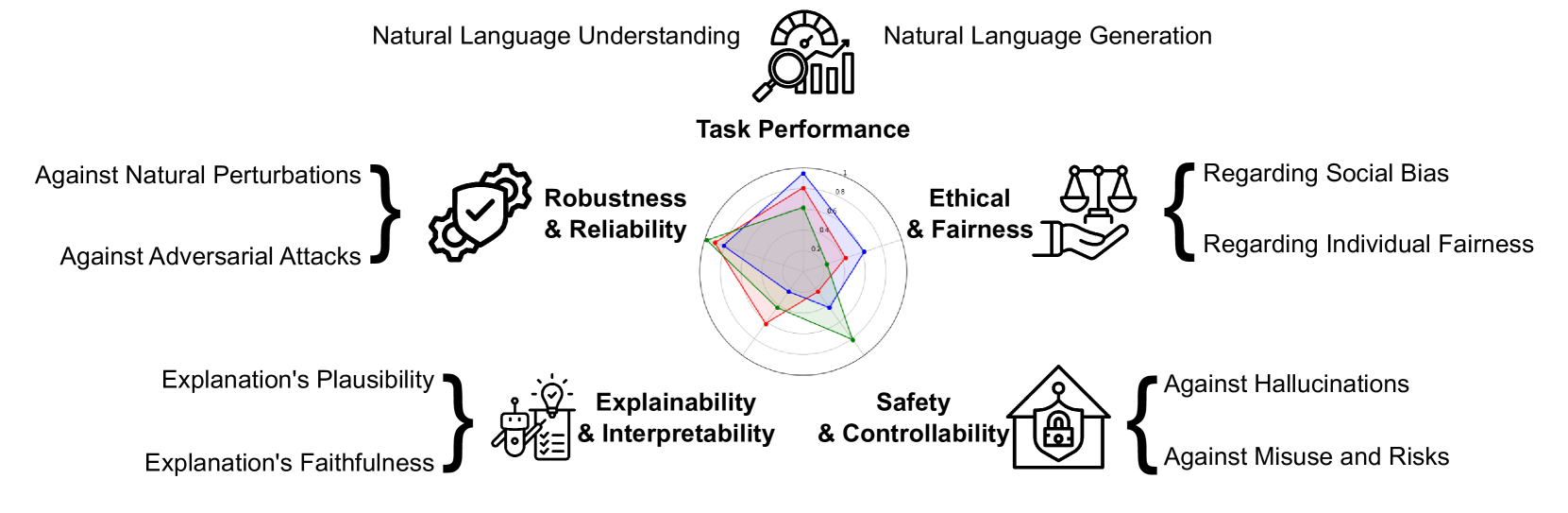
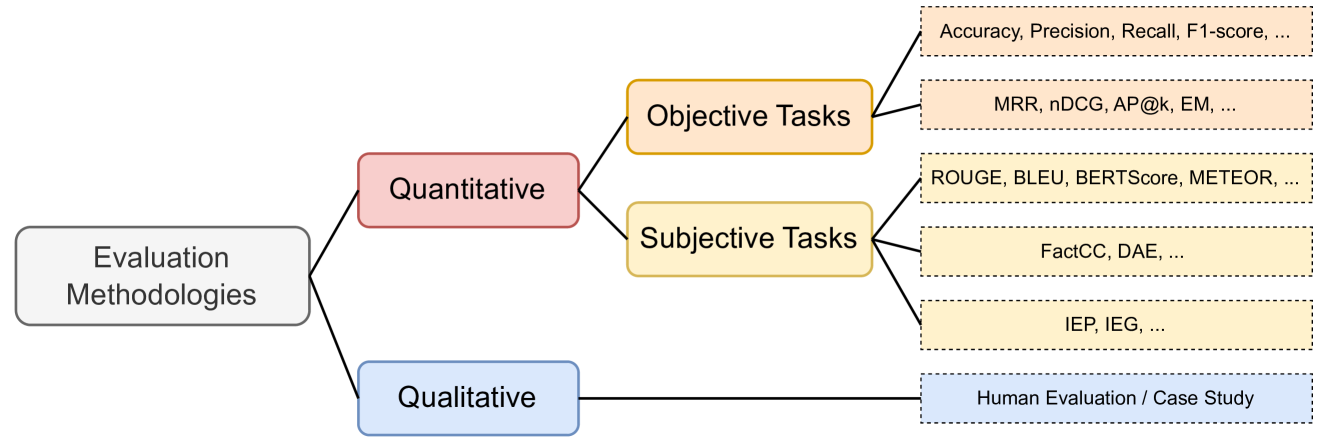
📊 实验亮点
论文重点在于框架的构建和流程的规范化,而非具体的实验结果。其亮点在于提供了一套可操作的评估工具和流程,能够帮助研究人员和开发者更系统地评估大型语言模型,并考虑到伦理和社会影响。通过清单和模板等工具,可以提高评估的可重复性和实用性。
🎯 应用场景
该研究成果可应用于各种需要评估大型预训练模型的场景,例如自然语言处理、机器翻译、文本生成等。该框架可以帮助开发者和研究人员更全面、更准确地评估模型的性能和风险,从而开发出更可靠、更安全的AI系统。此外,该框架还可以促进LLM评估领域的标准化和规范化。
📄 摘要(原文)
The emergent phenomena of large foundation models have revolutionized natural language processing. However, evaluating these models presents significant challenges due to their size, capabilities, and deployment across diverse applications. Existing literature often focuses on individual aspects, such as benchmark performance or specific tasks, but fails to provide a cohesive process that integrates the nuances of diverse use cases with broader ethical and operational considerations. This work focuses on three key aspects: (1) Formalizing the Evaluation Process by providing a structured framework tailored to specific use-case contexts, (2) Offering Actionable Tools and Frameworks such as checklists and templates to ensure thorough, reproducible, and practical evaluations, and (3) Surveying Recent Work with a targeted review of advancements in LLM evaluation, emphasizing real-world applications.