From Haystack to Needle: Label Space Reduction for Zero-shot Classification
作者: Nathan Vandemoortele, Bram Steenwinckel, Femke Ongenae, Sofie Van Hoecke
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-12 (更新: 2025-11-05)
备注: Add acknowledgment
💡 一句话要点
提出标签空间缩减方法以提升零样本分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本分类 标签空间缩减 大型语言模型 统计学习 模型蒸馏
📋 核心要点
- 现有的零样本分类方法在处理大量候选类别时,容易导致性能下降,尤其是在标签空间庞大时。
- 标签空间缩减(LSR)通过迭代优化候选类别,帮助模型聚焦于最相关的标签,从而提升分类性能。
- 实验结果显示,LSR在多个基准测试中显著提高了宏F1分数,证明了其有效性和实用性。
📝 摘要(中文)
我们提出了一种新颖的方法——标签空间缩减(LSR),旨在提升大型语言模型(LLMs)在零样本分类中的表现。LSR通过系统性地对候选类别进行排名和减少,迭代地优化分类标签空间,使模型能够集中关注最相关的选项。通过利用未标记数据和数据驱动模型的统计学习能力,LSR在测试时动态优化标签空间表示。我们的实验在七个基准测试中表明,LSR在Llama-3.1-70B上平均提升宏F1分数7.0%(最高可达14.2%),在Claude-3.5-Sonnet上提升3.3%(最高可达11.1%),相较于标准的零样本分类基线。为了降低LSR的计算开销,我们提出将模型蒸馏为概率分类器,从而实现高效推理。
🔬 方法详解
问题定义:当前的零样本分类方法在面对庞大的标签空间时,往往无法有效区分相关和不相关的类别,导致分类性能下降。
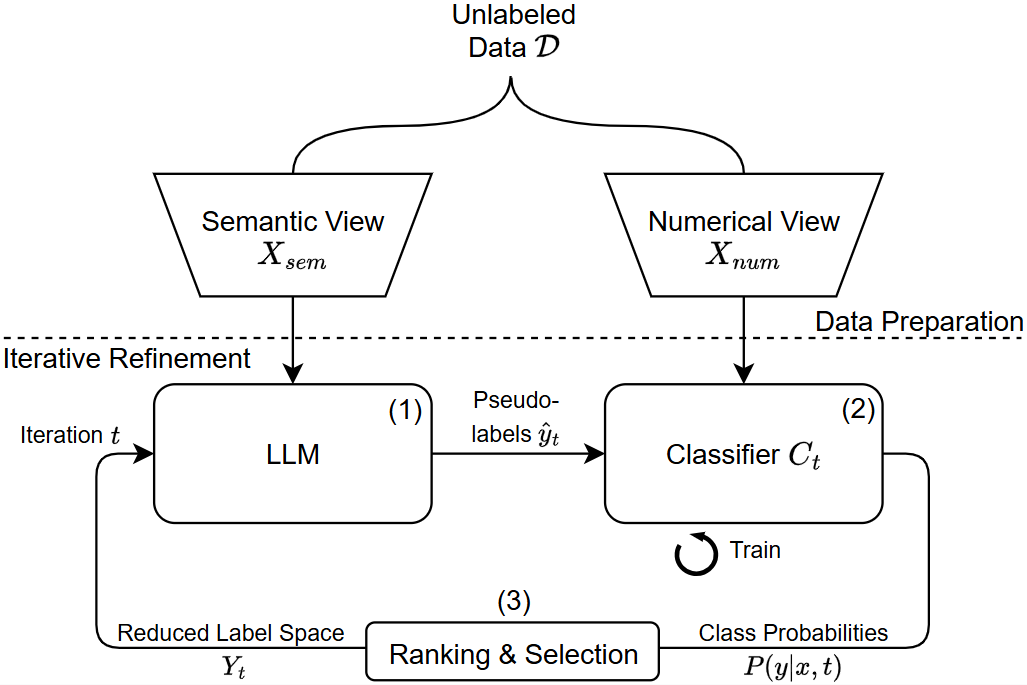
核心思路:标签空间缩减(LSR)通过迭代地对候选类别进行排名和减少,优化模型的标签空间,使其能够更专注于最相关的选项,从而提升分类效果。
技术框架:LSR的整体架构包括两个主要阶段:首先是对候选类别进行初步评估和排名,其次是根据评估结果动态调整标签空间,最终在测试时使用优化后的标签空间进行分类。
关键创新:LSR的核心创新在于其动态优化标签空间的能力,利用未标记数据和统计学习方法,使得模型在测试时能够自适应地选择最相关的标签,与传统方法相比,显著提高了分类性能。
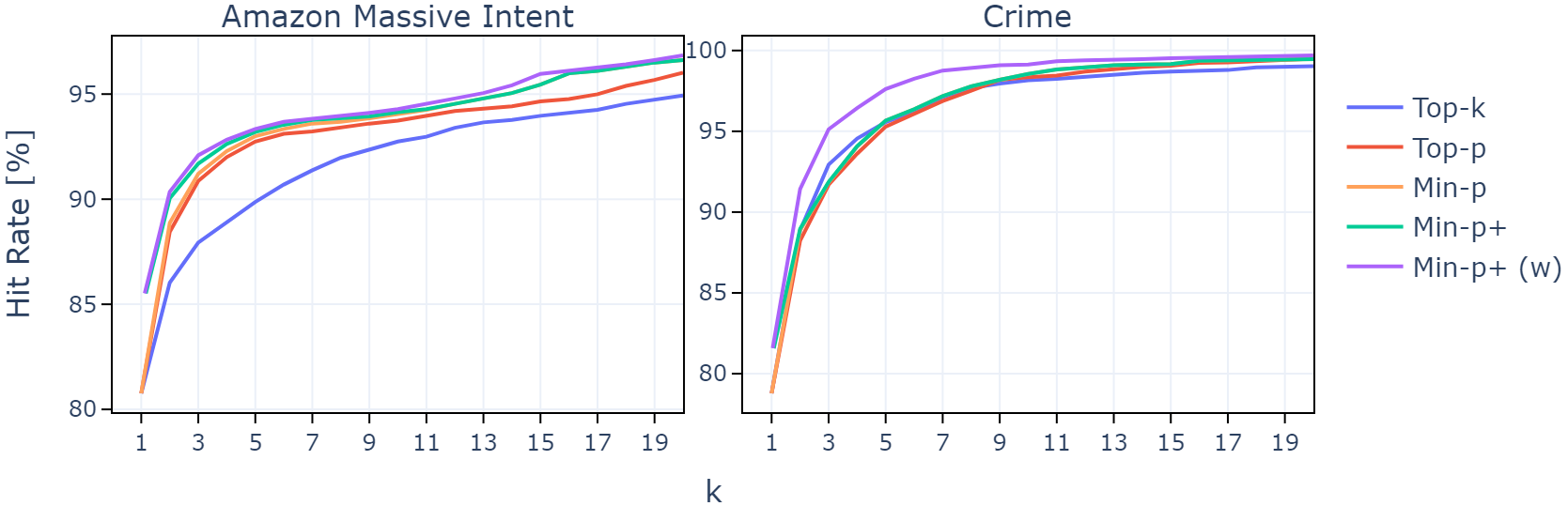
关键设计:在LSR中,关键设计包括对候选类别的评估标准、迭代过程中的参数设置,以及最终的概率分类器的构建,这些设计确保了模型在推理时的高效性和准确性。
🖼️ 关键图片
📊 实验亮点
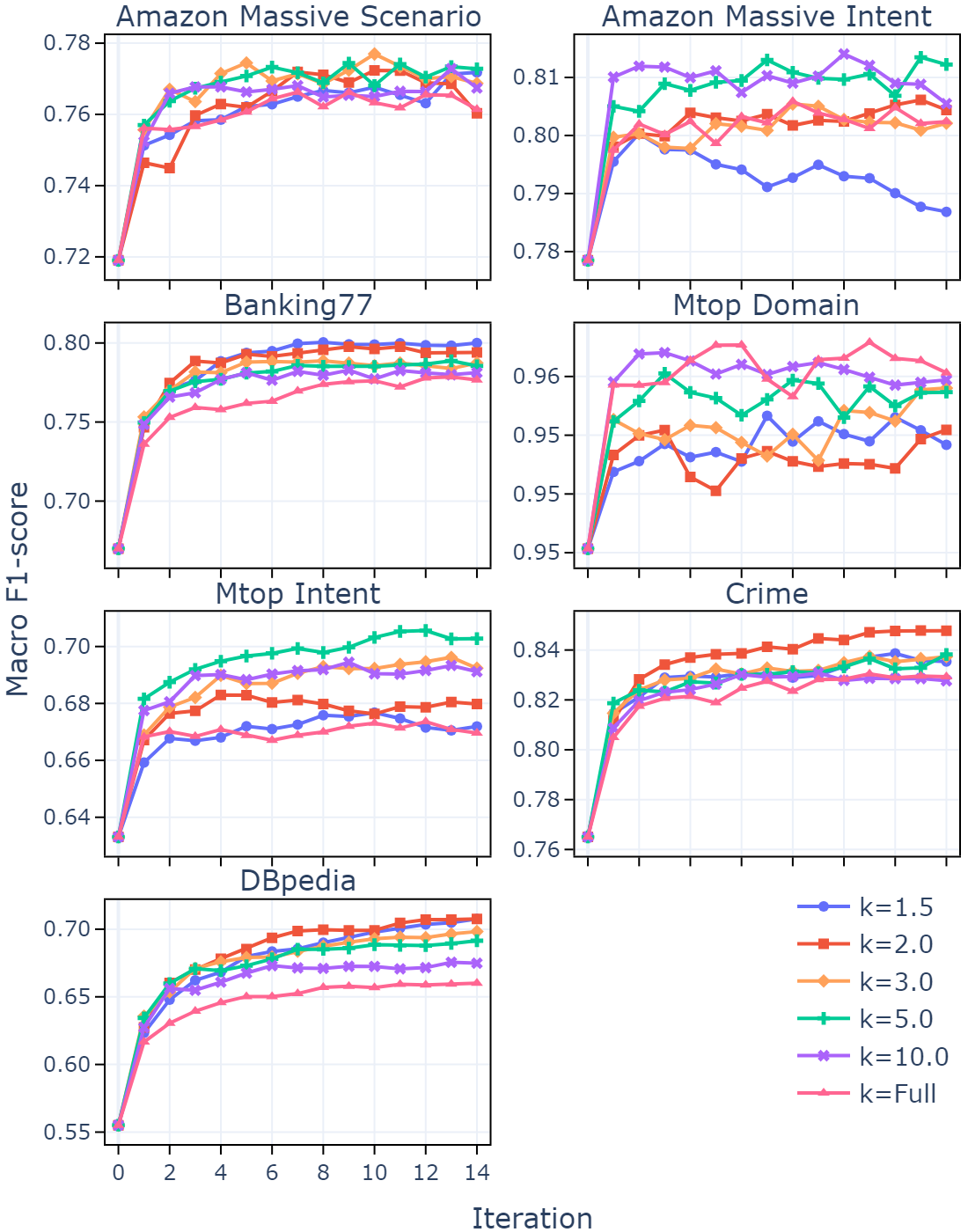
实验结果显示,LSR在Llama-3.1-70B上平均提升宏F1分数7.0%(最高可达14.2%),在Claude-3.5-Sonnet上提升3.3%(最高可达11.1%),相较于标准的零样本分类基线,展现了显著的性能提升。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、图像分类和推荐系统等,尤其是在需要处理大量类别的场景中。LSR能够帮助模型在未标记数据环境下更有效地进行分类,具有重要的实际价值和未来影响。
📄 摘要(原文)
We present Label Space Reduction (LSR), a novel method for improving zero-shot classification performance of Large Language Models (LLMs). LSR iteratively refines the classification label space by systematically ranking and reducing candidate classes, enabling the model to concentrate on the most relevant options. By leveraging unlabeled data with the statistical learning capabilities of data-driven models, LSR dynamically optimizes the label space representation at test time. Our experiments across seven benchmarks demonstrate that LSR improves macro-F1 scores by an average of 7.0% (up to 14.2%) with Llama-3.1-70B and 3.3% (up to 11.1%) with Claude-3.5-Sonnet compared to standard zero-shot classification baselines. To reduce the computational overhead of LSR, which requires an additional LLM call at each iteration, we propose distilling the model into a probabilistic classifier, allowing for efficient inference.