Word Synchronization Challenge: A Benchmark for Word Association Responses for Large Language Models
作者: Tanguy Cazalets, Joni Dambre
分类: cs.HC, cs.CL
发布日期: 2025-02-12 (更新: 2026-01-14)
DOI: 10.1007/978-3-031-93864-1_1
💡 一句话要点
提出词语同步挑战:用于评估大语言模型词语联想能力的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人机交互 词语联想 基准测试 认知过程
📋 核心要点
- 现有LLM在人机交互中,难以准确模拟人类认知过程,尤其是在动态对话场景下的词语联想方面。
- 提出“词语同步挑战”基准,通过模拟游戏框架,评估LLM在词语联想中与人类思维模式对齐的能力。
- 初步实验表明,模型复杂性显著影响其在词语同步挑战中的表现,揭示了模型社会交互能力的差异。
📝 摘要(中文)
本文提出了“词语同步挑战”,这是一个新颖的基准测试,旨在评估大型语言模型(LLM)在人机交互(HCI)中的表现。该基准采用动态的、类似游戏的框架,通过词语联想来测试LLM模仿人类认知过程的能力。通过模拟复杂的人类交互,它评估了LLM在对话交流中如何理解并与人类思维模式保持一致,这对于HCI中有效的社会合作至关重要。初步研究结果突出了模型复杂性对性能的影响,为模型参与有意义的社会互动和以类人方式调整行为的能力提供了见解。这项研究加深了对LLM复制或偏离人类认知功能的潜力的理解,为更细致和更具同理心的人机协作铺平了道路。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLM)在人机交互(HCI)中模仿人类认知过程,特别是词语联想能力的问题。现有方法缺乏一个动态的、交互式的基准来衡量LLM在模拟复杂人类对话场景中的表现,难以评估LLM是否能真正理解并对齐人类的思维模式。
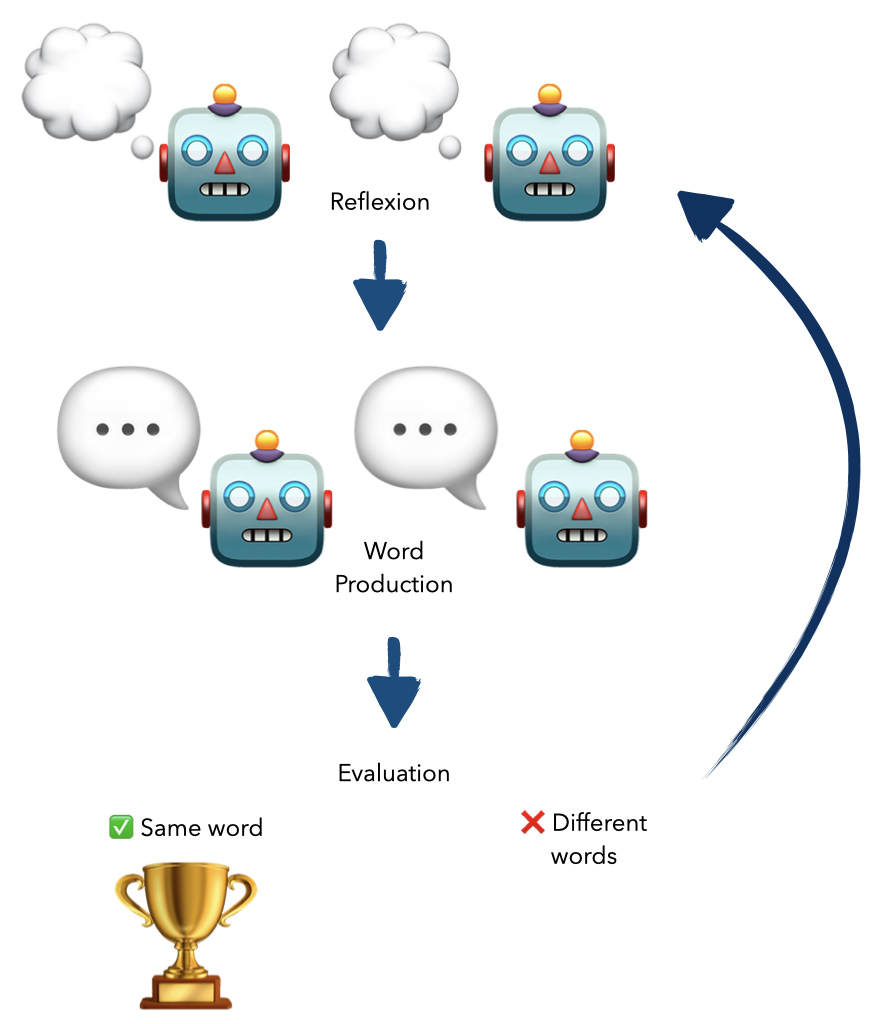
核心思路:论文的核心思路是设计一个类似游戏的“词语同步挑战”基准,通过让LLM参与词语联想任务,模拟人类在对话中的认知过程。这种动态的、交互式的框架能够更真实地反映LLM在实际HCI场景中的表现,从而更准确地评估其社会交互能力。
技术框架:该基准测试框架包含以下主要模块:1) 词语联想游戏环境:模拟人类对话场景,提供初始词语并接收LLM的联想词语。2) LLM接口:允许不同的LLM参与测试,并接收其输出的联想词语。3) 评估指标:衡量LLM的联想词语与人类思维模式的对齐程度,例如,使用人类参与者作为基准,评估LLM的联想词语与人类联想词语的相似度。4) 动态调整机制:根据LLM的表现,动态调整游戏难度,以更全面地评估其能力。
关键创新:该论文的关键创新在于提出了一个动态的、交互式的基准测试框架,用于评估LLM在词语联想方面的能力。与传统的静态评估方法相比,该基准能够更真实地模拟人类对话场景,从而更准确地评估LLM在HCI中的表现。此外,该基准还提供了一个可扩展的平台,可以方便地集成不同的LLM和评估指标。
关键设计:该基准的关键设计包括:1) 词语选择策略:选择具有代表性的词语作为初始词语,以覆盖不同的语义领域。2) 联想词语评估指标:使用多种指标来衡量LLM的联想词语与人类思维模式的对齐程度,例如,使用余弦相似度来衡量LLM的联想词语与人类联想词语的语义相似度。3) 动态难度调整机制:根据LLM的表现,动态调整初始词语的难度,以更全面地评估其能力。具体的参数设置和损失函数未知。
🖼️ 关键图片

📊 实验亮点
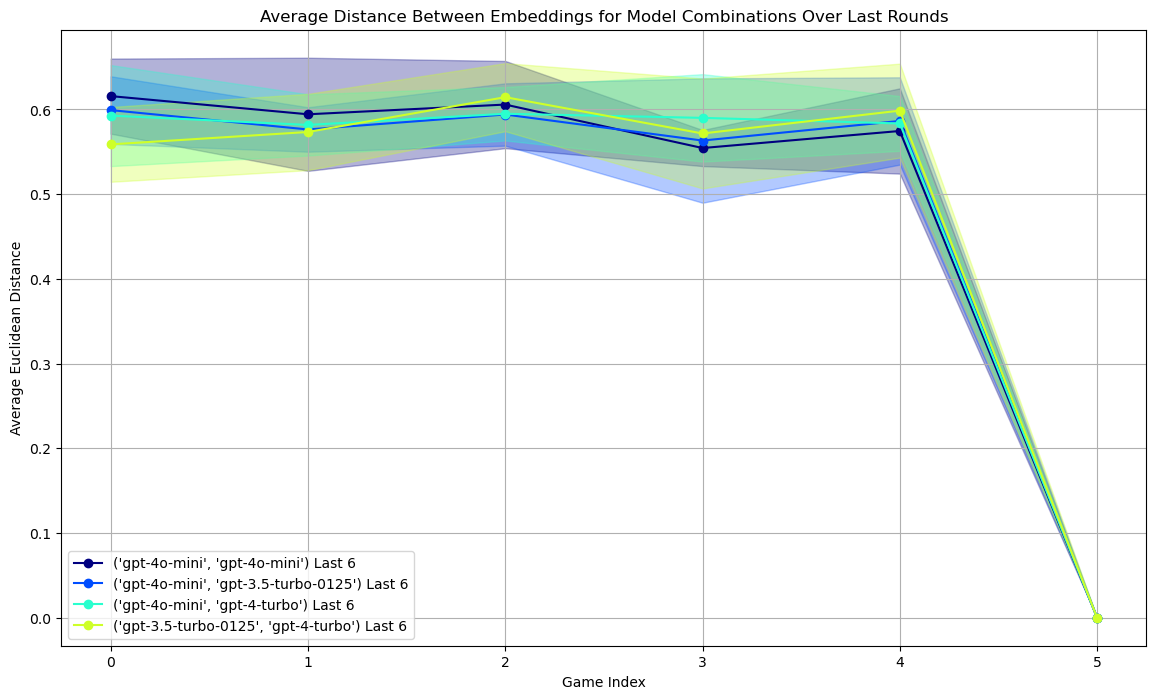
初步实验结果表明,模型复杂性对词语同步挑战的性能有显著影响。更复杂的模型在模拟人类词语联想方面表现更好,表明其在理解和对齐人类思维模式方面具有更强的能力。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于开发更自然、更具同理心的人机交互系统,例如智能助手、聊天机器人和虚拟社交伙伴。通过提高LLM在词语联想方面的能力,可以改善人机对话的流畅性和理解度,从而增强用户体验。未来,该研究还可以促进LLM在教育、医疗和娱乐等领域的应用。
📄 摘要(原文)
This paper introduces the Word Synchronization Challenge, a novel benchmark to evaluate large language models (LLMs) in Human-Computer Interaction (HCI). This benchmark uses a dynamic game-like framework to test LLMs ability to mimic human cognitive processes through word associations. By simulating complex human interactions, it assesses how LLMs interpret and align with human thought patterns during conversational exchanges, which are essential for effective social partnerships in HCI. Initial findings highlight the influence of model sophistication on performance, offering insights into the models capabilities to engage in meaningful social interactions and adapt behaviors in human-like ways. This research advances the understanding of LLMs potential to replicate or diverge from human cognitive functions, paving the way for more nuanced and empathetic human-machine collaborations.