WHODUNIT: Evaluation benchmark for culprit detection in mystery stories
作者: Kshitij Gupta
分类: cs.CL, cs.AI
发布日期: 2025-02-11
💡 一句话要点
提出WhoDunIt数据集,评估LLM在推理小说中识别罪犯的演绎推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 演绎推理 叙事理解 数据集构建 鲁棒性评估
📋 核心要点
- 现有方法缺乏在叙事推理场景下,特别是推理小说中,对LLM演绎推理能力进行有效评估的数据集。
- 构建WhoDunIt数据集,通过阅读理解推理小说,并结合名称增强等方法,考察LLM的罪犯识别能力。
- 实验表明,LLM在原始文本上表现良好,但在名称替换后,特别是使用知名实体替换时,准确率显著下降。
📝 摘要(中文)
本文提出了一个名为WhoDunIt的新数据集,旨在评估大型语言模型(LLM)在叙事语境下的演绎推理能力。该数据集构建于开放领域的推理小说和短篇故事,挑战LLM在阅读和理解故事后识别罪犯。为了评估模型的鲁棒性,我们应用了一系列字符级别的名称增强方法,包括原始名称、名称交换以及用流行语中广为人知的真实和/或虚构实体进行替换。我们进一步使用各种提示风格来研究提示对演绎推理准确性的影响。我们使用最先进的模型进行了评估研究,特别是GPT-4o、GPT-4-turbo和GPT-4o-mini,通过多次试验和多数响应选择进行评估,以确保可靠性。结果表明,虽然LLM在未修改的文本上表现可靠,但准确性会随着某些名称替换而降低,特别是那些具有广泛识别度的名称替换。该数据集已公开。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在阅读理解推理小说后,进行演绎推理并识别罪犯的能力。现有方法缺乏一个专门用于评估LLM在复杂叙事推理场景下表现的数据集,尤其是在存在干扰因素(如名称替换)的情况下。这使得我们难以准确评估LLM在现实世界推理任务中的潜力。
核心思路:论文的核心思路是构建一个包含大量推理小说和短篇故事的数据集,并设计一系列名称增强方法,以模拟真实世界中可能存在的歧义和干扰。通过评估LLM在这些增强数据上的表现,可以更全面地了解其演绎推理能力和鲁棒性。
技术框架:WhoDunIt数据集的构建流程主要包括以下几个阶段:1) 从开放领域收集推理小说和短篇故事;2) 对故事进行预处理,提取关键信息,如人物名称和情节;3) 应用名称增强方法,包括名称交换和使用知名实体进行替换,生成多个变体;4) 设计评估指标,用于衡量LLM识别罪犯的准确率。评估流程包括:1) 使用不同的提示风格向LLM呈现故事;2) LLM根据故事内容进行推理,并给出罪犯的预测;3) 根据评估指标计算LLM的准确率。
关键创新:该论文的关键创新在于提出了一个专门用于评估LLM在叙事推理场景下演绎推理能力的数据集WhoDunIt。该数据集不仅包含大量的推理小说和短篇故事,还设计了一系列名称增强方法,可以有效地评估LLM的鲁棒性和对干扰因素的抵抗能力。此外,该论文还探讨了不同提示风格对LLM推理准确率的影响。
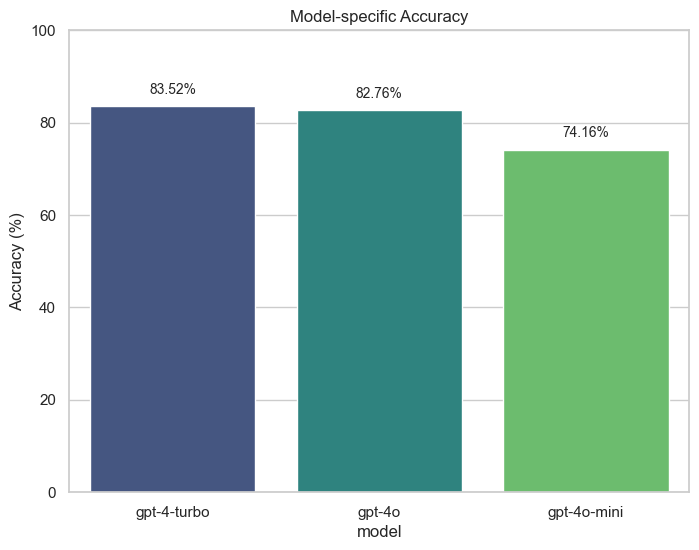
关键设计:名称增强方法是该数据集的关键设计之一。论文采用了多种名称增强策略,包括:1) 名称交换:随机交换故事中不同人物的名称;2) 实体替换:使用流行语中广为人知的真实和/或虚构实体替换人物名称。这些增强方法旨在模拟真实世界中可能存在的歧义和干扰,从而更全面地评估LLM的推理能力。实验中,使用了GPT-4o、GPT-4-turbo和GPT-4o-mini等模型,并进行了多次试验,采用多数响应选择以确保结果的可靠性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,虽然LLM在原始文本上表现出较高的准确率,但在经过名称替换等增强处理后,准确率显著下降,尤其是在使用知名实体进行替换时。这表明LLM在叙事推理方面仍然存在局限性,容易受到干扰因素的影响。GPT-4o在原始文本上的准确率最高,但其在增强数据上的表现也受到了显著影响。
🎯 应用场景
该研究成果可应用于提升LLM在复杂叙事推理场景下的表现,例如在智能客服、游戏AI、内容创作等领域。通过提高LLM对叙事文本的理解和推理能力,可以使其更好地理解用户意图、生成更具吸引力的故事情节,并提供更个性化的服务。此外,该数据集也可用于评估和比较不同LLM的推理能力,推动相关技术的发展。
📄 摘要(原文)
We present a novel data set, WhoDunIt, to assess the deductive reasoning capabilities of large language models (LLM) within narrative contexts. Constructed from open domain mystery novels and short stories, the dataset challenges LLMs to identify the perpetrator after reading and comprehending the story. To evaluate model robustness, we apply a range of character-level name augmentations, including original names, name swaps, and substitutions with well-known real and/or fictional entities from popular discourse. We further use various prompting styles to investigate the influence of prompting on deductive reasoning accuracy. We conduct evaluation study with state-of-the-art models, specifically GPT-4o, GPT-4-turbo, and GPT-4o-mini, evaluated through multiple trials with majority response selection to ensure reliability. The results demonstrate that while LLMs perform reliably on unaltered texts, accuracy diminishes with certain name substitutions, particularly those with wide recognition. This dataset is publicly available here.