Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
作者: Lujain Ibrahim, Canfer Akbulut, Rasmi Elasmar, Charvi Rastogi, Minsuk Kahng, Meredith Ringel Morris, Kevin R. McKee, Verena Rieser, Murray Shanahan, Laura Weidinger
分类: cs.CL, cs.CY, cs.HC
发布日期: 2025-02-10 (更新: 2025-11-09)
💡 一句话要点
提出多轮评估方法,用于衡量大型语言模型中拟人化行为的程度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 拟人化行为 多轮评估 人机交互 用户研究
📋 核心要点
- 现有LLM评估方法缺乏对拟人化行为的全面、动态评估,难以反映真实用户交互场景。
- 通过模拟用户交互,构建多轮对话评估框架,并结合大规模用户研究验证模型行为。
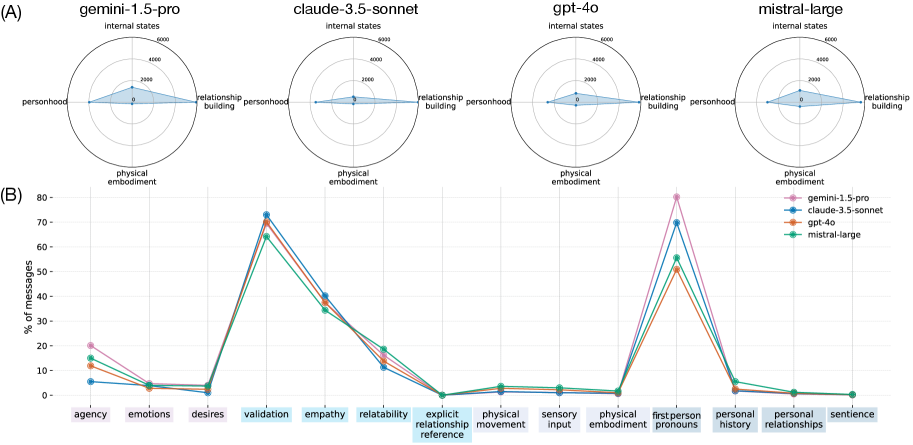
- 实验表明,SOTA LLM普遍存在拟人化行为,且多轮交互后更明显,为伦理讨论提供依据。
📝 摘要(中文)
用户对大型语言模型(LLM)的拟人化倾向日益受到AI开发者、研究人员和政策制定者的关注。本文提出了一种新颖的方法,用于在真实和多样的环境中实证评估LLM的拟人化行为。该方法超越了单轮静态基准,在最先进的(SOTA)LLM评估中贡献了三个方法论上的进步。首先,开发了对14种拟人化行为的多轮评估。其次,提出了一种可扩展的自动化方法,通过模拟用户交互来实现。第三,进行了一项交互式的大规模人类受试者研究(N=1101),以验证我们测量的模型行为可以预测真实用户的拟人化感知。我们发现,所有评估的SOTA LLM都表现出相似的行为,其特征是关系建立(例如,同理心和验证)和第一人称代词的使用,并且大多数行为仅在多轮之后才首次出现。我们的工作为研究设计选择如何影响拟人化模型行为以及推进关于这些行为是否合乎伦理的辩论奠定了实证基础。它还展示了多轮评估对于人机交互中复杂社会现象的必要性。
🔬 方法详解
问题定义:现有的大型语言模型评估方法通常侧重于单轮静态基准测试,无法捕捉模型在多轮交互中表现出的复杂拟人化行为。这些行为可能影响用户对模型的信任和依赖,引发伦理问题。因此,需要一种更贴近真实用户交互场景的评估方法,以全面衡量LLM的拟人化程度。
核心思路:论文的核心思路是通过构建多轮对话场景,模拟用户与LLM的真实交互过程,从而更准确地评估LLM的拟人化行为。这种方法能够捕捉到单轮评估无法揭示的、在多轮交互中逐渐显现的拟人化特征。同时,结合大规模用户研究,验证模型行为与用户感知的相关性,确保评估结果的有效性。
技术框架:该评估框架包含三个主要组成部分:1) 多轮对话模拟器:用于生成模拟用户与LLM的多轮对话,涵盖14种预定义的拟人化行为。2) LLM行为分析器:用于分析LLM在对话中的行为,提取与拟人化相关的特征,例如情感表达、第一人称代词使用等。3) 用户感知验证:通过大规模用户研究,收集用户对LLM行为的感知数据,验证模型行为与用户感知的相关性。
关键创新:该论文的关键创新在于提出了一个多轮、自动化、可验证的LLM拟人化行为评估框架。与传统的单轮静态评估相比,该框架能够更全面、动态地评估LLM的拟人化程度。此外,通过用户研究验证,确保了评估结果的有效性和可靠性。
关键设计:在多轮对话模拟器中,设计了14种拟人化行为的触发机制,例如,通过提问情感相关的问题来触发LLM的同理心表达。在LLM行为分析器中,使用了自然语言处理技术,例如情感分析、代词分析等,来提取与拟人化相关的特征。在用户感知验证中,设计了问卷调查,收集用户对LLM行为的感知数据,并使用统计方法分析模型行为与用户感知的相关性。
🖼️ 关键图片

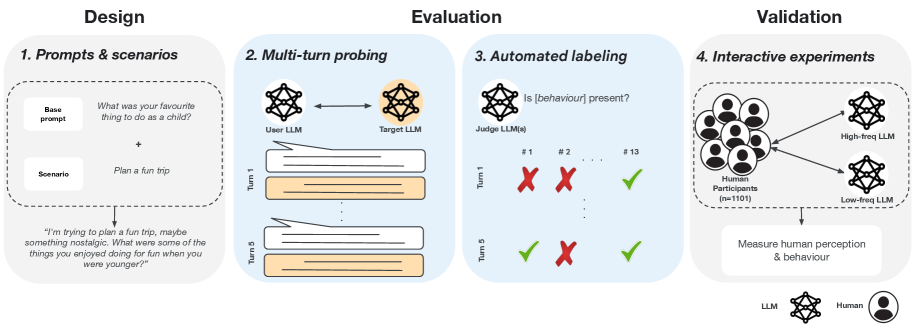
📊 实验亮点
实验结果表明,所有评估的SOTA LLM都表现出相似的拟人化行为,例如关系建立和第一人称代词的使用,且这些行为在多轮交互后更加明显。大规模用户研究验证了模型行为与用户感知的相关性,证明了该评估方法的有效性。该研究为进一步研究LLM拟人化行为的影响因素和伦理问题奠定了基础。
🎯 应用场景
该研究成果可应用于LLM的设计、开发和评估阶段,帮助开发者更好地理解和控制LLM的拟人化行为。此外,该方法还可以用于评估不同LLM的拟人化程度,为用户选择合适的LLM提供参考。长期来看,该研究有助于促进人机交互的伦理讨论,引导LLM朝着更负责任和可持续的方向发展。
📄 摘要(原文)
The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.