IRepair: An Intent-Aware Approach to Repair Data-Driven Errors in Large Language Models
作者: Sayem Mohammad Imtiaz, Astha Singh, Fraol Batole, Hridesh Rajan
分类: cs.CL, cs.AI, cs.SE
发布日期: 2025-02-10 (更新: 2025-03-11)
备注: Accepted as full research paper at FSE'2025
💡 一句话要点
提出IRepair以解决大语言模型中的数据驱动错误问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据偏见 动态切片 意图感知 修复策略 毒性缓解 模型优化
📋 核心要点
- 现有的领域自适应训练方法对模型参数进行无差别修复,导致修复质量差且模型通用性降低。
- 本文提出的IRepair方法通过动态切片技术,选择性地修复模型中最易出错的部分,提高修复效果。
- 实验结果显示,IRepair在毒性缓解任务中修复效果提高43.6%,对模型整体性能的干扰减少46%。
📝 摘要(中文)
在大语言模型(LLMs)取得显著成就的同时,其面临的数据偏见问题也日益严重,导致如毒性内容等问题。现有的领域自适应训练方法往往对模型参数进行无差别修复,导致修复质量差且模型通用性降低。本文提出了一种新颖的动态切片意图感知LLM修复策略IRepair,选择性地针对模型中最易出错的部分进行修复。通过动态切片模型中最敏感的层,集中修复努力于这些区域,从而实现更有效的修复,且对模型整体性能的影响较小。实验结果表明,IRepair在毒性缓解任务中修复效果提高了43.6%,同时对模型整体性能的干扰减少了46%。
🔬 方法详解
问题定义:本文旨在解决大语言模型中由于数据偏见导致的错误修复问题。现有方法在修复过程中对所有模型参数进行无差别处理,导致修复效果不佳且影响模型的通用性。
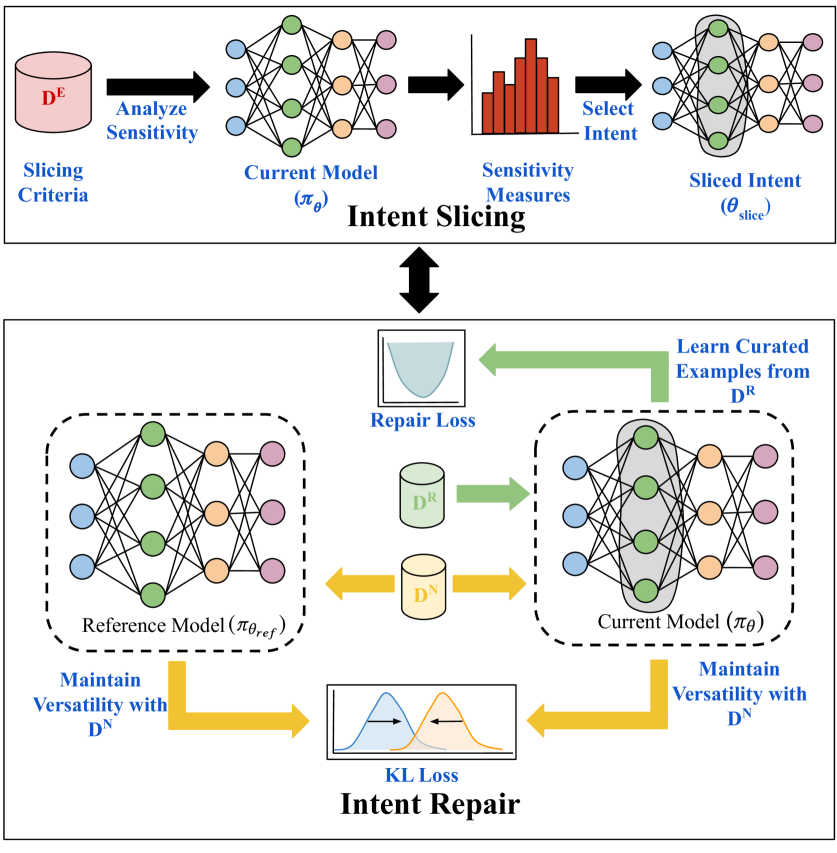
核心思路:IRepair的核心思路是动态切片,选择性地针对模型中最敏感的层进行修复。通过集中修复这些高错误密度区域,能够更有效地提升修复质量,同时减少对模型整体性能的影响。
技术框架:IRepair的整体架构包括动态切片模块和修复模块。动态切片模块识别出最易出错的层,而修复模块则专注于这些层的参数调整。整个流程通过反馈机制不断优化修复策略。
关键创新:IRepair的主要创新在于其动态切片策略,能够有效识别并集中修复错误密集区域,与现有方法相比,避免了对整个模型的无差别修复。
关键设计:在参数设置上,IRepair采用了针对性损失函数,强调对高错误密度层的修复。此外,网络结构上,IRepair通过动态调整修复策略,确保修复过程的灵活性和高效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IRepair在毒性缓解任务中修复效果提高了43.6%,同时对模型整体性能的干扰减少了46%。与最接近的基线方法直接偏好优化相比,IRepair展现出显著的优势,表明其在选择性修复方面的有效性。
🎯 应用场景
IRepair的研究成果在多个领域具有潜在应用价值,尤其是在自然语言处理和生成任务中。通过有效修复模型中的偏见和错误,IRepair能够提升大语言模型的安全性和可靠性,减少有害内容的生成。此外,该方法的灵活性使其适用于不同类型的模型和任务,具有广泛的推广潜力。
📄 摘要(原文)
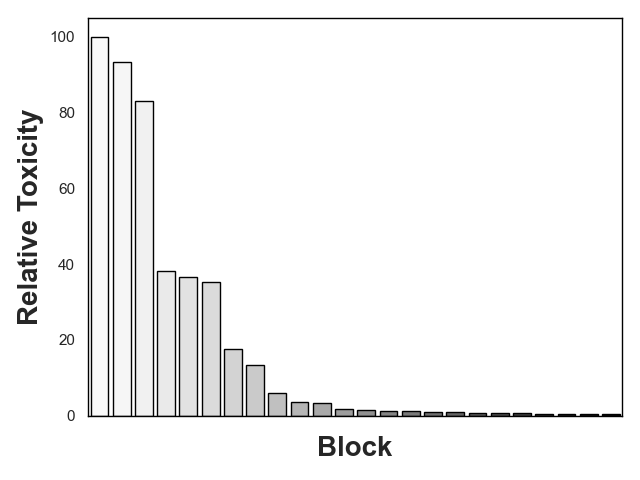
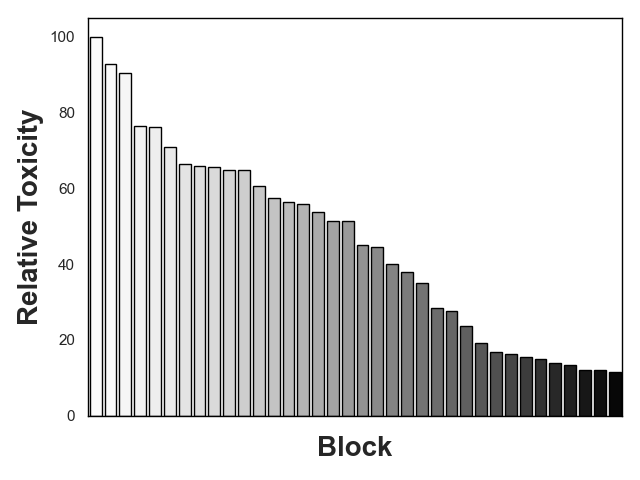
Not a day goes by without hearing about the impressive feats of large language models (LLMs), and equally, not a day passes without hearing about their challenges. LLMs are notoriously vulnerable to biases in their dataset, leading to issues such as toxicity. While domain-adaptive training has been employed to mitigate these issues, these techniques often address all model parameters indiscriminately during the repair process, resulting in poor repair quality and reduced model versatility. In this paper, we introduce a novel dynamic slicing-based intent-aware LLM repair strategy, IRepair. This approach selectively targets the most error-prone sections of the model for repair. Specifically, we propose dynamically slicing the model's most sensitive layers that require immediate attention, concentrating repair efforts on those areas. This method enables more effective repairs with potentially less impact on the model's overall performance by altering a smaller portion of the model. We evaluated our technique on three models from the GPT2 and GPT-Neo families, with parameters ranging from 800M to 1.6B, in a toxicity mitigation setup. Our results show that IRepair repairs errors 43.6% more effectively while causing 46% less disruption to general performance compared to the closest baseline, direct preference optimization. Our empirical analysis also reveals that errors are more concentrated in a smaller section of the model, with the top 20% of layers exhibiting 773% more error density than the remaining 80\%. This highlights the need for selective repair. Additionally, we demonstrate that a dynamic selection approach is essential for addressing errors dispersed throughout the model, ensuring a robust and efficient repair.