Emergent Response Planning in LLMs
作者: Zhichen Dong, Zhanhui Zhou, Zhixuan Liu, Chao Yang, Chaochao Lu
分类: cs.CL, cs.LG
发布日期: 2025-02-10 (更新: 2025-08-04)
备注: Published at ICML 2025. Code available at: https://github.com/niconi19/Emergent-Response-Planning-in-LLMs
期刊: Proceedings of the 42nd International Conference on Machine Learning (ICML 2025)
💡 一句话要点
揭示LLM涌现的响应规划能力:隐藏层编码未来输出属性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 涌现能力 响应规划 隐藏层表示 探查技术
📋 核心要点
- 现有LLM训练目标仅为预测下一个token,缺乏对全局响应的显式规划,导致生成过程难以控制和解释。
- 该研究通过探查LLM的隐藏层表示,揭示其编码了未来响应的结构、内容和行为属性,证明了涌现的响应规划能力。
- 实验表明,LLM的响应规划能力随模型规模增大而增强,并随生成过程动态演变,为提升LLM的透明度和控制力提供了新思路。
📝 摘要(中文)
本文提出,尽管大型语言模型(LLM)仅被训练来预测下一个token,但它们表现出涌现的规划行为:$ extbf{它们的隐藏层表示编码了超出下一个token的未来输出}$。通过简单的探查,我们证明LLM的prompt表示编码了其整个响应的全局属性,包括$ extit{结构属性}$(例如,响应长度、推理步骤),$ extit{内容属性}$(例如,故事写作中的角色选择、响应末尾的多项选择答案),以及$ extit{行为属性}$(例如,答案置信度、事实一致性)。除了识别响应规划之外,我们还探讨了它如何随模型大小在不同任务中扩展,以及它在生成过程中如何演变。LLM在其隐藏层表示中提前规划未来的发现,为提高透明度和生成控制提供了潜在的应用。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的训练方式主要集中于预测下一个token,缺乏对整个生成过程的全局规划。这导致LLM在生成长文本或复杂推理时,容易出现结构混乱、内容不一致等问题。此外,由于缺乏对生成过程的显式控制,用户难以干预LLM的输出,例如调整响应的长度、风格或事实准确性。因此,如何让LLM具备更强的规划能力,并提高生成过程的可控性和透明度,是一个重要的研究问题。
核心思路:本文的核心思路是,尽管LLM仅被训练来预测下一个token,但其隐藏层表示可能已经编码了未来响应的全局属性。通过探查这些隐藏层表示,可以揭示LLM的涌现规划能力,并利用这些信息来改进生成过程的控制和解释。具体来说,作者假设LLM在处理prompt时,会提前规划整个响应的结构、内容和行为,并将这些规划信息编码到隐藏层中。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择不同的LLM模型和任务;2) 设计合适的prompt,引导LLM生成特定类型的响应;3) 提取LLM在处理prompt时的隐藏层表示;4) 使用简单的探查技术(例如线性分类器)来预测响应的各种属性,例如响应长度、推理步骤、角色选择、答案置信度等;5) 分析预测结果,评估LLM的响应规划能力,并研究其随模型大小和生成过程的演变。
关键创新:该研究最重要的技术创新点在于,它首次揭示了LLM的涌现响应规划能力。通过简单的探查实验,作者证明LLM的隐藏层表示编码了未来响应的全局属性,这颠覆了以往认为LLM仅关注下一个token的观点。此外,该研究还探讨了响应规划能力随模型大小和生成过程的演变规律,为理解LLM的内部机制提供了新的视角。
关键设计:在探查实验中,作者使用了线性分类器作为探针,将LLM的隐藏层表示映射到响应的各种属性。为了评估响应规划能力,作者设计了多种任务,包括故事写作、多项选择题解答等。在故事写作任务中,作者探查了隐藏层表示对角色选择的编码;在多项选择题解答任务中,作者探查了隐藏层表示对答案置信度的编码。此外,作者还研究了不同隐藏层对响应属性的编码能力,以及响应规划能力随生成过程的演变。
🖼️ 关键图片

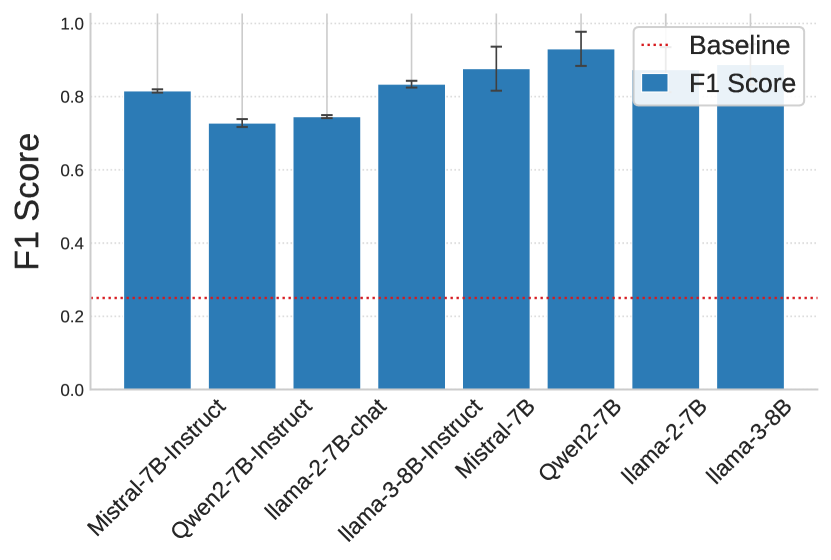

📊 实验亮点
该研究通过实验证明,LLM的隐藏层表示编码了未来响应的结构、内容和行为属性。例如,在故事写作任务中,线性探针能够以较高的准确率预测LLM将选择的角色。此外,实验还表明,LLM的响应规划能力随模型规模增大而增强,例如更大的模型能够更准确地预测响应的长度和推理步骤。这些结果表明,LLM具备涌现的响应规划能力,为改进LLM的生成控制和透明度提供了新的思路。
🎯 应用场景
该研究的潜在应用领域包括:提高LLM生成内容的可控性,例如控制生成文本的长度、风格和事实准确性;增强LLM的透明度,例如解释LLM的推理过程和决策依据;开发更智能的LLM应用,例如自动生成高质量的故事、文章和代码。未来的研究可以进一步探索如何利用LLM的响应规划能力来改进生成算法,并开发更强大的LLM应用。
📄 摘要(原文)
In this work, we argue that large language models (LLMs), though trained to predict only the next token, exhibit emergent planning behaviors: $\textbf{their hidden representations encode future outputs beyond the next token}$. Through simple probing, we demonstrate that LLM prompt representations encode global attributes of their entire responses, including $\textit{structure attributes}$ (e.g., response length, reasoning steps), $\textit{content attributes}$ (e.g., character choices in storywriting, multiple-choice answers at the end of response), and $\textit{behavior attributes}$ (e.g., answer confidence, factual consistency). In addition to identifying response planning, we explore how it scales with model size across tasks and how it evolves during generation. The findings that LLMs plan ahead for the future in their hidden representations suggest potential applications for improving transparency and generation control.