Learning Task Representations from In-Context Learning
作者: Baturay Saglam, Xinyang Hu, Zhuoran Yang, Dionysis Kalogerias, Amin Karbasi
分类: cs.CL, cs.LG
发布日期: 2025-02-08 (更新: 2025-11-08)
备注: ACL Findings 2025
💡 一句话要点
提出基于注意力头的任务向量提取方法,提升ICL在文本和回归任务上的泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 任务表示 注意力机制 跨模态学习 函数回归
📋 核心要点
- 现有上下文学习方法在跨模态泛化能力上存在不足,尤其是在文本以外的模态上表现不佳。
- 提出一种基于注意力头的任务向量提取方法,通过优化注意力头的权重来编码任务信息,实现更好的泛化。
- 实验表明,该方法在文本和回归任务上均表现出色,验证了其跨模态的通用性和有效性。
📝 摘要(中文)
大型语言模型(LLMs)在上下文学习(ICL)中表现出卓越的能力,它们可以通过基于示例的提示来适应新任务,而无需更新参数。然而,理解任务如何在内部编码和泛化仍然是一个挑战。为了解决文献中的一些经验和技术差距,我们引入了一种自动化的公式,用于将ICL提示中的任务信息编码为Transformer架构中注意力头的函数。该方法计算一个单一的任务向量,作为注意力头的加权和,权重通过梯度下降进行因果优化。我们的研究结果表明,现有方法无法有效地推广到文本以外的模态。为此,我们还设计了一个基准,以评估任务向量是否能在函数回归任务中保持任务的保真度。所提出的方法成功地从上下文演示中提取了特定于任务的信息,并在文本和回归任务中表现出色,证明了其跨模态的通用性。
🔬 方法详解
问题定义:现有上下文学习方法在处理不同模态的任务时,泛化能力不足。尤其是在文本以外的模态,例如函数回归任务中,现有方法难以有效提取和利用上下文信息,导致性能下降。现有方法缺乏一种通用的任务表示方法,能够适应不同模态的任务。
核心思路:论文的核心思路是将任务信息编码为一个任务向量,该向量通过对Transformer架构中不同注意力头的输出进行加权求和得到。通过优化这些权重,可以使任务向量更好地捕捉任务的关键特征,从而提高上下文学习的泛化能力。这种方法旨在提取一种更具代表性和泛化性的任务表示。
技术框架:整体框架包括以下几个步骤:1) 使用上下文示例构建ICL提示;2) 通过Transformer模型处理提示,得到各个注意力头的输出;3) 使用可学习的权重对注意力头的输出进行加权求和,得到任务向量;4) 使用梯度下降优化权重,使得任务向量能够更好地预测目标输出。该框架的关键在于如何有效地学习注意力头的权重。
关键创新:最重要的技术创新点在于提出了一种自动化的方法来学习注意力头的权重,从而提取任务向量。与现有方法相比,该方法不需要手动设计特征或选择注意力头,而是通过梯度下降自动学习最优的权重组合。这种方法能够更好地适应不同任务和模态,提高泛化能力。
关键设计:关键设计包括:1) 使用因果梯度下降来优化注意力头的权重,避免信息泄露;2) 设计了一个新的基准来评估任务向量在函数回归任务中的保真度;3) 使用加权和的方式来组合注意力头的输出,权重通过可学习的参数进行控制。损失函数的设计目标是最小化预测输出与真实输出之间的差异。
🖼️ 关键图片

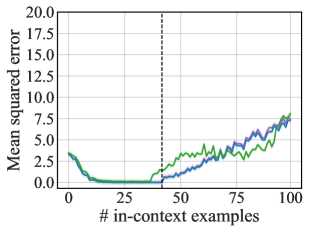
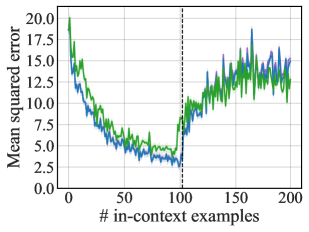
📊 实验亮点
实验结果表明,该方法在文本和回归任务上均取得了显著的性能提升。在文本任务上,该方法优于现有的上下文学习方法。在回归任务上,该方法能够有效地提取任务信息,并实现准确的函数预测。此外,该方法在跨模态泛化能力方面也表现出色,证明了其通用性和有效性。
🎯 应用场景
该研究成果可应用于各种需要上下文学习的场景,例如零样本学习、小样本学习、多模态学习等。在机器人控制、自然语言处理、计算机视觉等领域具有广泛的应用前景。例如,可以利用该方法使机器人能够根据少量示例快速适应新的任务,或者使语言模型能够更好地理解和生成多模态内容。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable proficiency in in-context learning (ICL), where models adapt to new tasks through example-based prompts without requiring parameter updates. However, understanding how tasks are internally encoded and generalized remains a challenge. To address some of the empirical and technical gaps in the literature, we introduce an automated formulation for encoding task information in ICL prompts as a function of attention heads within the transformer architecture. This approach computes a single task vector as a weighted sum of attention heads, with the weights optimized causally via gradient descent. Our findings show that existing methods fail to generalize effectively to modalities beyond text. In response, we also design a benchmark to evaluate whether a task vector can preserve task fidelity in functional regression tasks. The proposed method successfully extracts task-specific information from in-context demonstrations and excels in both text and regression tasks, demonstrating its generalizability across modalities.