DuoGuard: A Two-Player RL-Driven Framework for Multilingual LLM Guardrails
作者: Yihe Deng, Yu Yang, Junkai Zhang, Wei Wang, Bo Li
分类: cs.CL, cs.LG
发布日期: 2025-02-07
备注: 24 pages, 9 figures, 5 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出DuoGuard框架以解决多语言LLM安全性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 强化学习 合成数据 安全性检测 博弈论 数据不平衡 模型优化
📋 核心要点
- 现有的多语言防护模型在安全数据稀缺的情况下,难以有效检测多种语言中的不安全内容。
- 本文提出的DuoGuard框架通过生成器和防护模型的对抗性训练,生成高质量的合成数据,提升多语言防护能力。
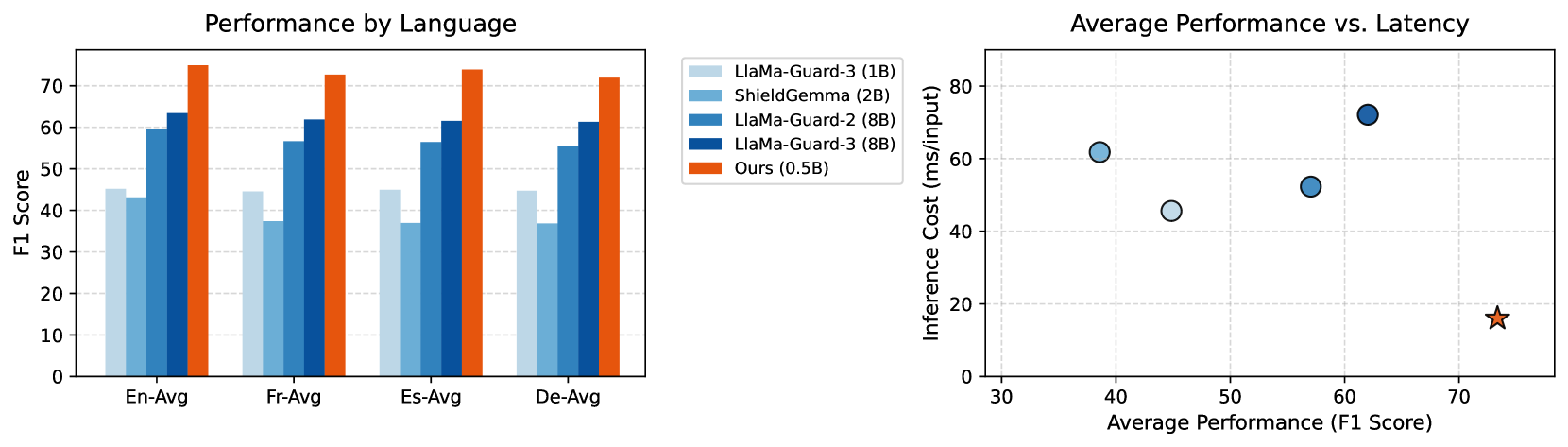
- 实验结果显示,DuoGuard在英语基准上性能提升近10%,推理速度快4.5倍,且在低资源语言的任务中表现显著改善。
📝 摘要(中文)
随着大型语言模型(LLMs)的快速发展,确保其负责任使用的需求日益增加,尤其是在检测不安全和非法内容方面。尽管英语的安全数据相对丰富,但其他语言的多语言防护模型仍然未得到充分探索。为了解决这一问题,本文提出了一种新颖的双玩家强化学习(RL)框架,其中生成器和防护模型对抗性共同进化,以生成高质量的合成数据用于多语言防护训练。理论上,我们将这种交互形式化为双玩家博弈,证明其收敛到纳什均衡。实证评估表明,我们的模型在英语基准上比LlamaGuard3(8B)提高了近10%的性能,同时在推理时速度快了4.5倍,且模型规模显著减小(0.5B)。
🔬 方法详解
问题定义:本文旨在解决多语言环境下大型语言模型的安全性问题,现有方法在非英语语言的安全数据稀缺性导致防护效果不佳。
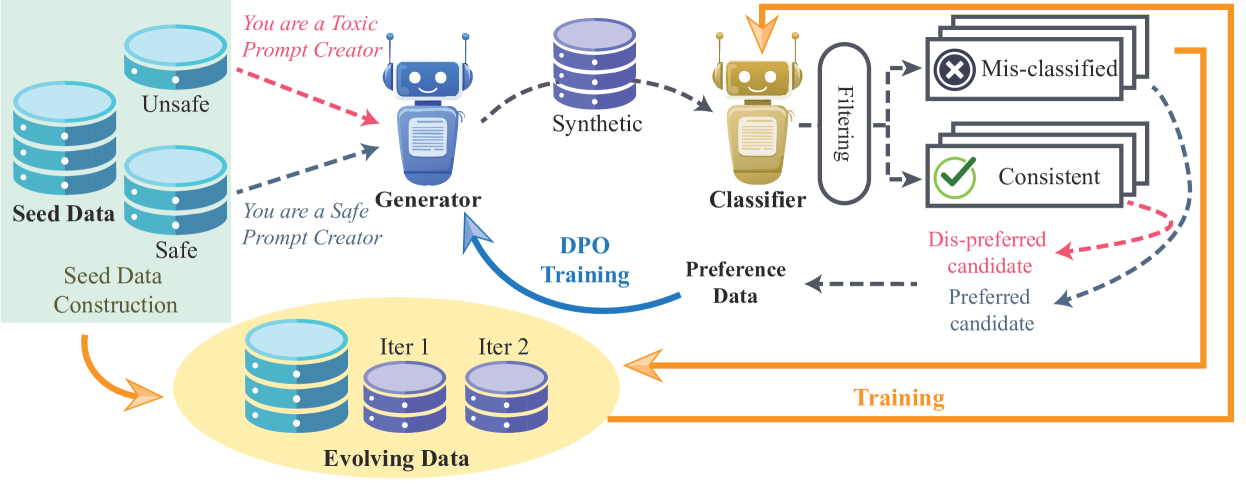
核心思路:提出双玩家强化学习框架,通过生成器与防护模型的对抗性训练,生成合成数据以弥补多语言安全数据的不足。
技术框架:整体架构包括生成器和防护模型两个主要模块,二者通过强化学习进行交互,生成合成数据并不断优化防护能力。
关键创新:最重要的创新在于将生成器与防护模型的训练形式化为双玩家博弈,证明其收敛到纳什均衡,从而实现高效的合成数据生成。
关键设计:在模型设计中,采用了特定的损失函数以平衡生成器与防护模型的训练,确保生成的数据质量高且多样性强,同时优化了模型的参数设置以提高推理速度。
🖼️ 关键图片
📊 实验亮点
实验结果显示,DuoGuard在英语基准上相比LlamaGuard3(8B)提升了近10%的性能,同时在推理速度上快了4.5倍,且模型规模显著减小至0.5B。这些结果表明DuoGuard在多语言安全任务中的有效性和高效性。
🎯 应用场景
DuoGuard框架的潜在应用领域包括多语言内容审核、社交媒体平台的内容监控以及跨国企业的合规性检查。通过提升多语言环境下的安全性,该研究将对社会责任和法律合规产生积极影响,促进更安全的在线交流与信息传播。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has increased the need for guardrail models to ensure responsible use, particularly in detecting unsafe and illegal content. While substantial safety data exist in English, multilingual guardrail modeling remains underexplored due to the scarcity of open-source safety data in other languages. To address this gap, we propose a novel two-player Reinforcement Learning (RL) framework, where a generator and a guardrail model co-evolve adversarially to produce high-quality synthetic data for multilingual guardrail training. We theoretically formalize this interaction as a two-player game, proving convergence to a Nash equilibrium. Empirical evaluations show that our model \ours outperforms state-of-the-art models, achieving nearly 10% improvement over LlamaGuard3 (8B) on English benchmarks while being 4.5x faster at inference with a significantly smaller model (0.5B). We achieve substantial advancements in multilingual safety tasks, particularly in addressing the imbalance for lower-resource languages in a collected real dataset. Ablation studies emphasize the critical role of synthetic data generation in bridging the imbalance in open-source data between English and other languages. These findings establish a scalable and efficient approach to synthetic data generation, paving the way for improved multilingual guardrail models to enhance LLM safety. Code, model, and data will be open-sourced at https://github.com/yihedeng9/DuoGuard.