Probing Internal Representations of Multi-Word Verbs in Large Language Models
作者: Hassane Kissane, Achim Schilling, Patrick Krauss
分类: cs.CL
发布日期: 2025-02-07
💡 一句话要点
探究大型语言模型中多词动词内部表征,揭示词汇和句法属性的编码方式。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多词动词 大型语言模型 内部表征 探测分类器 BERT 广义判别值 词汇句法属性
📋 核心要点
- 现有方法难以充分理解LLM如何编码多词动词的词汇和句法信息。
- 通过训练探测分类器分析BERT各层表征,研究模型对短语动词和介词动词的区分。
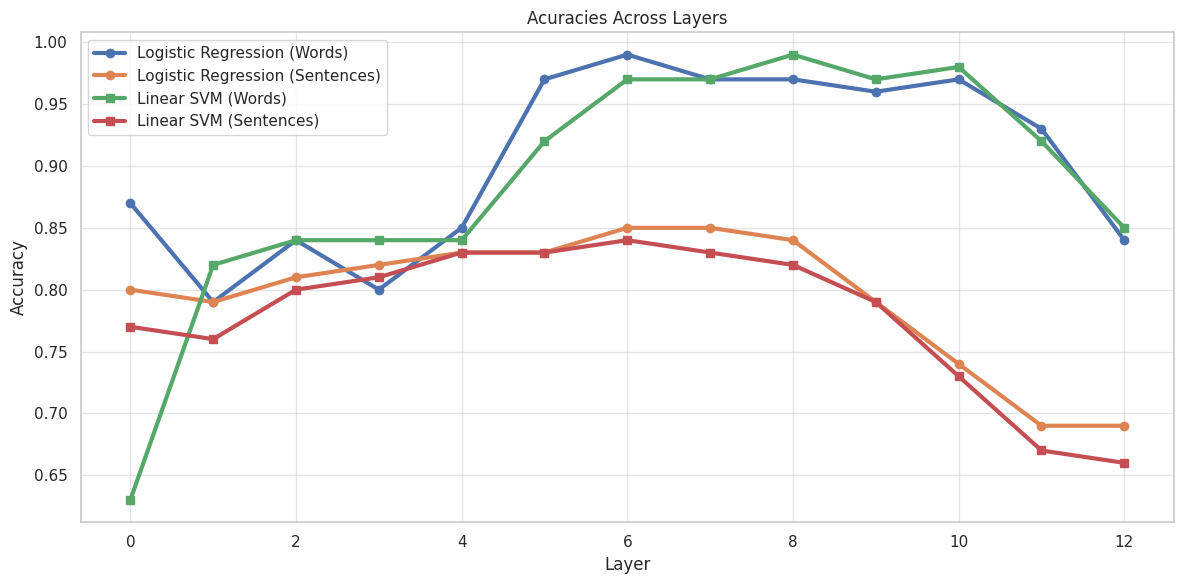
- 实验表明模型中间层分类准确率最高,且动词类型表征可能非线性可分。
📝 摘要(中文)
本研究旨在探究基于Transformer的大型语言模型(LLM)中动词短语(多词动词)的内部表征,特别是考察这些模型如何在不同的神经网络层捕捉词汇和句法属性。我们使用BERT架构,分析其各层对两种不同动词短语结构的表征:如'give up'这样的短语动词和如'look at'这样的介词动词。我们的方法包括训练探测分类器,基于内部表征在词和句子层面分类这些类别。结果表明,模型的中间层实现了最高的分类准确率。为了进一步分析这些区别的本质,我们使用广义判别值(GDV)进行数据可分性测试。虽然GDV结果显示这两种动词类型之间的线性可分性较弱,但探测分类器仍然实现了较高的准确率,这表明这些语言类别的表征可能以非线性方式可分。这与之前的研究一致,即神经网络中的语言区别并不总是以线性可分的方式编码。这些发现以计算方式支持了关于动词短语结构表征的基于用法的观点,并突出了神经网络架构和语言结构之间复杂的相互作用。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)如何表示和处理多词动词,特别是短语动词(如'give up')和介词动词(如'look at')。现有方法缺乏对LLM内部表征的深入理解,无法有效区分和解释不同类型多词动词的词汇和句法属性。
核心思路:论文的核心思路是通过训练探测分类器来分析LLM(具体为BERT)的内部表征。通过观察分类器在不同网络层的性能,推断模型在何处以及如何编码不同类型的多词动词。这种方法允许研究者无需修改模型本身,即可了解其内部运作机制。
技术框架:研究的技术框架主要包括以下几个步骤:1) 选择BERT模型作为研究对象。2) 准备包含短语动词和介词动词的语料库。3) 提取BERT各层的内部表征作为特征。4) 在这些特征上训练探测分类器,用于区分不同类型的多词动词。5) 使用广义判别值(GDV)评估数据可分性。
关键创新:论文的关键创新在于使用探测分类器和GDV分析相结合的方法,深入研究了LLM对多词动词的内部表征。与以往研究相比,该方法不仅关注模型的整体性能,更关注模型内部不同层级的表征能力,从而更细粒度地理解了LLM的语言处理机制。
关键设计:论文的关键设计包括:1) 选择BERT作为基础模型,因为它是一种广泛使用的、具有代表性的Transformer模型。2) 使用线性分类器作为探测器,以简化分析并避免引入额外的复杂性。3) 使用GDV来评估数据可分性,从而了解不同类型多词动词的表征是否线性可分。4) 在词级别和句子级别上进行分类,以考察模型在不同粒度上的表征能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,BERT模型的中间层在区分短语动词和介词动词方面表现最佳,分类准确率最高。GDV分析显示,这两种动词类型的表征线性可分性较弱,但探测分类器仍能达到较高准确率,表明模型可能以非线性方式编码这些语言区别。这些发现支持了关于动词短语结构表征的基于用法的观点。
🎯 应用场景
该研究成果可应用于提升自然语言处理任务中对多词动词的理解和生成能力,例如机器翻译、文本摘要和问答系统。通过更好地理解LLM如何处理多词动词,可以改进模型的设计和训练方法,从而提高其在各种语言任务中的性能。此外,该研究也有助于理解人类语言的认知过程。
📄 摘要(原文)
This study investigates the internal representations of verb-particle combinations, called multi-word verbs, within transformer-based large language models (LLMs), specifically examining how these models capture lexical and syntactic properties at different neural network layers. Using the BERT architecture, we analyze the representations of its layers for two different verb-particle constructions: phrasal verbs like 'give up' and prepositional verbs like 'look at'. Our methodology includes training probing classifiers on the internal representations to classify these categories at both word and sentence levels. The results indicate that the model's middle layers achieve the highest classification accuracies. To further analyze the nature of these distinctions, we conduct a data separability test using the Generalized Discrimination Value (GDV). While GDV results show weak linear separability between the two verb types, probing classifiers still achieve high accuracy, suggesting that representations of these linguistic categories may be non-linearly separable. This aligns with previous research indicating that linguistic distinctions in neural networks are not always encoded in a linearly separable manner. These findings computationally support usage-based claims on the representation of verb-particle constructions and highlight the complex interaction between neural network architectures and linguistic structures.