SeDi-Instruct: Enhancing Alignment of Language Models through Self-Directed Instruction Generation
作者: Jungwoo Kim, Minsang Kim, Sungjin Lee
分类: cs.CL
发布日期: 2025-02-07
备注: 12 pages, 12 figures
💡 一句话要点
提出SeDi-Instruct,通过自定向指令生成提升语言模型对齐效果。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 自定向学习 数据生成 大型语言模型 多样性过滤 迭代反馈 模型对齐
📋 核心要点
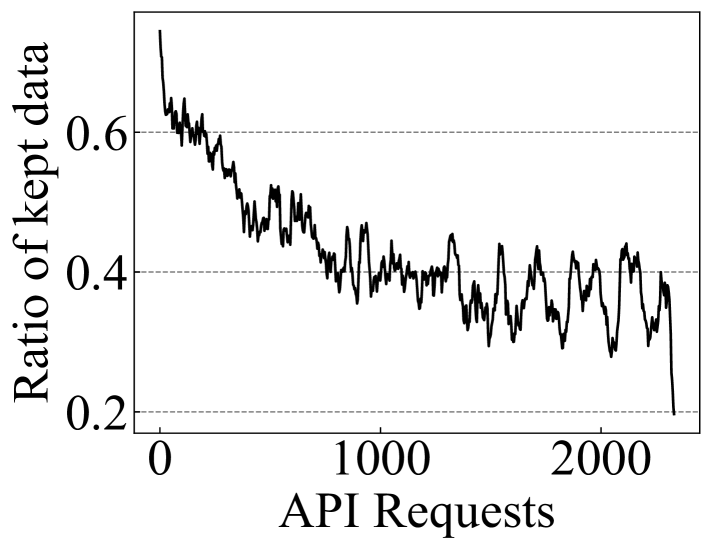
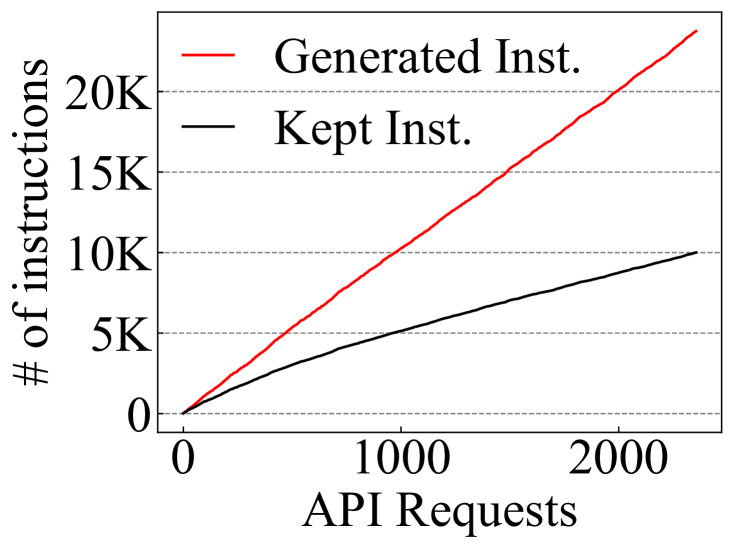
- 现有Self-Instruct方法在生成指令数据时效率较低,会丢弃大量数据,造成不必要的API调用成本。
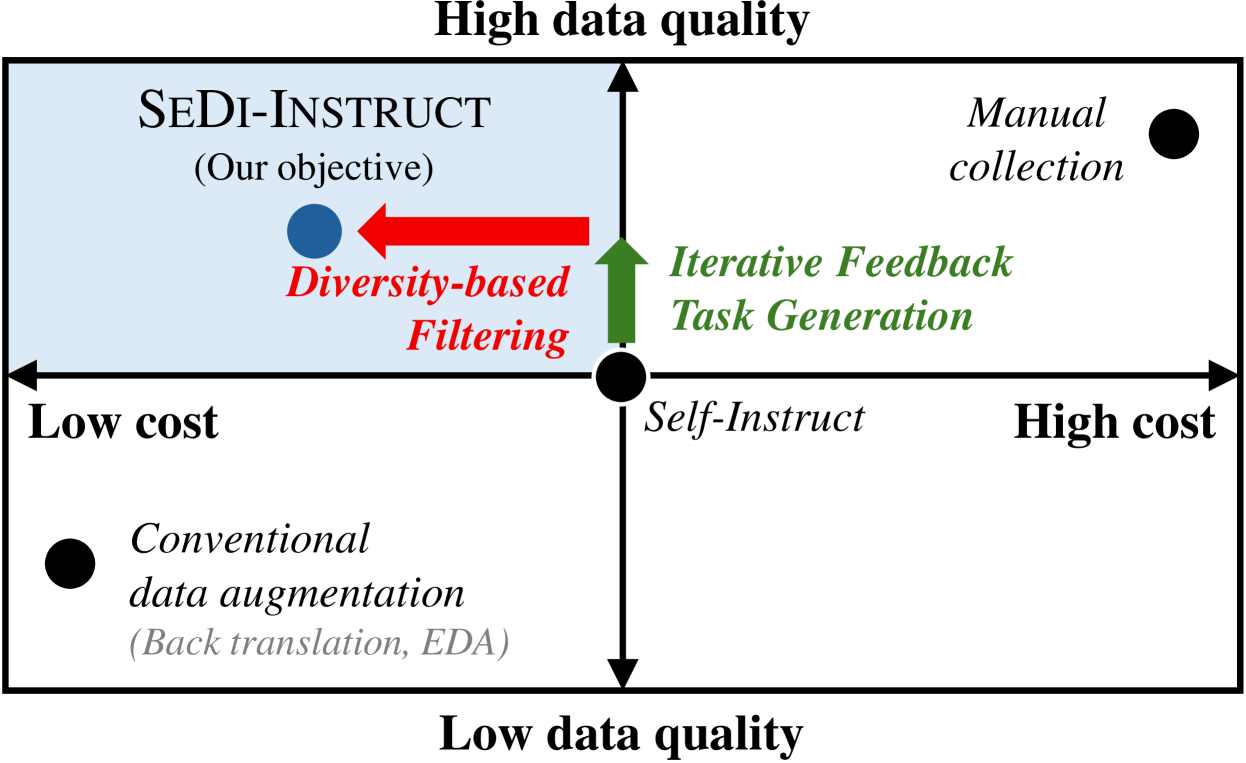
- SeDi-Instruct通过基于多样性的过滤和迭代反馈任务生成,以低成本生成高质量的指令数据。
- 实验结果表明,SeDi-Instruct在降低数据生成成本的同时,显著提升了AI模型的准确率。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展推动了各种基于AI的服务的开发。指令调优被认为是将基础模型适配到目标领域,从而为客户提供高质量服务的关键。指令调优的一个主要挑战是获取高质量的指令数据。Self-Instruct通过使用ChatGPT API自动生成指令数据,缓解了数据稀缺问题。为了提高指令数据的质量,Self-Instruct丢弃了许多从ChatGPT生成的指令,尽管这在成本方面是低效的,因为它需要多次无用的API调用。为了以低成本生成高质量的指令数据,我们提出了一种新颖的数据生成框架,即自定向指令生成(SeDi-Instruct),该框架采用基于多样性的过滤和迭代反馈任务生成。基于多样性的过滤通过增强批次中指令的多样性来维持模型精度,而不会过度丢弃低质量的生成指令。这降低了合成指令数据的成本。迭代反馈任务生成集成了指令生成和训练任务,并利用训练期间获得的信息来创建高质量的指令集。我们的结果表明,与传统方法相比,SeDi-Instruct将AI模型的准确率提高了5.2%,同时将数据生成成本降低了36%。
🔬 方法详解
问题定义:论文旨在解决指令调优中高质量指令数据获取成本高昂的问题。现有的Self-Instruct方法虽然能够自动生成指令数据,但为了保证数据质量,会丢弃大量生成的指令,导致API调用成本居高不下,效率较低。
核心思路:SeDi-Instruct的核心思路是通过两个关键技术来降低数据生成成本并提高数据质量:一是基于多样性的过滤,避免过度丢弃指令;二是迭代反馈任务生成,利用训练过程中的信息来指导指令生成,从而生成更有效的指令。
技术框架:SeDi-Instruct框架主要包含两个阶段:指令生成阶段和模型训练阶段。在指令生成阶段,首先使用LLM(如ChatGPT)生成一批指令数据,然后使用基于多样性的过滤方法筛选出具有代表性的指令子集。在模型训练阶段,使用筛选后的指令数据对模型进行训练,并利用训练过程中的信息(例如,模型在哪些指令上表现不佳)来指导下一轮的指令生成,形成迭代反馈。
关键创新:SeDi-Instruct的关键创新在于:1) 提出了基于多样性的过滤方法,能够在保证数据质量的同时,减少指令的丢弃,从而降低数据生成成本;2) 提出了迭代反馈任务生成机制,将指令生成和模型训练紧密结合,利用训练过程中的信息来指导指令生成,从而生成更有效的指令。
关键设计:在基于多样性的过滤中,可以使用例如余弦相似度等方法来衡量指令之间的相似性,并选择一批具有较高多样性的指令。在迭代反馈任务生成中,可以根据模型在训练集上的表现,生成更具挑战性的指令,以提高模型的泛化能力。具体的损失函数和网络结构取决于所使用的基础模型和目标任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SeDi-Instruct方法在提升模型准确率的同时,显著降低了数据生成成本。具体而言,与传统的Self-Instruct方法相比,SeDi-Instruct将AI模型的准确率提高了5.2%,同时将数据生成成本降低了36%。这些结果表明,SeDi-Instruct是一种高效且有效的指令数据生成方法。
🎯 应用场景
SeDi-Instruct方法可广泛应用于各种需要指令调优的场景,例如对话系统、文本生成、代码生成等。通过降低指令数据生成成本并提高数据质量,该方法可以帮助开发者更高效地训练出高性能的AI模型,从而提升AI服务的质量和用户体验。未来,该方法有望进一步扩展到其他类型的数据生成任务中。
📄 摘要(原文)
The rapid evolution of Large Language Models (LLMs) has enabled the industry to develop various AI-based services. Instruction tuning is considered essential in adapting foundation models for target domains to provide high-quality services to customers. A key challenge in instruction tuning is obtaining high-quality instruction data. Self-Instruct, which automatically generates instruction data using ChatGPT APIs, alleviates the data scarcity problem. To improve the quality of instruction data, Self-Instruct discards many of the instructions generated from ChatGPT, even though it is inefficient in terms of cost owing to many useless API calls. To generate high-quality instruction data at a low cost, we propose a novel data generation framework, Self-Direct Instruction generation (SeDi-Instruct), which employs diversity-based filtering and iterative feedback task generation. Diversity-based filtering maintains model accuracy without excessively discarding low-quality generated instructions by enhancing the diversity of instructions in a batch. This reduces the cost of synthesizing instruction data. The iterative feedback task generation integrates instruction generation and training tasks and utilizes information obtained during the training to create high-quality instruction sets. Our results show that SeDi-Instruct enhances the accuracy of AI models by 5.2%, compared with traditional methods, while reducing data generation costs by 36%.