Group-Adaptive Threshold Optimization for Robust AI-Generated Text Detection
作者: Minseok Jung, Cynthia Fuertes Panizo, Liam Dugan, Yi R., Fung, Pin-Yu Chen, Paul Pu Liang
分类: cs.CL, cs.LG
发布日期: 2025-02-06 (更新: 2025-09-27)
💡 一句话要点
提出FairOPT算法,通过群体自适应阈值优化提升AI生成文本检测的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成文本检测 群体自适应 阈值优化 公平性 鲁棒性
📋 核心要点
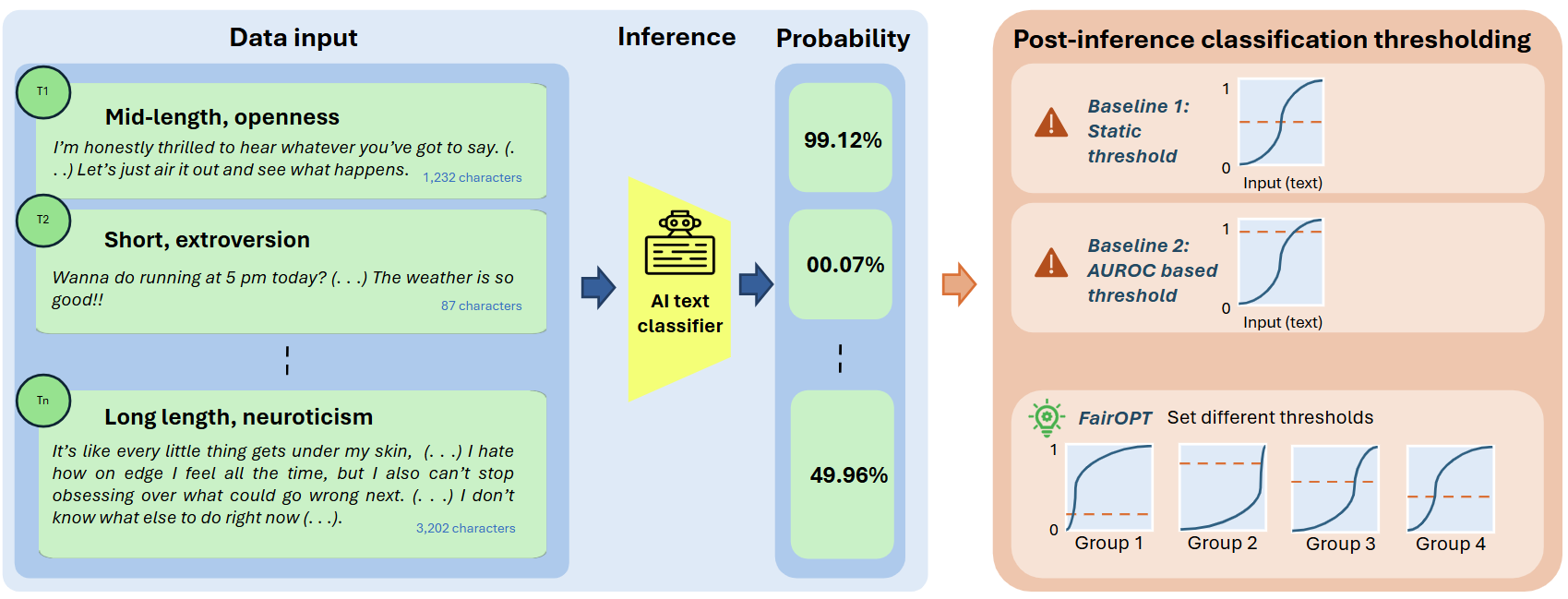
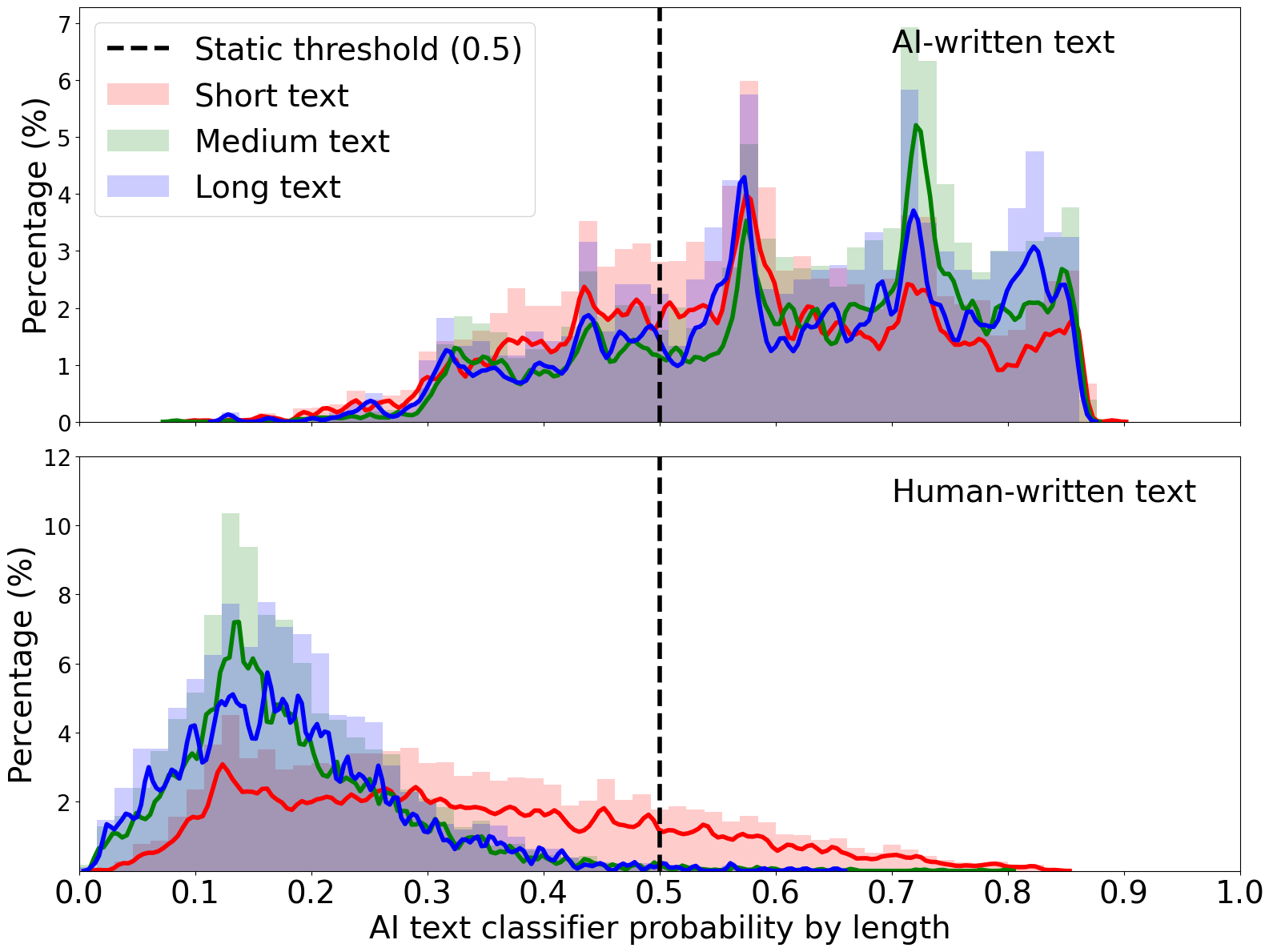
- 现有AI文本检测器使用固定全局阈值,忽略了不同文本群体(如不同长度、风格)的分布差异,导致对特定群体产生偏差。
- 论文提出FairOPT算法,通过将数据划分为子群体,并为每个群体学习特定的决策阈值,以减少检测差异。
- 实验结果表明,FairOPT在多个检测器和数据集上显著降低了群体间的差异性,同时对整体准确率的影响很小。
📝 摘要(中文)
大型语言模型(LLMs)的进步使得区分人类撰写的文本和AI生成的文本变得困难。为了应对这一挑战,开发了几种AI文本检测器,它们通常使用固定的全局阈值(例如,θ=0.5)来分类机器生成的文本。然而,一个通用的阈值可能无法解释子群体的分布差异。例如,当使用固定阈值时,检测器在较短的人类文本上产生更多的假阳性错误,并且在较长的文本中对神经质写作风格进行更多的阳性分类。这些差异可能导致错误分类,从而对某些群体产生不成比例的影响。我们通过引入FairOPT来解决这个关键限制,FairOPT是一种用于概率AI文本检测器的群体特定阈值优化算法。我们基于属性(例如,文本长度和写作风格)将数据划分为子群体,并实施FairOPT来学习每个群体的决策阈值,以减少差异。FairOPT在九个检测器和三个异构数据集上显示出显著的差异缓解,并通过在五个指标上减少27.4%的总体差异,同时以最小的0.005%的精度牺牲,显著缓解了minimax问题。我们的框架为通过后处理在AI生成内容检测中实现更强大的分类铺平了道路。我们在URL上发布我们的数据、代码和项目信息。
🔬 方法详解
问题定义:现有AI文本检测器通常采用固定的全局阈值来区分人类撰写的文本和AI生成的文本。这种方法忽略了不同文本群体(例如,不同长度、写作风格)之间的分布差异,导致在某些群体上产生更高的误判率,从而造成不公平的检测结果。例如,短文本更容易被误判为AI生成,而某些写作风格的文本也可能被错误地分类。
核心思路:论文的核心思路是为不同的文本群体(子群体)分别优化检测阈值,而不是使用单一的全局阈值。通过这种方式,可以更好地适应不同群体的特征,从而减少群体间的差异性,提高检测的公平性和鲁棒性。
技术框架:FairOPT算法首先将数据集划分为多个子群体,划分依据可以是文本长度、写作风格等属性。然后,针对每个子群体,FairOPT优化一个独立的决策阈值。优化的目标是最小化群体间的差异性,同时尽可能保持整体的检测准确率。整个框架可以作为现有AI文本检测器的后处理步骤,无需修改检测器本身。
关键创新:FairOPT的关键创新在于提出了群体自适应的阈值优化方法,打破了传统AI文本检测器使用固定全局阈值的局限。通过为每个群体学习特定的阈值,FairOPT能够更好地适应不同群体的特征,从而显著降低群体间的差异性,提高检测的公平性和鲁棒性。
关键设计:FairOPT算法的关键设计包括:1) 如何定义和划分文本子群体;2) 如何选择合适的差异性度量指标;3) 如何设计优化算法来平衡群体差异性和整体准确率。论文中使用了多种属性(如文本长度、写作风格)来划分群体,并采用了多种差异性度量指标。优化算法的具体细节(如损失函数、优化器)在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片

📊 实验亮点
FairOPT算法在九个不同的AI文本检测器和三个异构数据集上进行了评估,实验结果表明,该算法能够显著降低群体间的差异性,在五个指标上平均降低了27.4%的差异,同时仅牺牲了0.005%的准确率。这表明FairOPT能够在很大程度上缓解minimax问题,提高AI文本检测的公平性和鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要区分AI生成文本和人类撰写文本的场景,例如:学术诚信检测、新闻真实性验证、社交媒体内容审核等。通过降低群体间的检测差异,可以避免对特定群体产生不公平的影响,提高AI文本检测的可靠性和公正性。未来,该方法可以扩展到其他AI生成内容的检测任务中。
📄 摘要(原文)
The advancement of large language models (LLMs) has made it difficult to differentiate human-written text from AI-generated text. Several AI-text detectors have been developed in response, which typically utilize a fixed global threshold (e.g., $θ= 0.5$) to classify machine-generated text. However, one universal threshold could fail to account for distributional variations by subgroups. For example, when using a fixed threshold, detectors make more false positive errors on shorter human-written text, and more positive classifications of neurotic writing styles among long texts. These discrepancies can lead to misclassifications that disproportionately affect certain groups. We address this critical limitation by introducing FairOPT, an algorithm for group-specific threshold optimization for probabilistic AI-text detectors. We partitioned data into subgroups based on attributes (e.g., text length and writing style) and implemented FairOPT to learn decision thresholds for each group to reduce discrepancy. FairOPT showed notable discrepancy mitigation across nine detectors and three heterogeneous datasets, and the remarkable mitigation of the minimax problem by decreasing overall discrepancy 27.4% across five metrics while minimally sacrificing accuracy by 0.005%. Our framework paves the way for more robust classification in AI-generated content detection via post-processing. We release our data, code, and project information at URL.