Beyond Sample-Level Feedback: Using Reference-Level Feedback to Guide Data Synthesis
作者: Shuhaib Mehri, Xiusi Chen, Heng Ji, Dilek Hakkani-Tür
分类: cs.CL
发布日期: 2025-02-06 (更新: 2025-10-11)
💡 一句话要点
提出参考级别反馈,引导数据合成,提升指令微调LLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 数据合成 参考级别反馈 大型语言模型 AlpacaEval 数据增强
📋 核心要点
- 现有指令微调依赖高质量数据,但合成数据受限于生成模型的性能上限。
- 提出参考级别反馈,从参考样本提取特征,指导合成更高质量的指令-响应对。
- REFED数据集微调Llama-3.1-8B和Mistral-7B,在AlpacaEval 2.0上取得显著提升。
📝 摘要(中文)
高质量的指令微调数据对于开发能够有效处理真实世界任务并遵循人类指令的大型语言模型(LLMs)至关重要。虽然合成数据生成为创建此类数据集提供了一种可扩展的方法,但它存在一个质量上限,即在这些数据上训练的模型无法超越生成它的LLM。为了克服这个限制,我们引入了参考级别反馈,这是一种从精心策划的参考样本中提取理想特征,以指导合成更高质量的指令-响应对的范例。使用这种方法,我们合成了REFED,一个包含1万个指令-响应对的数据集。在REFED上微调Llama-3.1-8B-Instruct和Mistral-7B-Instruct,展示了在同等规模模型中的最先进性能,尤其是在AlpacaEval 2.0上达到了43.96%的长度控制胜率。大量的实验表明,参考级别反馈始终优于传统的样本级别反馈方法,可以推广到不同的模型架构,并以低成本生成高质量和多样化的数据。
🔬 方法详解
问题定义:论文旨在解决指令微调数据质量受限于生成模型自身能力的问题。现有方法,如样本级别反馈,无法有效突破这一瓶颈,导致训练后的模型性能难以超越数据生成模型。
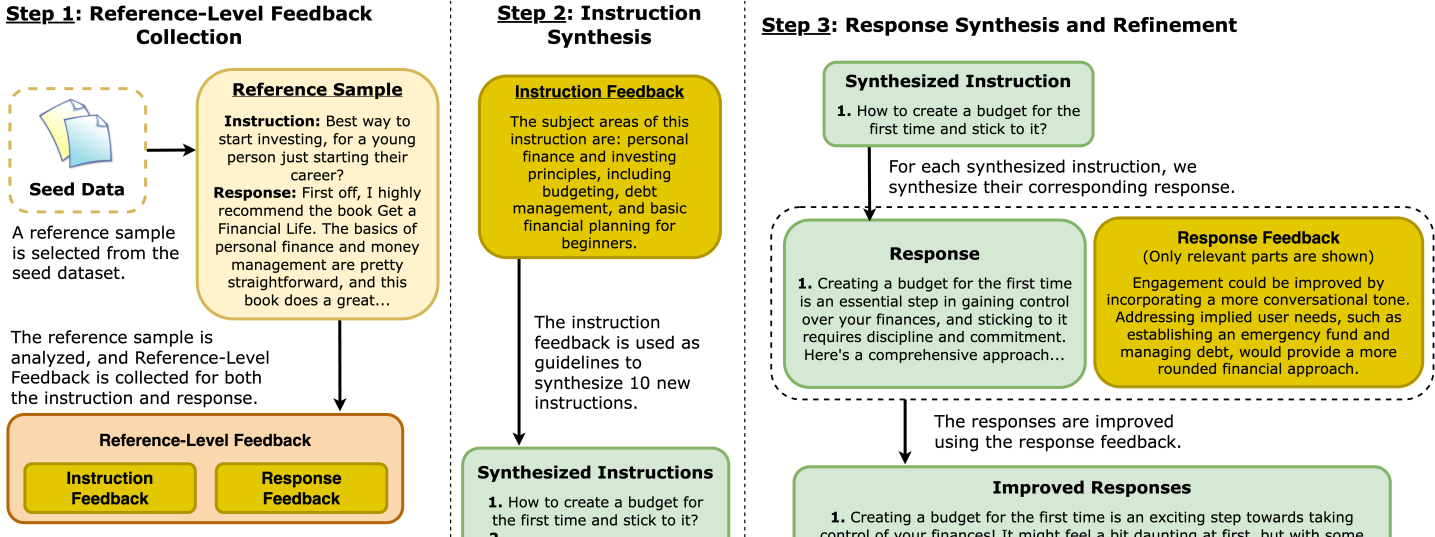
核心思路:核心思路是引入参考级别反馈,即利用人工精心挑选的参考样本,提取其内在的、理想的特征,并将这些特征作为指导信号,用于合成更高质量的指令-响应对。这样设计的目的是让合成数据能够学习到超越生成模型本身能力的知识和模式。
技术框架:整体流程包括:1) 收集或构建高质量的参考样本集;2) 设计算法从参考样本中提取关键特征(例如,风格、内容、结构等);3) 利用提取的特征作为反馈信号,指导LLM生成新的指令-响应对;4) 将生成的指令-响应对添加到训练数据集中,用于微调目标LLM。
关键创新:最重要的创新点在于将反馈粒度从样本级别提升到参考级别。传统方法仅关注单个样本的质量,而参考级别反馈则关注如何从多个高质量参考样本中学习共性特征,并将这些特征迁移到新生成的数据中。这使得合成数据能够继承参考样本的优点,从而突破生成模型的性能限制。
关键设计:具体的技术细节可能包括:如何定义和提取参考样本的特征(例如,使用预训练语言模型提取语义特征,或使用规则引擎提取结构特征);如何将提取的特征融入到LLM的生成过程中(例如,作为条件输入、损失函数的一部分,或用于调整生成概率);以及如何平衡参考样本的特征和生成模型自身的知识。
🖼️ 关键图片

📊 实验亮点
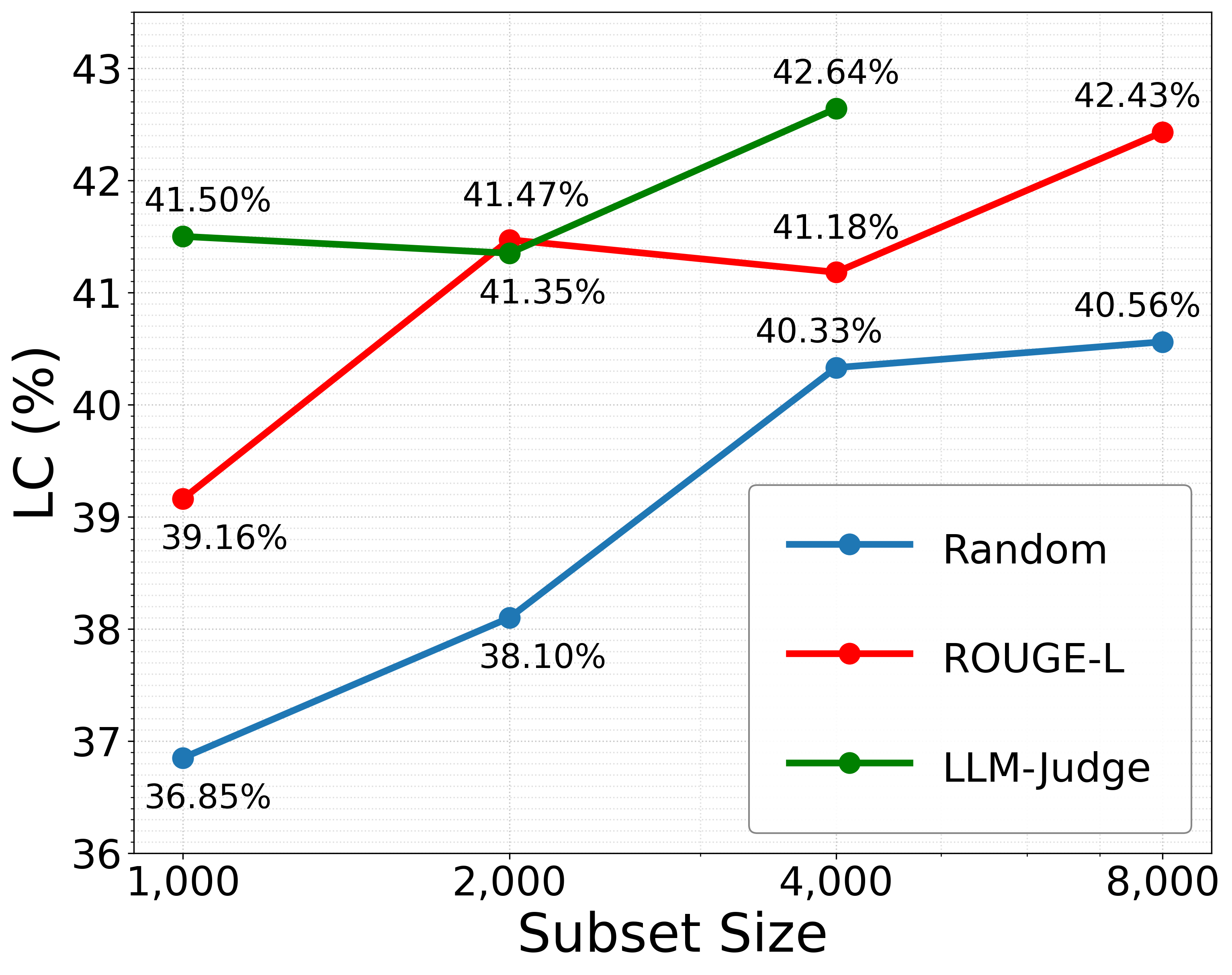
实验结果表明,在REFED数据集上微调Llama-3.1-8B-Instruct和Mistral-7B-Instruct,在AlpacaEval 2.0上达到了43.96%的长度控制胜率,显著优于其他同等规模的模型。这证明了参考级别反馈在提升指令微调数据质量方面的有效性,并且该方法具有良好的泛化能力,可以应用于不同的模型架构。
🎯 应用场景
该研究成果可广泛应用于各种需要高质量指令微调数据的场景,例如对话系统、智能助手、代码生成等。通过参考级别反馈,可以低成本地生成大量高质量的训练数据,从而提升LLM在特定任务上的性能和泛化能力。未来,该方法有望进一步扩展到其他类型的数据合成任务中。
📄 摘要(原文)
High-quality instruction-tuning data is crucial for developing Large Language Models (LLMs) that can effectively navigate real-world tasks and follow human instructions. While synthetic data generation offers a scalable approach for creating such datasets, it imposes a quality ceiling where models trained on the data cannot outperform the LLM generating it. To overcome this limitation, we introduce Reference-Level Feedback, a paradigm that extracts desirable characteristics from carefully curated reference samples to guide the synthesis of higher-quality instruction-response pairs. Using this approach, we synthesize REFED, a dataset of 10K instruction-response pairs. Fine-tuning Llama-3.1-8B-Instruct and Mistral-7B-Instruct on REFED demonstrate state-of-the-art performance among similarly sized models, notably reaching a 43.96\% length-controlled win-rate on AlpacaEval 2.0. Extensive experiments demonstrate that Reference-Level Feedback consistently outperforms traditional sample-level feedback methods, generalizes across model architectures, and produces high-quality and diverse data at low cost.