Dynamic Optimizations of LLM Ensembles with Two-Stage Reinforcement Learning Agents
作者: Selim Furkan Tekin, Fatih Ilhan, Gaowen Liu, Ramana Rao Kompella, Ling Liu
分类: cs.CL
发布日期: 2025-02-06 (更新: 2025-10-13)
🔗 代码/项目: GITHUB
💡 一句话要点
提出RL-Focal,利用两阶段强化学习动态优化LLM集成,提升推理性能与鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 强化学习 集成学习 动态优化 误差多样性
📋 核心要点
- 现有方法难以在动态变化的环境中有效利用多个LLM,缺乏自适应性和鲁棒性。
- RL-Focal通过两阶段强化学习,动态选择和融合LLM,优化推理性能和误差多样性。
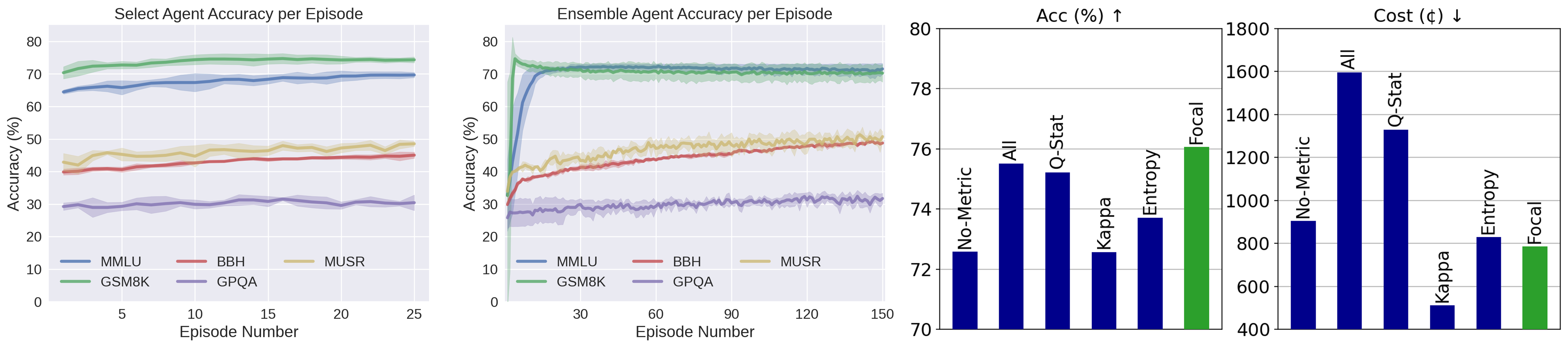
- 实验表明,RL-Focal在多个基准测试中优于最佳单模型,性能提升8.48%,鲁棒性更强。
📝 摘要(中文)
本文提出了一种名为RL-Focal的两阶段强化学习框架,用于路由和集成大型语言模型(LLM)。第一阶段,Decider RL-agent学习动态选择一个小型LLM集成(规模为$m_i$,远小于总数$N$),针对来自用户定义的下游任务$i$的查询,通过迭代更新任务自适应奖励和策略,最大化所选集成的误差多样性和推理性能。第二阶段,Fusion RL-agent学习解决来自不同LLM的推理冲突,并动态适应Decider Agent为不同下游任务组成的集成团队,从而实现对动态选择的LLM的有效融合。此外,本文引入了焦点多样性指标,以更好地建模多个LLM之间的误差相关性,进一步提高Decider Agent的泛化性能,从而主动修剪集成组合。通过焦点多样性,有效地促进了奖励感知和策略自适应的集成选择和推理融合,从而提高了跨任务的性能。在五个基准上的大量评估表明,与池中最佳的单个LLM相比,RL-Focal使用小型集成实现了8.48%的性能提升,并提供了更强的鲁棒性。代码可在https://github.com/sftekin/rl-focal获取。
🔬 方法详解
问题定义:论文旨在解决如何有效地利用多个LLM来提升下游任务的性能,同时降低计算成本。现有方法通常采用固定的LLM集成或简单的选择策略,无法根据任务的特性动态调整,导致性能瓶颈和资源浪费。此外,不同LLM之间可能存在推理冲突,如何有效融合这些冲突也是一个挑战。
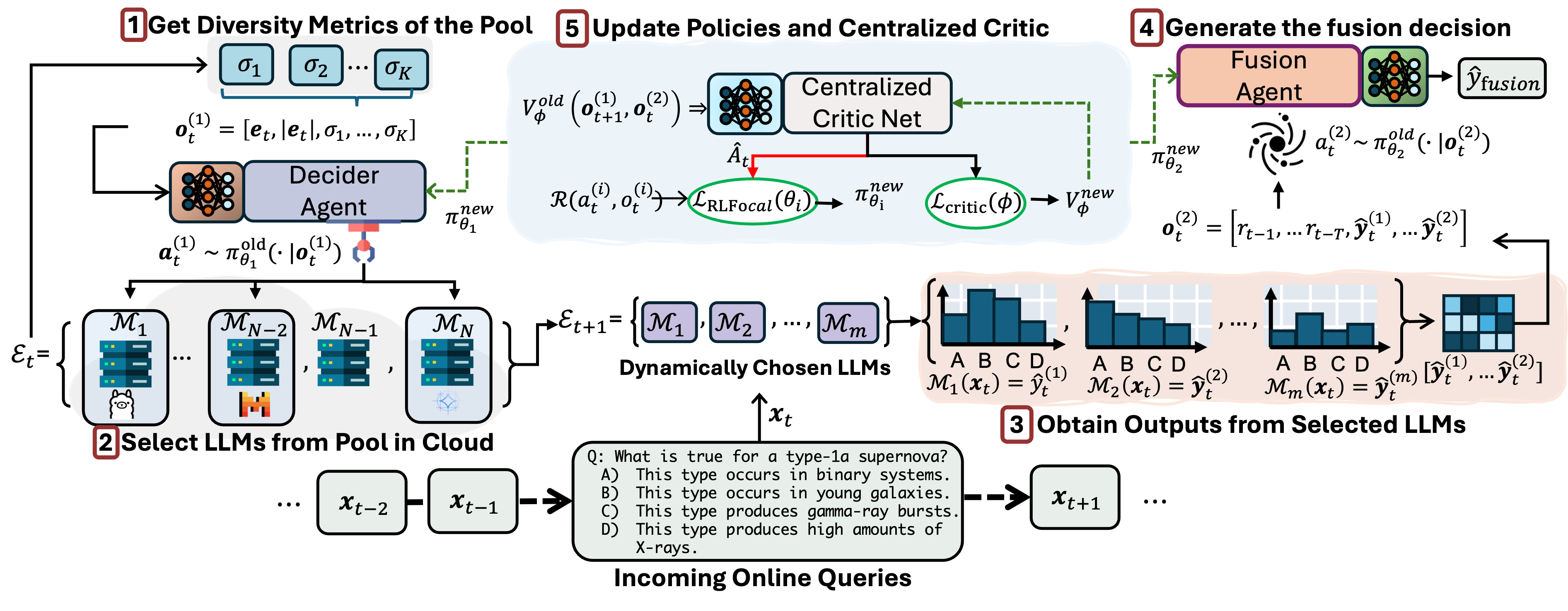
核心思路:论文的核心思路是利用强化学习来动态地选择和融合LLM。通过Decider Agent选择一个小型但具有高误差多样性的LLM子集,并通过Fusion Agent解决推理冲突,从而在保证性能的同时降低计算成本。这种动态调整的策略能够更好地适应不同任务的特性,提高整体的鲁棒性和泛化能力。
技术框架:RL-Focal框架包含两个主要阶段:Decider Agent和Fusion Agent。Decider Agent负责根据当前任务的特性,从所有可用的LLM中选择一个小型集成。Fusion Agent负责融合来自不同LLM的推理结果,解决可能存在的冲突。整个框架通过强化学习进行训练,目标是最大化下游任务的性能。
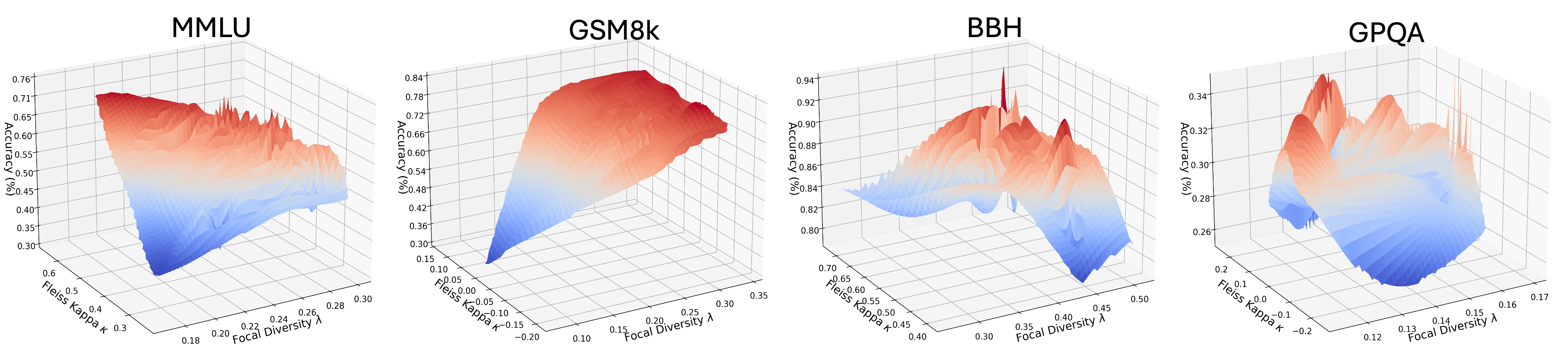
关键创新:论文的关键创新在于两点:一是提出了两阶段强化学习框架,将LLM的选择和融合解耦,分别进行优化;二是引入了焦点多样性指标,更好地建模LLM之间的误差相关性,从而提高Decider Agent的选择性能。与现有方法相比,RL-Focal能够更有效地利用多个LLM的优势,提高整体的性能和鲁棒性。
关键设计:Decider Agent使用深度Q网络(DQN)进行训练,状态空间包括任务的特征和LLM的性能指标,动作空间是选择不同的LLM组合。奖励函数的设计考虑了任务的准确率和集成的误差多样性。Fusion Agent使用注意力机制来融合不同LLM的推理结果,注意力权重根据LLM的置信度和一致性进行调整。焦点多样性指标通过计算LLM之间的误差相关性来衡量集成的多样性,并将其作为Decider Agent的奖励信号。
🖼️ 关键图片
📊 实验亮点
RL-Focal在五个基准测试中取得了显著的性能提升。与最佳的单个LLM相比,RL-Focal使用小型集成实现了8.48%的性能提升。此外,RL-Focal还表现出更强的鲁棒性,能够在不同的任务和数据集上保持稳定的性能。这些结果表明,RL-Focal是一种有效的LLM集成方法。
🎯 应用场景
RL-Focal可应用于各种需要利用多个LLM的场景,例如问答系统、文本摘要、机器翻译等。通过动态选择和融合LLM,可以提高系统的性能、鲁棒性和自适应性,同时降低计算成本。该研究对于构建更智能、更高效的AI系统具有重要意义。
📄 摘要(原文)
The advancement of LLMs and their accessibility have triggered renewed interest in multi-agent reinforcement learning as robust and adaptive frameworks for dynamically changing environments. This paper introduces RL-Focal, a two-stage RL agent framework that routes and ensembles LLMs. First, we develop the Decider RL-agent, which learns to dynamically select an ensemble of small size ($m_i$) among $N$ LLMs ($m_i \ll N$) for incoming queries from a user-defined downstream task $i$, by maximizing both error-diversity and reasoning-performance of the selected ensemble through iterative updates of task-adaptive rewards and policy. Second, to enable effective fusion of dynamically selected LLMs, we develop the stage-2 Fusion RL-agent, which learns to resolve reasoning conflicts from different LLMs and dynamically adapts to different ensemble teams composed by the Decider Agent for different downstream tasks. Third, we introduce the focal diversity metric to better model the error correlations among multiple LLMs, further improving the generalization performance of the Decider Agent, which actively prunes the ensemble combinations. By focal diversity, we enhance performance across tasks by effectively promoting reward-aware and policy-adaptive ensemble selection and inference fusion. Extensive evaluations on five benchmarks show that RL-Focal achieves the performance improvement of 8.48\% with an ensemble of small size compared to the best individual LLM in a pool and offers stronger robustness. Code is available at https://github.com/sftekin/rl-focal