The simulation of judgment in LLMs
作者: Edoardo Loru, Jacopo Nudo, Niccolò Di Marco, Alessandro Santirocchi, Roberto Atzeni, Matteo Cinelli, Vincenzo Cestari, Clelia Rossi-Arnaud, Walter Quattrociocchi
分类: cs.CL, cs.AI, cs.CY
发布日期: 2025-02-06 (更新: 2025-10-16)
备注: Please refer to published version: https://doi.org/10.1073/pnas.2518443122
期刊: Proc. Natl. Acad. Sci. U.S.A. 122 (42) e2518443122, 2025
💡 一句话要点
通过模拟LLM的判断过程,揭示其评估标准与人类的差异,并探讨潜在风险。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 评估标准 认知偏差 可信度判断 信息过滤
📋 核心要点
- 现有LLM在评估任务中表现出与人类不同的判断标准,可能导致偏差和不可靠性。
- 论文构建结构化代理框架,使LLM和人类遵循相同评估流程,从而直接比较二者差异。
- 实验表明LLM评估受词汇关联和统计先验影响,易混淆语言形式与认知可靠性,产生“认知错觉”。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被应用于评估过程,例如信息过滤、评估和解决知识差距,以及进行可信度判断。因此,有必要研究这些评估是如何构建的,它们依赖于哪些假设,以及它们的策略与人类的策略有何不同。本文将六个LLM与专家评级(NewsGuard和Media Bias/Fact Check)以及通过受控实验收集的人类判断进行基准测试。本文使用新闻领域作为评估任务的受控基准,重点关注底层机制,而不是新闻分类本身。为了实现直接比较,本文实现了一个结构化的代理框架,其中模型和非专业参与者遵循相同的评估程序:选择标准、检索内容和生成理由。研究结果表明,尽管输出结果一致,但在指导模型评估的可观察标准方面存在一致的差异,这表明词汇关联和统计先验可能会以不同于语境推理的方式影响评估。这种依赖性与系统性影响相关:政治不对称和混淆语言形式与认知可靠性的倾向——本文称之为“认知错觉”,即当表面上的合理性取代验证时出现的知识幻觉。事实上,将判断委托给此类系统可能会影响评估过程的启发式方法,表明从规范推理转向基于模式的近似,并引发关于LLM在评估过程中作用的开放性问题。
🔬 方法详解
问题定义:现有大型语言模型(LLM)在信息过滤、可信度判断等评估任务中被广泛应用,但其评估标准和过程与人类存在差异。现有方法缺乏对LLM评估机制的深入理解,难以发现潜在的偏差和风险。
核心思路:论文的核心思路是通过构建一个结构化的代理框架,使LLM和人类遵循相同的评估流程,从而直接比较二者在评估标准、推理过程和结果上的差异。通过这种方式,可以揭示LLM评估的内在机制,并识别潜在的偏差来源。
技术框架:论文构建了一个结构化的代理框架,包含以下三个主要阶段:1) 标准选择:参与者(LLM或人类)选择用于评估的标准(例如,准确性、偏见等)。2) 内容检索:根据所选标准,参与者检索相关内容。3) 理由生成:参与者根据检索到的内容和所选标准,生成评估的理由和结论。该框架允许对LLM和人类的评估过程进行直接比较。
关键创新:论文的关键创新在于:1) 构建了一个结构化的代理框架,实现了LLM和人类评估过程的直接比较。2) 揭示了LLM在评估过程中对词汇关联和统计先验的依赖,以及由此产生的“认知错觉”现象。3) 发现了LLM评估中的政治不对称性。
关键设计:论文的关键设计包括:1) 使用新闻领域作为评估任务的受控基准,以确保评估的客观性和可比性。2) 选择NewsGuard和Media Bias/Fact Check作为专家评级,以提供可靠的基准。3) 通过受控实验收集人类判断,以进行对比分析。4) 使用六个不同的LLM进行实验,以验证结果的普遍性。
🖼️ 关键图片
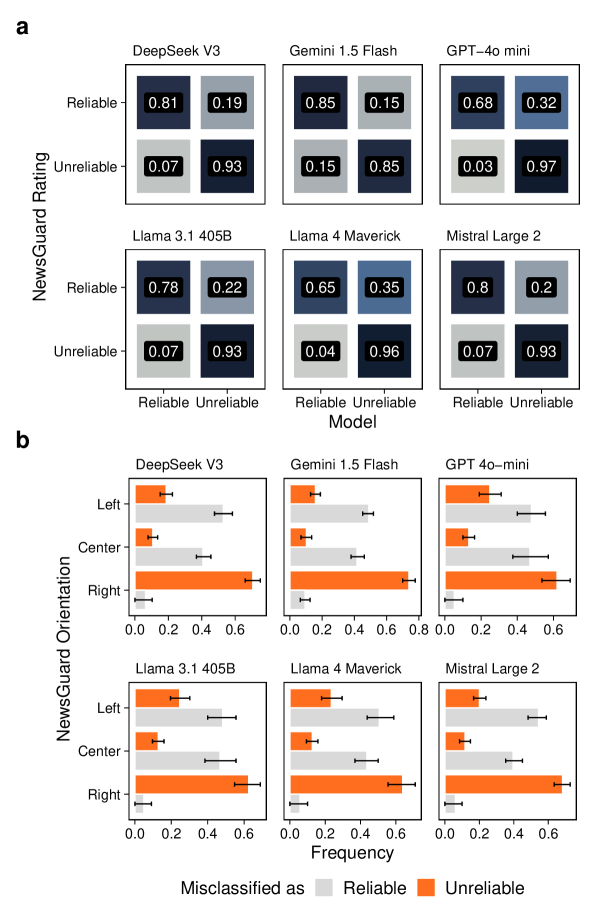
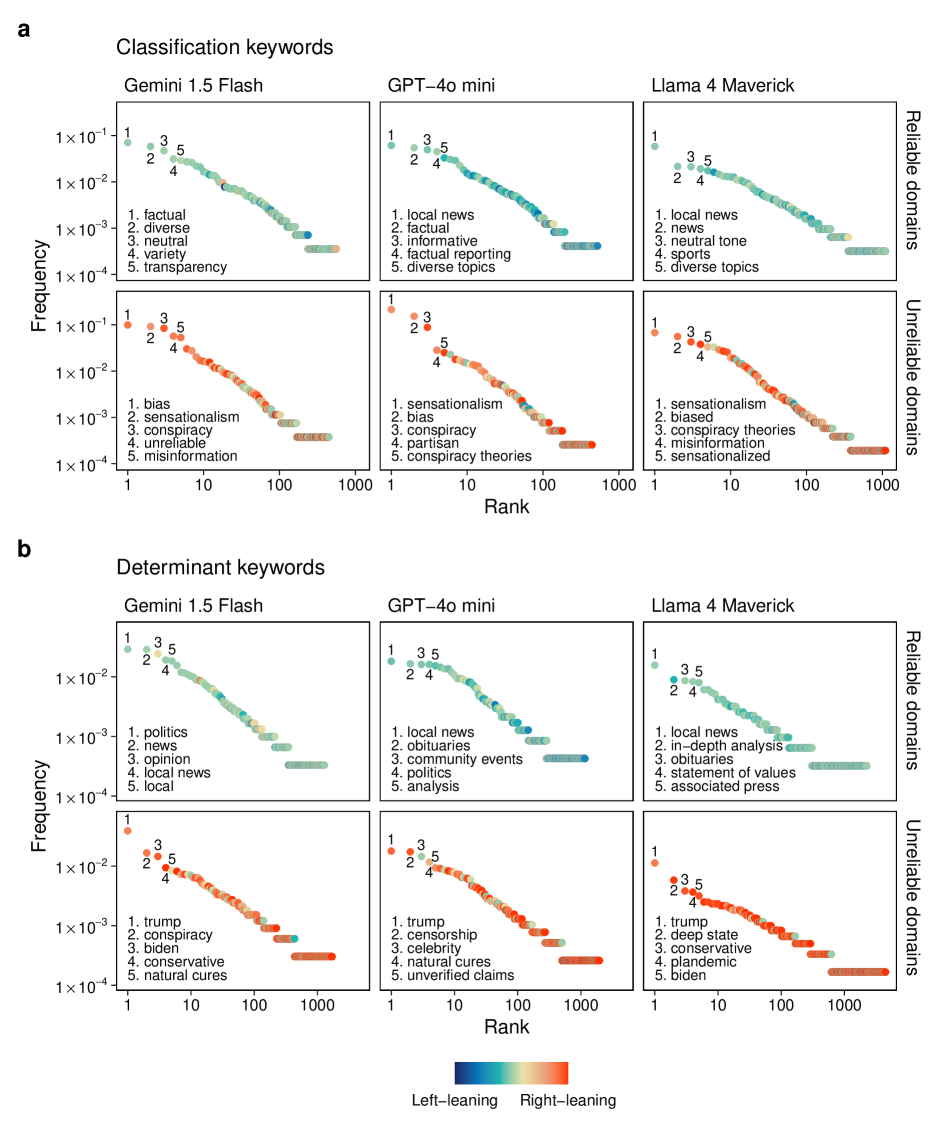

📊 实验亮点
实验结果表明,尽管LLM的输出结果与人类和专家评级在一定程度上对齐,但在评估标准上存在显著差异。LLM更依赖于词汇关联和统计先验,容易混淆语言形式与认知可靠性,产生“认知错觉”。此外,LLM的评估结果表现出政治不对称性,表明其评估过程可能受到潜在偏差的影响。
🎯 应用场景
该研究成果可应用于改进LLM的评估能力,减少其在信息过滤、可信度判断等任务中的偏差。此外,该研究有助于理解LLM的认知机制,为开发更可靠、更值得信赖的人工智能系统提供指导。未来,该研究可扩展到其他评估领域,例如医疗诊断、金融风险评估等。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly embedded in evaluative processes, from information filtering to assessing and addressing knowledge gaps through explanation and credibility judgments. This raises the need to examine how such evaluations are built, what assumptions they rely on, and how their strategies diverge from those of humans. We benchmark six LLMs against expert ratings--NewsGuard and Media Bias/Fact Check--and against human judgments collected through a controlled experiment. We use news domains purely as a controlled benchmark for evaluative tasks, focusing on the underlying mechanisms rather than on news classification per se. To enable direct comparison, we implement a structured agentic framework in which both models and nonexpert participants follow the same evaluation procedure: selecting criteria, retrieving content, and producing justifications. Despite output alignment, our findings show consistent differences in the observable criteria guiding model evaluations, suggesting that lexical associations and statistical priors could influence evaluations in ways that differ from contextual reasoning. This reliance is associated with systematic effects: political asymmetries and a tendency to confuse linguistic form with epistemic reliability--a dynamic we term epistemia, the illusion of knowledge that emerges when surface plausibility replaces verification. Indeed, delegating judgment to such systems may affect the heuristics underlying evaluative processes, suggesting a shift from normative reasoning toward pattern-based approximation and raising open questions about the role of LLMs in evaluative processes.