Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models
作者: Xiao-Wen Yang, Xuan-Yi Zhu, Wen-Da Wei, Ding-Chu Zhang, Jie-Jing Shao, Zhi Zhou, Lan-Zhe Guo, Yu-Feng Li
分类: cs.CL, cs.AI
发布日期: 2025-02-06
备注: This is a preprint under review, 15 pages, 13 figures
💡 一句话要点
提出自回溯机制,提升语言模型推理能力与效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 自回溯 搜索算法 人工智能
📋 核心要点
- 现有LLM推理存在过度思考和依赖奖励模型的问题,源于缺乏对搜索过程的内化。
- 提出自回溯机制,使LLM具备自主回溯能力,模拟传统搜索算法的关键操作。
- 实验表明,自回溯机制显著提升LLM推理能力,性能提升超过40%。
📝 摘要(中文)
本文提出了一种自回溯机制,旨在提升大型语言模型(LLMs)的推理能力。该机制使LLMs能够在训练和推理过程中自主决定何时以及如何回溯,从而克服了低效的过度思考和对辅助奖励模型的过度依赖等问题。通过将慢思考过程转化为快思考,该机制不仅增强了推理能力,还提高了效率。实验结果表明,与最优路径监督微调方法相比,该方法在推理能力上取得了超过40%的性能提升。这项研究为开发更先进和鲁棒的推理器提供了一种新颖且有前景的途径。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂推理任务中存在的效率和准确性问题。现有方法,如基于链式思考(Chain-of-Thought)的推理,常常导致过度思考,产生大量冗余或错误步骤,同时过度依赖外部奖励模型进行指导,限制了模型的自主性和泛化能力。
核心思路:论文的核心思路是赋予LLM自主回溯的能力,使其能够像人类专家一样,在推理过程中识别错误或无效的路径,并及时返回到之前的状态重新探索。这种自回溯机制模拟了传统搜索算法中的回溯操作,有助于模型更有效地探索解空间,避免陷入局部最优。
技术框架:该方法的核心在于设计一种自回溯机制,该机制在训练和推理阶段均可使用。在训练阶段,模型学习识别何时应该回溯,并学习如何回溯到更有希望的状态。在推理阶段,模型根据自身的状态和上下文信息,自主决定是否需要回溯。具体流程包括:1)模型生成推理步骤;2)模型评估当前步骤的有效性;3)如果评估结果表明当前路径不可行,则模型回溯到之前的状态;4)模型从回溯点继续生成新的推理步骤。
关键创新:最重要的技术创新点是LLM能够自主地进行回溯,而无需外部信号或人工干预。这与以往依赖奖励模型或人工标注进行监督学习的方法有本质区别。自回溯机制使得LLM能够更好地内化搜索过程,从而提高推理效率和准确性。
关键设计:论文可能涉及的关键设计包括:1)回溯策略:如何确定回溯的时机和回溯的步长;2)状态表示:如何表示LLM在推理过程中的状态,以便进行回溯;3)损失函数:如何设计损失函数,使得模型能够学习到有效的回溯策略。具体的参数设置、网络结构等技术细节未知,需要查阅论文全文。
🖼️ 关键图片


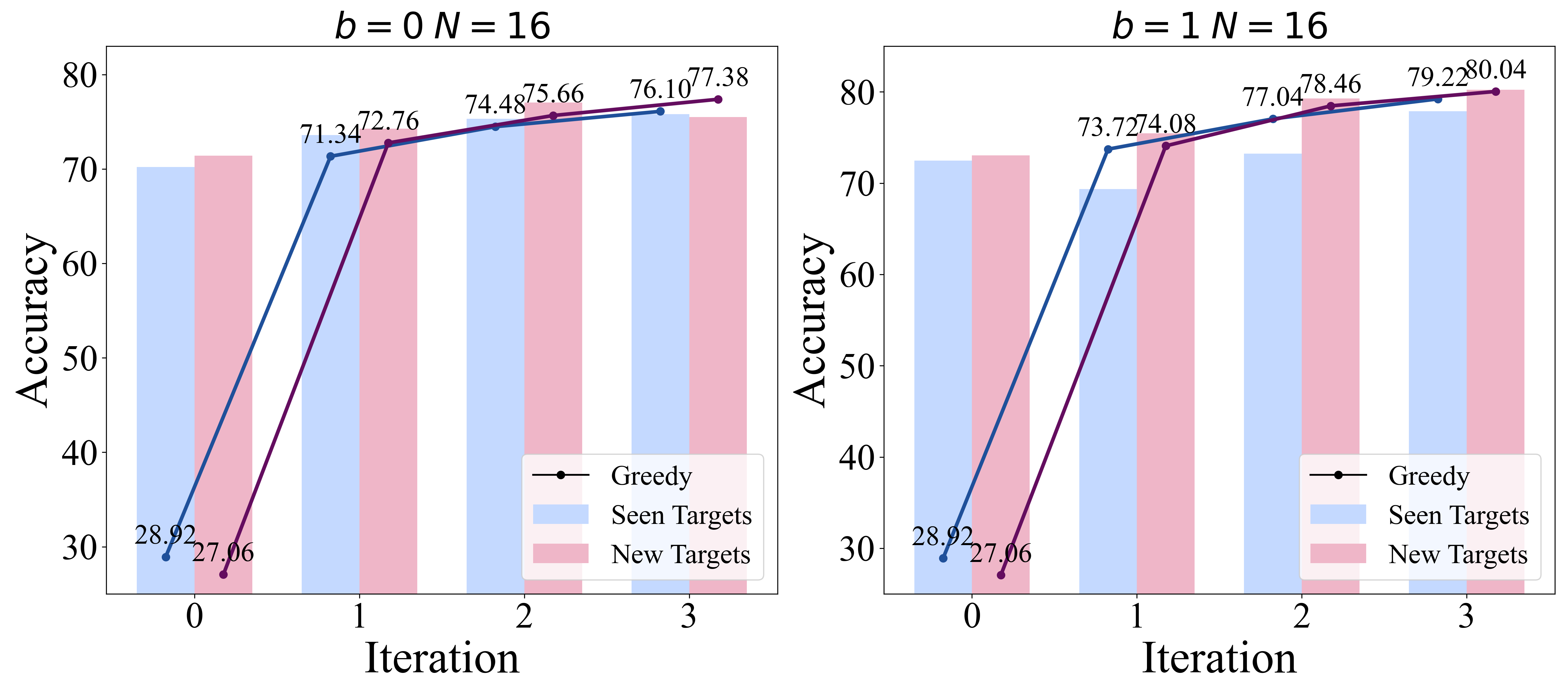
📊 实验亮点
实验结果表明,提出的自回溯机制能够显著提升LLM的推理能力,与最优路径监督微调方法相比,性能提升超过40%。这一显著的性能提升表明,自回溯机制是一种有效的提升LLM推理能力的方法,具有重要的研究和应用价值。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的场景,如问答系统、智能客服、代码生成、科学研究等。通过提升LLM的推理能力和效率,可以显著改善这些应用的用户体验和性能。未来,该技术有望推动通用人工智能的发展,使机器能够更好地理解和解决现实世界中的复杂问题。
📄 摘要(原文)
The integration of slow-thinking mechanisms into large language models (LLMs) offers a promising way toward achieving Level 2 AGI Reasoners, as exemplified by systems like OpenAI's o1. However, several significant challenges remain, including inefficient overthinking and an overreliance on auxiliary reward models. We point out that these limitations stem from LLMs' inability to internalize the search process, a key component of effective reasoning. A critical step toward addressing this issue is enabling LLMs to autonomously determine when and where to backtrack, a fundamental operation in traditional search algorithms. To this end, we propose a self-backtracking mechanism that equips LLMs with the ability to backtrack during both training and inference. This mechanism not only enhances reasoning ability but also efficiency by transforming slow-thinking processes into fast-thinking through self-improvement. Empirical evaluations demonstrate that our proposal significantly enhances the reasoning capabilities of LLMs, achieving a performance gain of over 40 percent compared to the optimal-path supervised fine-tuning method. We believe this study introduces a novel and promising pathway for developing more advanced and robust Reasoners.