The Best Instruction-Tuning Data are Those That Fit
作者: Dylan Zhang, Qirun Dai, Hao Peng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-06 (更新: 2026-01-11)
💡 一句话要点
GRAPE:针对目标模型特性优化指令微调数据选择,显著提升性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 数据选择 大型语言模型 预训练分布 监督式学习
📋 核心要点
- 现有指令微调方法常使用其他LLM生成的数据,这些数据与目标模型分布不匹配,导致性能瓶颈。
- GRAPE框架选择与目标模型预训练分布最匹配的响应进行微调,从而提高模型性能和鲁棒性。
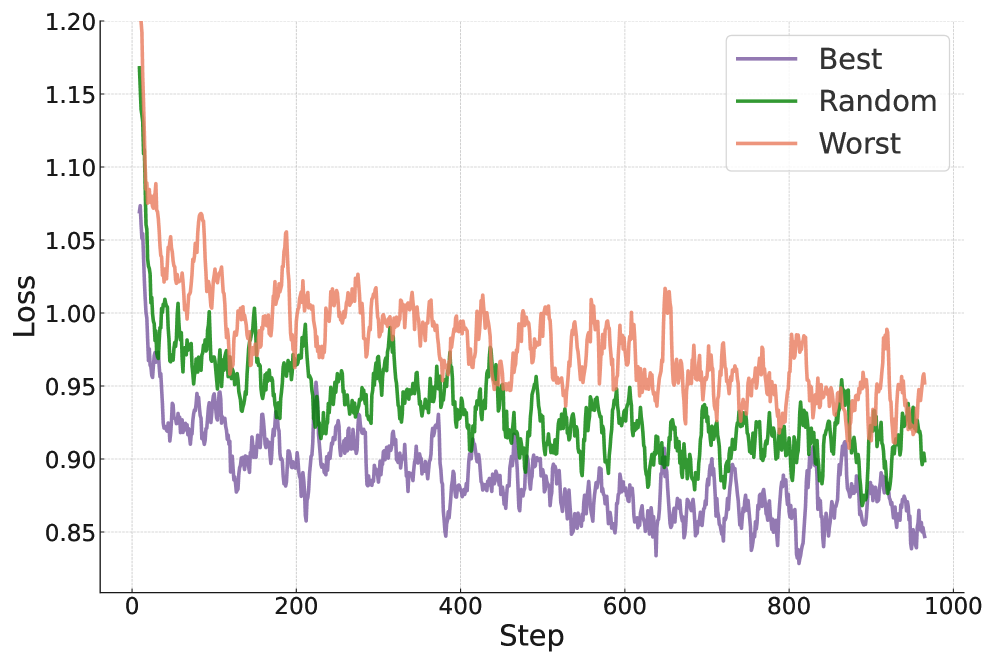
- 实验表明,GRAPE在多个基准测试中显著优于现有方法,最高提升达17.3%,且能用更少数据达到更优效果。
📝 摘要(中文)
高质量的监督式微调(SFT)数据对于激发预训练大型语言模型(LLM)的强大能力至关重要。通常,指令会与从其他LLM中抽样的多个响应配对,这些响应通常不在目标模型的分布范围内。大规模地这样做会导致收益递减,甚至损害模型的性能和鲁棒性。我们提出了GRAPE,一种新颖的SFT框架,它考虑了目标模型的独特特征。对于每个指令,它收集来自各种LLM的响应,并选择由目标模型测量的概率最高的响应,表明它与目标模型的预训练分布最紧密地对齐;然后进行标准的SFT训练。
🔬 方法详解
问题定义:现有指令微调方法依赖于从其他大型语言模型(LLM)采样得到的响应数据。然而,这些响应数据通常与目标微调模型的预训练分布存在差异,导致微调效果不佳,甚至损害模型的性能和鲁棒性。现有的数据选择方法未能充分考虑目标模型的特性,导致次优的数据选择结果。
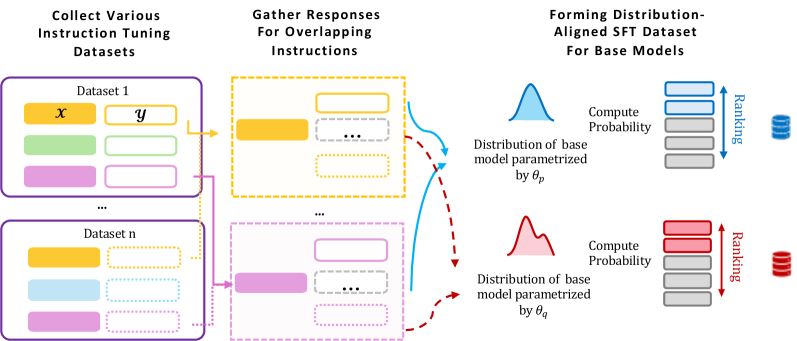
核心思路:GRAPE的核心思路是选择与目标模型预训练分布最接近的响应数据进行微调。具体来说,对于每个指令,GRAPE从多个LLM生成多个候选响应,然后使用目标模型评估每个响应的概率。选择概率最高的响应作为微调数据,因为该响应最符合目标模型的“口味”,从而能够更有效地提升模型性能。
技术框架:GRAPE框架主要包含以下几个步骤:1) 指令收集:收集用于微调的指令数据集。2) 响应生成:对于每个指令,使用多个不同的LLM生成多个候选响应。3) 响应评估:使用目标模型计算每个候选响应的概率。4) 数据选择:选择概率最高的响应作为微调数据。5) 标准SFT训练:使用选择的数据对目标模型进行标准的监督式微调。
关键创新:GRAPE的关键创新在于其数据选择策略。与传统的随机选择或基于其他模型的选择方法不同,GRAPE直接利用目标模型本身来评估和选择数据。这种方法能够更准确地选择与目标模型预训练分布相符的数据,从而提高微调效果。
关键设计:GRAPE的关键设计在于使用目标模型计算响应概率。具体来说,对于给定的指令和响应,GRAPE使用目标模型计算响应的对数似然(log-likelihood)。选择具有最高对数似然的响应作为微调数据。此外,GRAPE框架可以灵活地与各种预训练LLM和SFT训练方法结合使用。
🖼️ 关键图片

📊 实验亮点
GRAPE在UltraInteract数据集上的受控实验中,相较于最强的蒸馏基线,平均性能提升高达13.8%。在Tulu3和Olmo-2的真实场景实验中,GRAPE优于使用4.5倍数据的基线模型6.1%,并超越了最先进的数据选择方法3%。更令人瞩目的是,使用1/3的数据和一半的训练轮数,GRAPE使LLaMA3.1-8B的性能超越了Tulu3-SFT 3.5%。
🎯 应用场景
GRAPE框架可广泛应用于各种大型语言模型的指令微调任务,尤其适用于资源受限的场景,例如在计算资源有限的情况下,可以使用GRAPE选择更有效的数据子集进行微调,从而在保证性能的同时降低训练成本。该方法还可用于提升特定领域模型的性能,通过选择与领域相关的指令和响应数据进行微调,提高模型在特定领域的表现。
📄 摘要(原文)
High-quality supervised fine-tuning (SFT) data are crucial for eliciting strong capabilities from pretrained large language models (LLMs). Typically, instructions are paired with multiple responses sampled from other LLMs, which are often out of the distribution of the target model to be fine-tuned. This, at scale, can lead to diminishing returns and even hurt the models' performance and robustness. We propose GRAPE, a novel SFT framework that accounts for the unique characteristics of the target model. For each instruction, it gathers responses from various LLMs and selects the one with the highest probability measured by the target model, indicating that it aligns most closely with the target model's pretrained distribution; it then proceeds with standard SFT training. We first evaluate GRAPE with a controlled experiment, where we sample various solutions for each question in UltraInteract from multiple models and fine-tune commonly used LMs like LLaMA3.1-8B, Mistral-7B, and Qwen2.5-7B on GRAPE-selected data. GRAPE significantly outperforms strong baselines, including distilling from the strongest model with an absolute gain of up to 13.8%, averaged across benchmarks, and training on 3x more data with a maximum performance improvement of 17.3%. GRAPE's strong performance generalizes to realistic settings. We experiment with the post-training data used for Tulu3 and Olmo-2. GRAPE outperforms strong baselines trained on 4.5 times more data by 6.1% and a state-of-the-art data selection approach by 3% on average performance. Remarkably, using 1/3 of the data and half the number of epochs, GRAPE enables LLaMA3.1-8B to surpass the performance of Tulu3-SFT by 3.5%.