AttentionPredictor: Temporal Patterns Matter for KV Cache Compression
作者: Qingyue Yang, Jie Wang, Xing Li, Zhihai Wang, Chen Chen, Lei Chen, Xianzhi Yu, Wulong Liu, Jianye Hao, Mingxuan Yuan, Bin Li
分类: cs.CL, cs.LG
发布日期: 2025-02-06 (更新: 2025-10-26)
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出AttentionPredictor,通过预测注意力模式实现KV缓存压缩,提升长文本生成效率。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 注意力预测 长文本生成 大型语言模型 模型加速
📋 核心要点
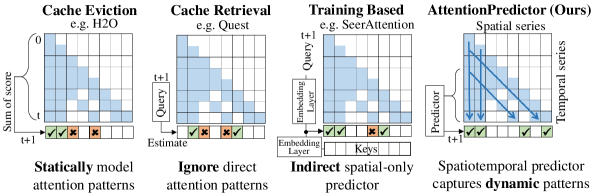
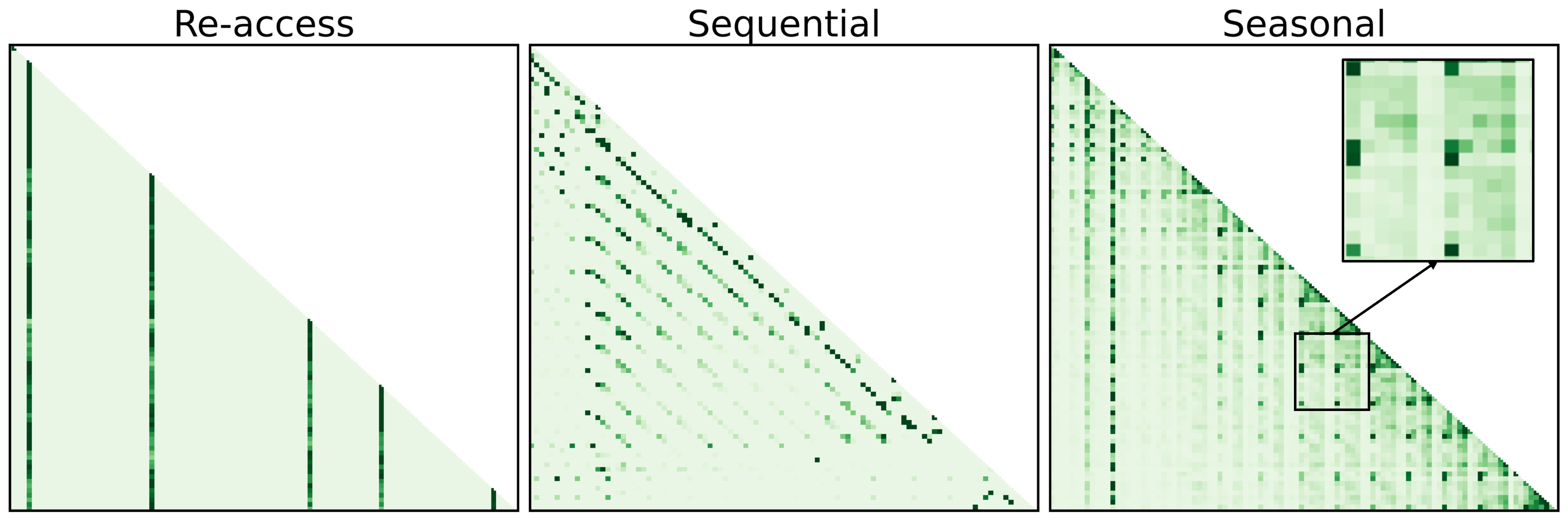
- 现有KV缓存压缩方法忽略了注意力分数的时序模式,导致关键token识别不准确,影响LLM性能。
- AttentionPredictor通过学习轻量级卷积模型,动态捕捉时空注意力模式,直接预测注意力分数。
- 实验表明,AttentionPredictor实现了13倍KV缓存压缩和5.6倍加速,同时保持了可比的LLM性能。
📝 摘要(中文)
随着大型语言模型(LLMs)的发展,通过Key-Value(KV)缓存压缩实现高效推理受到了广泛关注,尤其是在长文本生成方面。为了压缩KV缓存,现有方法通常通过静态建模注意力分数来识别关键的KV tokens。然而,这些方法忽略了注意力分数中的时序模式,导致无法准确确定关键tokens,进而造成LLM性能的显著下降。为了解决这一挑战,我们提出了AttentionPredictor,这是第一个基于学习的方法,可以直接预测注意力模式,用于KV缓存压缩和关键token识别。具体来说,AttentionPredictor学习一个轻量级的统一卷积模型,以动态捕捉时空模式并预测下一个token的注意力分数。AttentionPredictor的一个吸引人的特点是,它可以准确地预测注意力分数,并且在所有transformer层之间共享统一的预测模型,从而消耗极少的内存。此外,我们提出了一个跨token的关键缓存预取框架,该框架隐藏了token估计的时间开销,从而加速了解码阶段。通过保留大部分注意力信息,AttentionPredictor在缓存卸载场景中实现了13倍的KV缓存压缩和5.6倍的加速,同时保持了可比的LLM性能,显著优于现有技术。代码已在https://github.com/MIRALab-USTC/LLM-AttentionPredictor上发布。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中KV缓存过大,导致推理效率低下的问题。现有方法通过静态建模注意力分数来压缩KV缓存,但忽略了注意力分数的时序变化,导致关键token选择不准确,影响模型性能。
核心思路:论文的核心思路是利用一个轻量级的学习模型,直接预测未来token的注意力分数,从而更准确地识别关键token。通过预测注意力模式,可以动态地捕捉时空信息,避免静态建模的局限性。
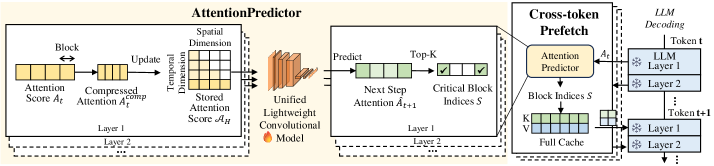
技术框架:AttentionPredictor包含一个轻量级的统一卷积模型,用于预测注意力分数。该模型在所有Transformer层之间共享,以减少内存消耗。此外,论文还提出了一个跨token的关键缓存预取框架,用于隐藏token估计的时间开销,加速解码过程。整体流程包括:输入token序列,使用卷积模型预测注意力分数,根据预测分数选择关键token,将关键token存储在KV缓存中,进行后续的解码过程。
关键创新:AttentionPredictor的关键创新在于它是第一个基于学习的方法,直接预测注意力模式用于KV缓存压缩。与现有方法相比,它能够动态地捕捉时空信息,更准确地识别关键token。此外,统一的预测模型和跨token预取框架也进一步提高了效率。
关键设计:AttentionPredictor使用卷积神经网络(CNN)作为预测模型,具体结构未知,但强调了轻量化设计。损失函数的设计目标是最小化预测注意力分数与真实注意力分数之间的差异,具体形式未知。跨token预取框架的具体实现细节未知,但其目标是隐藏token估计的时间开销。
🖼️ 关键图片
📊 实验亮点
AttentionPredictor在缓存卸载场景中实现了13倍的KV缓存压缩和5.6倍的加速,同时保持了与原始模型相当的性能。实验结果表明,AttentionPredictor显著优于现有的静态建模方法,能够在保证模型性能的前提下,大幅降低内存占用和提高推理速度。
🎯 应用场景
AttentionPredictor可应用于各种需要高效长文本生成的场景,例如机器翻译、文本摘要、对话系统等。通过降低KV缓存的内存占用和提高推理速度,该方法可以显著提升LLM在资源受限设备上的部署能力,并降低云计算成本。未来,该方法可以进一步扩展到其他类型的注意力机制和模型架构中。
📄 摘要(原文)
With the development of large language models (LLMs), efficient inference through Key-Value (KV) cache compression has attracted considerable attention, especially for long-context generation. To compress the KV cache, recent methods identify critical KV tokens through static modeling of attention scores. However, these methods often struggle to accurately determine critical tokens as they neglect the temporal patterns in attention scores, resulting in a noticeable degradation in LLM performance. To address this challenge, we propose AttentionPredictor, which is the first learning-based method to directly predict attention patterns for KV cache compression and critical token identification. Specifically, AttentionPredictor learns a lightweight, unified convolution model to dynamically capture spatiotemporal patterns and predict the next-token attention scores. An appealing feature of AttentionPredictor is that it accurately predicts the attention score and shares the unified prediction model, which consumes negligible memory, among all transformer layers. Moreover, we propose a cross-token critical cache prefetching framework that hides the token estimation time overhead to accelerate the decoding stage. By retaining most of the attention information, AttentionPredictor achieves 13$\times$ KV cache compression and 5.6$\times$ speedup in a cache offloading scenario with comparable LLM performance, significantly outperforming the state-of-the-arts. The code is available at https://github.com/MIRALab-USTC/LLM-AttentionPredictor.