BOLT: Bootstrap Long Chain-of-Thought in Language Models without Distillation
作者: Bo Pang, Hanze Dong, Jiacheng Xu, Silvio Savarese, Yingbo Zhou, Caiming Xiong
分类: cs.CL
发布日期: 2025-02-06
备注: 36 pages
💡 一句话要点
BOLT:无需蒸馏,引导语言模型生成长链式思考
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长链式思考 上下文学习 指令模型 监督微调 在线训练 推理能力 知识引导
📋 核心要点
- 现有方法依赖于从具有LongCoT能力的大模型蒸馏,成本高昂且缺乏系统性,限制了模型推理能力的提升。
- BOLT通过上下文学习从标准指令模型引导LongCoT,无需蒸馏或昂贵的人工标注,降低了训练成本。
- 实验表明,BOLT在多种基准测试上取得了显著的性能提升,证明了其在任务解决和推理能力方面的有效性。
📝 摘要(中文)
大型语言模型(LLM),如OpenAI的o1,展现了卓越的推理能力。o1在回答问题前会生成长链式思考(LongCoT),这使得LLM能够有效地分析问题、制定计划、反思和回溯,从而解决复杂问题。在o1发布后,许多团队试图复现其LongCoT和推理能力。然而,他们主要依赖于知识蒸馏,使用具有LongCoT能力的现有模型(如OpenAI-o1, Qwen-QwQ, DeepSeek-R1-Preview)的数据,这在系统性地发展这种推理能力方面存在很大的不确定性。此外,这些工作主要集中在数学领域,少数包括编码,限制了其泛化性。本文提出了一种新方法,无需从类似o1的模型中进行蒸馏或昂贵的人工标注,即可使LLM具备LongCoT能力。我们从标准的指令模型中引导LongCoT(BOLT)。BOLT包括三个阶段:1) 使用标准指令模型上的上下文学习进行LongCoT数据引导;2) LongCoT监督微调;3) 在线训练以进一步完善LongCoT能力。在BOLT中,引导阶段只需要构建少量的上下文示例;在我们的实验中,我们创建了10个示例,证明了该方法的可行性。我们使用Llama-3.1-70B-Instruct来引导LongCoT,并将我们的方法应用于各种模型规模(7B、8B、70B)。我们在各种基准测试(Arena-Hard、MT-Bench、WildBench、ZebraLogic、MATH500)上取得了令人印象深刻的性能,这些基准测试评估了各种任务解决和推理能力。
🔬 方法详解
问题定义:现有方法主要依赖于从类似 OpenAI-o1 这样的大型语言模型进行知识蒸馏来获得 LongCoT 能力,这种方法成本高昂,并且依赖于现有模型的质量。此外,现有方法在数据领域上主要集中在数学和编码等特定领域,缺乏通用性。因此,如何以更低成本、更通用的方式使语言模型具备 LongCoT 能力是一个关键问题。
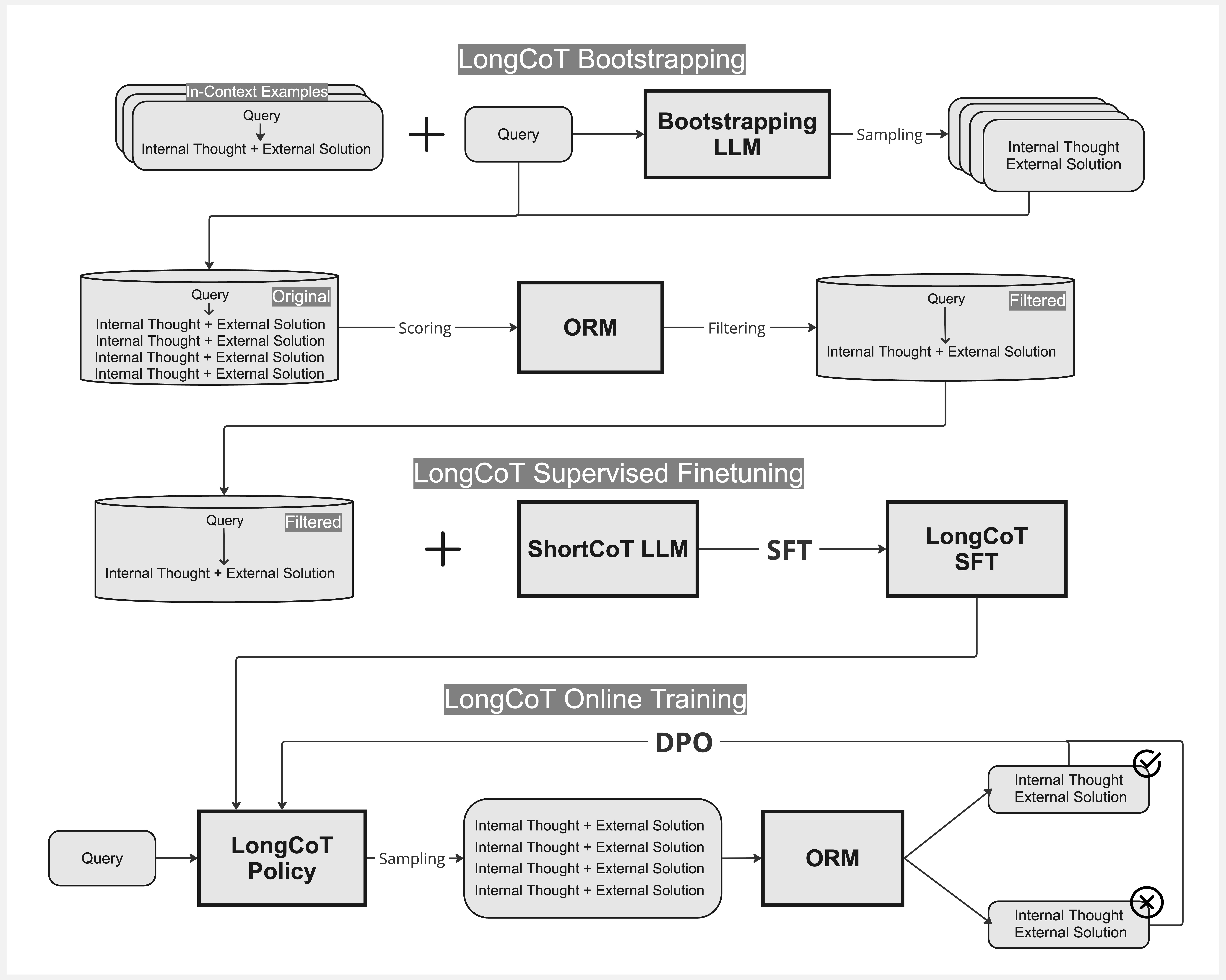
核心思路:BOLT 的核心思路是通过上下文学习(In-Context Learning)从一个标准的指令模型中引导出 LongCoT 能力,而无需依赖于大型模型的蒸馏。通过精心设计的少量上下文示例,引导模型生成 LongCoT 数据,然后使用这些数据进行监督微调,最后通过在线训练进一步提升 LongCoT 能力。这种方法降低了对高质量数据的依赖,并且可以应用于各种模型规模。
技术框架:BOLT 包含三个主要阶段: 1. LongCoT 数据引导:使用上下文学习,通过少量示例引导标准指令模型生成 LongCoT 数据。 2. LongCoT 监督微调:使用生成的数据对模型进行监督微调,使其具备 LongCoT 能力。 3. 在线训练:通过在线训练进一步优化 LongCoT 能力。
关键创新:BOLT 的关键创新在于它避免了对大型模型的蒸馏,而是通过上下文学习从标准指令模型中引导出 LongCoT 能力。这使得训练过程更加经济高效,并且可以应用于各种模型规模。与现有方法相比,BOLT 不需要依赖于现有模型的质量,而是通过自身学习来获得 LongCoT 能力。
关键设计:在 LongCoT 数据引导阶段,需要精心设计少量上下文示例,以引导模型生成高质量的 LongCoT 数据。在监督微调阶段,可以使用标准的交叉熵损失函数。在线训练阶段的具体细节(如奖励函数、训练策略等)在论文中可能没有详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
BOLT 方法在 Arena-Hard、MT-Bench、WildBench、ZebraLogic 和 MATH500 等多个基准测试上取得了令人印象深刻的性能。实验结果表明,BOLT 能够有效地提升语言模型的推理能力,使其在各种复杂任务中表现出色。具体性能数据和提升幅度需要在论文中查找,此处为未知信息。
🎯 应用场景
BOLT 方法可以广泛应用于需要复杂推理和问题解决能力的各种场景,例如智能客服、教育辅导、科学研究等。通过使语言模型具备 LongCoT 能力,可以提高其在复杂任务中的表现,并为用户提供更准确、更可靠的答案。该方法降低了训练成本,使得更多机构和个人能够训练出具有强大推理能力的语言模型。
📄 摘要(原文)
Large language models (LLMs), such as o1 from OpenAI, have demonstrated remarkable reasoning capabilities. o1 generates a long chain-of-thought (LongCoT) before answering a question. LongCoT allows LLMs to analyze problems, devise plans, reflect, and backtrack effectively. These actions empower LLM to solve complex problems. After the release of o1, many teams have attempted to replicate its LongCoT and reasoning capabilities. In terms of methods, they primarily rely on knowledge distillation with data from existing models with LongCoT capacities (e.g., OpenAI-o1, Qwen-QwQ, DeepSeek-R1-Preview), leaving significant uncertainties on systematically developing such reasoning abilities. In terms of data domains, these works focus narrowly on math while a few others include coding, limiting their generalizability. This paper introduces a novel approach to enable LLM's LongCoT capacity without distillation from o1-like models or expensive human annotations, where we bootstrap LongCoT (BOLT) from a standard instruct model. BOLT involves three stages: 1) LongCoT data bootstrapping with in-context learning on a standard instruct model; 2) LongCoT supervised finetuning; 3) online training to further refine LongCoT capacities. In BOLT, only a few in-context examples need to be constructed during the bootstrapping stage; in our experiments, we created 10 examples, demonstrating the feasibility of this approach. We use Llama-3.1-70B-Instruct to bootstrap LongCoT and apply our method to various model scales (7B, 8B, 70B). We achieve impressive performance on a variety of benchmarks, Arena-Hard, MT-Bench, WildBench, ZebraLogic, MATH500, which evaluate diverse task-solving and reasoning capabilities.