It's All in The [MASK]: Simple Instruction-Tuning Enables BERT-like Masked Language Models As Generative Classifiers
作者: Benjamin Clavié, Nathan Cooper, Benjamin Warner
分类: cs.CL, cs.AI
发布日期: 2025-02-06 (更新: 2025-02-10)
💡 一句话要点
提出ModernBERT-Large-Instruct,利用MLM头实现BERT类模型作为生成式分类器,提升零样本和微调性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 掩码语言模型 生成式分类 指令微调 BERT 自然语言理解 零样本学习 迁移学习
📋 核心要点
- 现有BERT等编码器模型依赖于特定任务的分类头,限制了其在生成式任务中的应用。
- 提出ModernBERT-Large-Instruct,利用MLM头进行生成式分类,简化训练和推理流程,无需复杂prompt工程。
- 实验表明,该模型在零样本和微调设置下均表现出色,在MMLU上接近Llama3-1B的性能,参数量更少。
📝 摘要(中文)
本文介绍了一种名为ModernBERT-Large-Instruct的0.4B参数的编码器模型,该模型利用其掩码语言建模(MLM)头进行生成式分类。该方法采用了一种简单直接的训练循环和推理机制,无需复杂的预处理、精心设计的提示或架构修改。ModernBERT-Large-Instruct在分类和基于知识的任务上表现出强大的零样本性能,在MMLU上优于同等规模的LLM,并以减少60%的参数实现了Llama3-1B的93%的MMLU性能。此外,实验表明,经过微调后,使用MLM头的生成方法在各种NLU任务中与传统的分类头方法相匹配甚至超越。这种能力主要出现在使用当代、多样化数据混合训练的模型中,而使用较低容量、较少多样性数据训练的模型性能明显较弱。初步结果表明,对于下游任务,使用原始生成式掩码语言建模头可能优于传统的特定任务头。这项工作表明,有必要进一步探索该领域,并强调了未来改进的许多途径。
🔬 方法详解
问题定义:现有BERT等encoder-only模型通常依赖于特定任务的分类头进行下游任务,这限制了它们在需要生成能力的场景下的应用。此外,为不同任务设计和训练不同的分类头增加了模型的复杂性和维护成本。因此,如何让BERT类模型具备更强的通用性和生成能力是一个重要的研究问题。
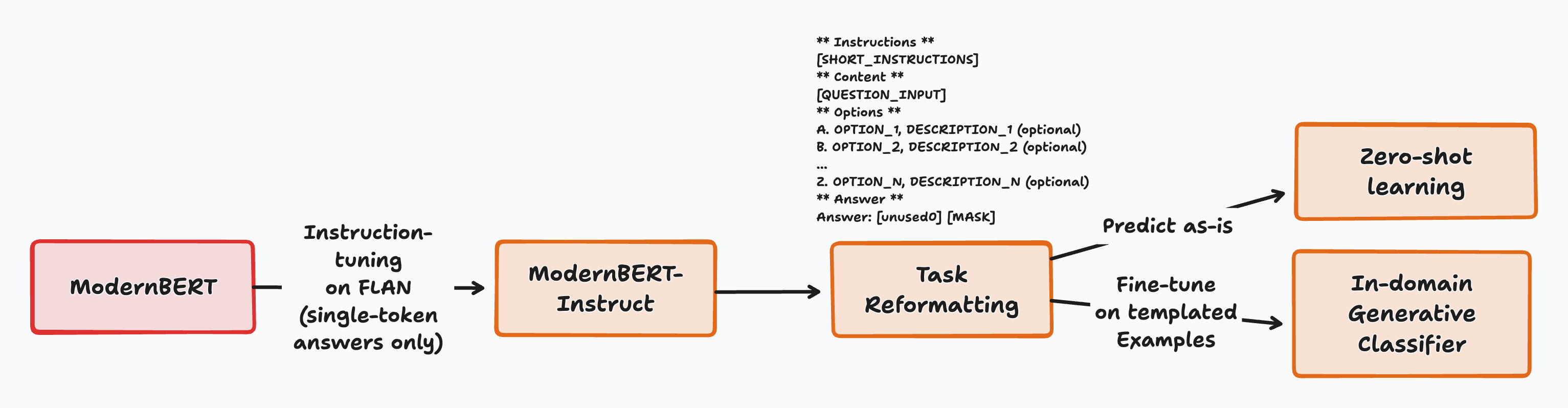
核心思路:本文的核心思路是利用BERT模型本身自带的Masked Language Modeling (MLM) 头,将其改造为生成式分类器。通过指令微调(instruction tuning)的方式,让模型学会根据输入指令,利用MLM头生成对应的类别标签,从而实现分类任务。这种方法避免了引入额外的分类头,简化了模型结构,并提升了模型的泛化能力。
技术框架:整体框架包括两个主要阶段:指令微调阶段和推理阶段。在指令微调阶段,使用包含指令和对应标签的数据集对模型进行训练,目标是让模型学会根据指令生成正确的标签。在推理阶段,给定输入指令,模型利用MLM头生成预测的标签。整个过程无需复杂的prompt工程或架构修改,保持了模型的简洁性。
关键创新:最重要的技术创新点在于将BERT类模型的MLM头用于生成式分类。与传统的分类头方法相比,这种方法更加通用,可以应用于各种不同的分类任务,而无需为每个任务单独训练分类头。此外,指令微调的方式使得模型能够更好地理解用户的意图,从而提升了模型的性能。
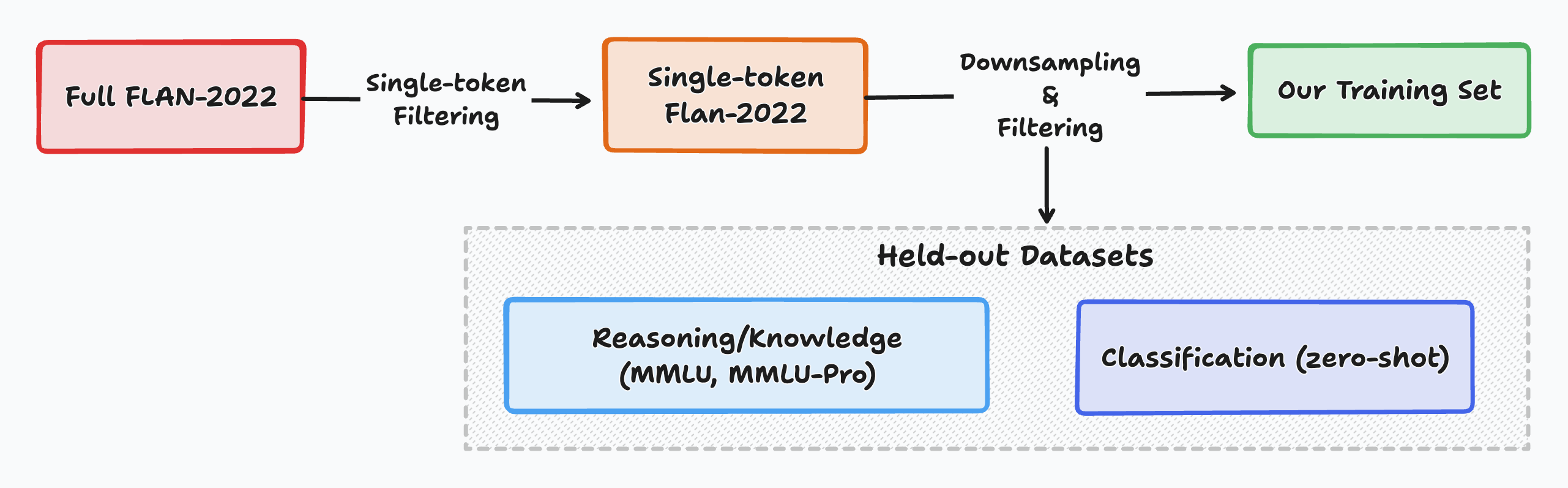
关键设计:关键设计包括:1) 使用简单直接的训练循环,避免复杂的预处理;2) 采用指令微调的方式,让模型学会根据指令生成标签;3) 选择合适的指令模板,例如“[MASK] is the answer.”,引导模型生成类别标签;4) 使用当代、多样化的数据集进行训练,提升模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
ModernBERT-Large-Instruct在MMLU基准测试中表现出色,在零样本设置下优于同等规模的LLM,并以更少的参数实现了Llama3-1B的93%的性能。经过微调后,该模型在各种NLU任务中与传统的分类头方法相匹配甚至超越。这些结果表明,利用MLM头进行生成式分类具有很大的潜力。
🎯 应用场景
该研究成果可应用于各种自然语言理解和生成任务,例如文本分类、情感分析、问答系统等。通过利用MLM头进行生成式分类,可以简化模型结构,提升模型的泛化能力,并降低模型的训练和维护成本。该方法在资源受限的场景下具有重要的应用价值,例如移动设备或嵌入式系统。
📄 摘要(原文)
While encoder-only models such as BERT and ModernBERT are ubiquitous in real-world NLP applications, their conventional reliance on task-specific classification heads can limit their applicability compared to decoder-based large language models (LLMs). In this work, we introduce ModernBERT-Large-Instruct, a 0.4B-parameter encoder model that leverages its masked language modelling (MLM) head for generative classification. Our approach employs an intentionally simple training loop and inference mechanism that requires no heavy pre-processing, heavily engineered prompting, or architectural modifications. ModernBERT-Large-Instruct exhibits strong zero-shot performance on both classification and knowledge-based tasks, outperforming similarly sized LLMs on MMLU and achieving 93% of Llama3-1B's MMLU performance with 60% less parameters. We also demonstrate that, when fine-tuned, the generative approach using the MLM head matches or even surpasses traditional classification-head methods across diverse NLU tasks.This capability emerges specifically in models trained on contemporary, diverse data mixes, with models trained on lower volume, less-diverse data yielding considerably weaker performance. Although preliminary, these results demonstrate the potential of using the original generative masked language modelling head over traditional task-specific heads for downstream tasks. Our work suggests that further exploration into this area is warranted, highlighting many avenues for future improvements.