A Comparison of DeepSeek and Other LLMs
作者: Tianchen Gao, Jiashun Jin, Zheng Tracy Ke, Gabriel Moryoussef
分类: cs.CL, cs.AI
发布日期: 2025-02-06 (更新: 2025-12-25)
备注: 30 pages, 7 figures, 9 tables
💡 一句话要点
对比DeepSeek与主流LLM在文本分类任务上的性能,并构建新数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM DeepSeek 文本分类 作者身份识别
📋 核心要点
- 现有LLM评测缺乏针对特定任务的细致对比,难以充分了解各模型优劣。
- 论文通过作者身份和引文分类任务,对比DeepSeek与主流LLM的性能差异。
- 实验表明DeepSeek在准确率上优于部分模型,但速度较慢,并构建了新的benchmark数据集。
📝 摘要(中文)
本文对比了DeepSeek与其他大型语言模型(LLM)的性能。研究选取了“使用短文本预测结果”的任务进行比较,具体包括作者身份分类和引文分类两个场景。作者身份分类旨在判断短文本是由人类还是AI撰写,引文分类则根据文本内容将引文归为四种类型之一。实验中,DeepSeek与Claude、Gemini、GPT和Llama这四个流行的LLM进行了比较。结果表明,在分类准确率方面,DeepSeek在大多数情况下优于Gemini、GPT和Llama,但不如Claude。DeepSeek的速度相对较慢,但使用成本较低,而Claude的成本远高于其他模型。此外,DeepSeek的输出与Gemini和Claude最为相似。本文还提出了一个完全标记的数据集,并提出了一种利用LLM和MADStat数据集生成新数据集的方法。这些数据集可作为未来LLM研究的基准。
🔬 方法详解
问题定义:论文旨在比较DeepSeek与其他主流LLM在特定文本分类任务上的性能差异。现有方法通常采用通用benchmark进行评估,难以针对特定应用场景进行细致分析,无法充分揭示各模型在不同任务上的优劣势。
核心思路:论文选取了“使用短文本预测结果”这一任务,并细化为作者身份分类和引文分类两个具体场景。通过在这两个场景下对比各LLM的性能,从而更深入地了解DeepSeek的特点。这种针对特定任务的比较方法能够更有效地评估LLM的实际应用能力。
技术框架:论文的整体框架包括以下几个步骤:1) 数据集构建:收集并标注用于作者身份分类和引文分类的数据集。2) 模型选择:选取DeepSeek以及Claude、Gemini、GPT和Llama这四个流行的LLM作为比较对象。3) 实验设置:针对每个任务,设计合理的实验流程和评估指标(如分类准确率)。4) 结果分析:对比各模型在不同任务上的性能表现,并分析其优缺点。5) 数据集生成:利用LLM和MADStat数据集生成新的数据集。
关键创新:论文的关键创新在于针对特定任务(即“使用短文本预测结果”)进行LLM性能比较,而非仅仅依赖于通用benchmark。此外,论文还提出了利用LLM和现有数据集生成新数据集的方法,为后续研究提供了更多的数据资源。
关键设计:论文的关键设计包括:1) 选取作者身份分类和引文分类作为具体的任务场景,这两个任务都涉及对短文本的理解和分类。2) 采用分类准确率作为主要的评估指标,能够直观地反映模型的性能。3) 对比各模型的速度和使用成本,从而更全面地评估其性价比。4) 分析各模型输出的相似性,从而了解它们在生成文本方面的特点。
🖼️ 关键图片
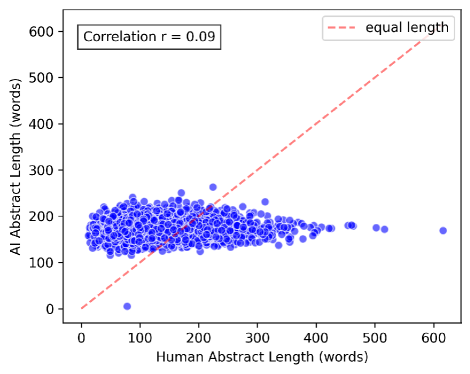
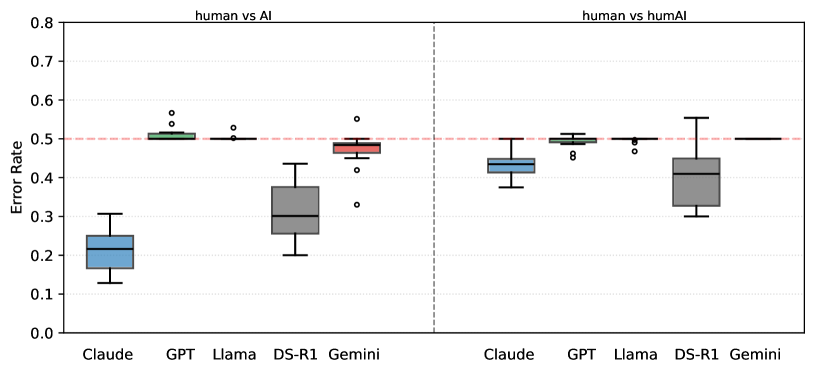
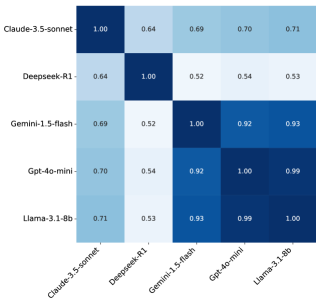
📊 实验亮点
实验结果表明,在分类准确率方面,DeepSeek在大多数情况下优于Gemini、GPT和Llama,但不如Claude。DeepSeek的速度相对较慢,但使用成本较低,而Claude的成本远高于其他模型。DeepSeek的输出与Gemini和Claude最为相似。
🎯 应用场景
该研究成果可应用于AI内容检测、学术文献分类等领域。通过对比不同LLM在特定任务上的性能,可以为用户选择合适的模型提供参考。此外,论文提出的数据集生成方法可以为LLM研究提供更多的数据资源,促进相关技术的发展。
📄 摘要(原文)
Recently, DeepSeek has been the focus of attention in and beyond the AI community. An interesting problem is how DeepSeek compares to other large language models (LLMs). There are many tasks an LLM can do, and in this paper, we use the task of "predicting an outcome using a short text" for comparison. We consider two settings, an authorship classification setting and a citation classification setting. In the first one, the goal is to determine whether a short text is written by human or AI. In the second one, the goal is to classify a citation to one of four types using the textual content. For each experiment, we compare DeepSeek with $4$ popular LLMs: Claude, Gemini, GPT, and Llama. We find that, in terms of classification accuracy, DeepSeek outperforms Gemini, GPT, and Llama in most cases, but underperforms Claude. We also find that DeepSeek is comparably slower than others but with a low cost to use, while Claude is much more expensive than all the others. Finally, we find that in terms of similarity, the output of DeepSeek is most similar to those of Gemini and Claude (and among all $5$ LLMs, Claude and Gemini have the most similar outputs). In this paper, we also present a fully-labeled dataset collected by ourselves, and propose a recipe where we can use the LLMs and a recent data set, MADStat, to generate new data sets. The datasets in our paper can be used as benchmarks for future study on LLMs.