Diversity as a Reward: Fine-Tuning LLMs on a Mixture of Domain-Undetermined Data
作者: Zhenqing Ling, Daoyuan Chen, Liuyi Yao, Qianli Shen, Yaliang Li, Ying Shen
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-05 (更新: 2025-10-30)
备注: Accepted by NeurIPS'25 main track. 47 pages, 21 figures, 32 tables
💡 一句话要点
提出基于多样性奖励的LLM微调方法,提升领域未定数据的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 数据多样性 领域自适应 对比学习
📋 核心要点
- 现有LLM微调方法在处理领域标签缺失或不准确的数据时,难以有效利用数据多样性。
- 论文提出一种新方法,利用LLM自身作为数据选择器,基于多样性奖励挑选数据进行微调。
- 实验结果表明,该方法显著提升了LLM在领域未定数据和下游任务上的性能。
📝 摘要(中文)
本文研究了数据多样性在提升大型语言模型(LLM)整体能力中的作用,尤其是在领域标签缺失、不精确或未归一化的数据场景下。现有方法通常依赖于数据组成的混合比例建模,或数据选择来平衡多领域性能,但在上述场景中表现不佳。为了解决这些挑战,我们通过构建对比数据池并进行理论推导,从经验上探讨了数据多样性的作用。在此基础上,我们提出了一种新方法,赋予LLM双重身份:一个输出模型,用于认知探测并基于多样性奖励选择数据;以及一个输入模型,用于使用所选数据进行微调。大量实验表明,该方法在应用于各种先进LLM时,显著提高了领域未定数据和一系列基础下游任务的性能。我们发布了代码,希望这项研究能够阐明对数据多样性的理解,并推进LLM的反馈驱动数据-模型协同设计。
🔬 方法详解
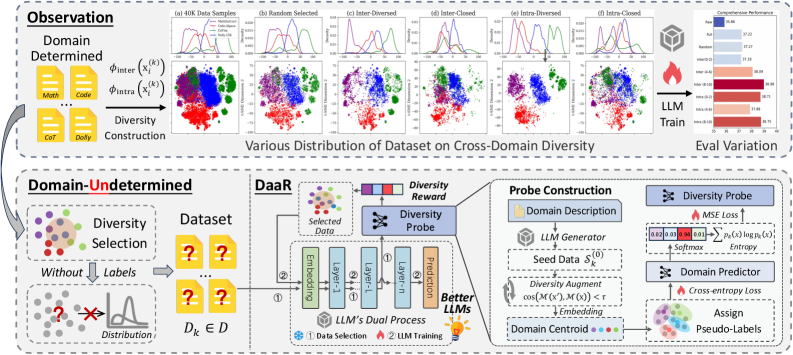
问题定义:论文旨在解决大型语言模型(LLM)在领域标签缺失、不精确或未归一化的数据上进行微调时,如何有效利用数据多样性的问题。现有方法,如基于混合比例建模或数据选择的方法,难以在这种情况下平衡多领域性能,导致模型泛化能力受限。
核心思路:论文的核心思路是利用LLM自身的能力来评估和选择具有多样性的数据。通过赋予LLM双重身份,使其既能作为输出模型评估数据的多样性,又能作为输入模型利用这些数据进行微调,从而实现数据和模型的协同优化。
技术框架:整体框架包含以下几个主要步骤:1) 构建对比数据池,包含各种领域和类型的数据;2) 使用LLM的输出模型对数据池中的数据进行认知探测,计算每个数据的多样性奖励;3) 基于多样性奖励选择数据子集;4) 使用所选数据对LLM的输入模型进行微调。这个过程可以迭代进行,不断优化数据选择和模型性能。
关键创新:最重要的创新点在于利用LLM自身来评估和选择数据,并引入了多样性奖励的概念。与传统的数据选择方法不同,该方法不是基于预定义的规则或标签,而是基于LLM对数据的理解和判断,从而能够更好地适应领域未定的数据。
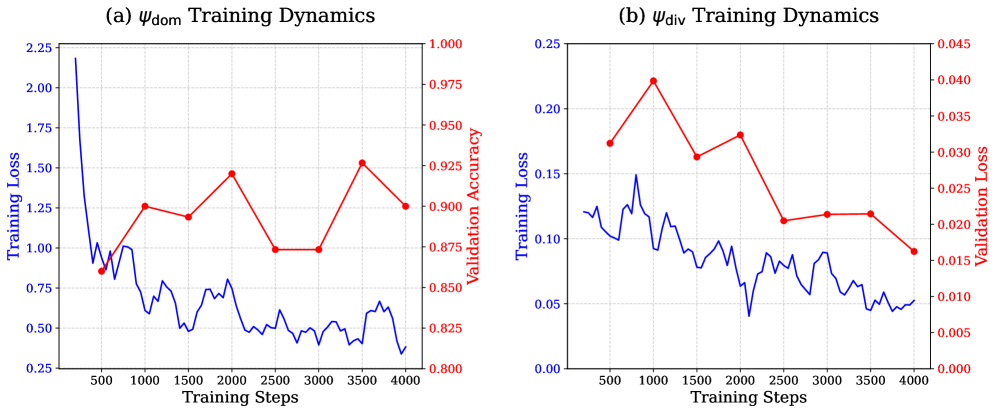
关键设计:关键设计包括:1) 多样性奖励的计算方式,例如可以使用LLM生成文本的概率分布的熵来衡量数据的信息量和多样性;2) 数据选择的策略,例如可以使用贪心算法或强化学习来选择能够最大化整体多样性奖励的数据子集;3) 微调过程中的超参数设置,例如学习率、batch size等,需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
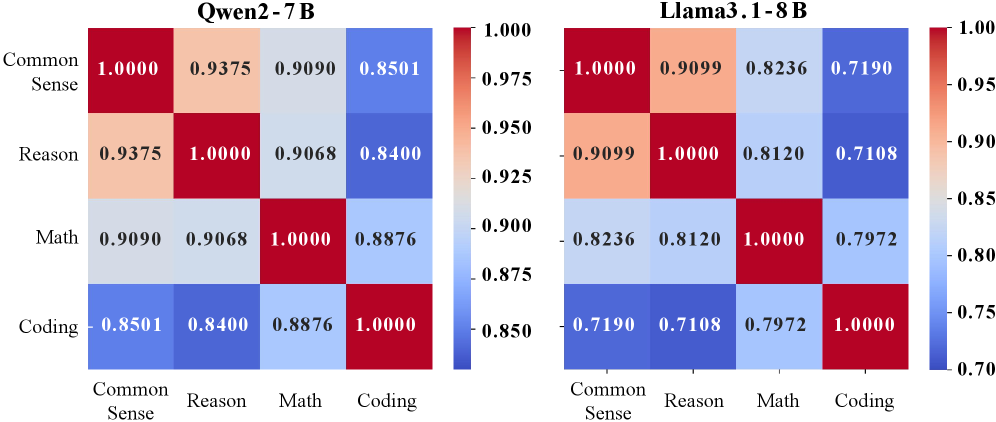
实验结果表明,该方法在领域未定数据上显著提升了LLM的性能。例如,在多个下游任务上,该方法相较于基线方法取得了明显的性能提升,具体提升幅度取决于任务类型和数据集。此外,实验还验证了该方法在不同规模和架构的LLM上的有效性。
🎯 应用场景
该研究成果可应用于各种需要利用大规模、领域未定数据进行LLM微调的场景,例如通用对话系统、信息检索、文本生成等。通过提升LLM在多样化数据上的泛化能力,可以显著改善其在实际应用中的性能和鲁棒性,并降低对数据标注的依赖。
📄 摘要(原文)
Fine-tuning large language models (LLMs) using diverse datasets is crucial for enhancing their overall performance across various domains. In practical scenarios, existing methods based on modeling the mixture proportions of data composition often struggle with data whose domain labels are missing, imprecise or non-normalized, while methods based on data selection usually encounter difficulties in balancing multi-domain performance. To address these challenges, in this work, we investigate the role of data diversity in enhancing the overall abilities of LLMs by empirically constructing contrastive data pools and theoretically deriving explanations. Building upon the insights gained, we propose a new method that gives the LLM a dual identity: an output model to cognitively probe and select data based on diversity reward, as well as an input model to be tuned with the selected data. Extensive experiments show that the proposed method notably boosts performance across domain-undetermined data and a series of foundational downstream tasks when applied to various advanced LLMs. We release our code and hope this study can shed light on the understanding of data diversity and advance feedback-driven data-model co-design for LLMs.