Advancing Reasoning in Large Language Models: Promising Methods and Approaches
作者: Avinash Patil, Aryan Jadon
分类: cs.CL, cs.AI
发布日期: 2025-02-05 (更新: 2025-05-28)
备注: 9 Pages, 1 Figure, IEEE Format
💡 一句话要点
综述大型语言模型推理能力提升方法,探索未来研究方向
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 思维链 提示工程 知识检索
📋 核心要点
- 大型语言模型在推理能力上存在不足,尤其是在逻辑、数学和常识推理等复杂任务中。
- 该综述对提升LLM推理能力的方法进行了分类,包括提示策略、架构创新和学习范式。
- 文章探讨了评估LLM推理能力的框架,并指出了幻觉、鲁棒性和泛化等方面的挑战。
📝 摘要(中文)
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中取得了显著成功,但其推理能力仍然是一个根本性的挑战。尽管LLMs表现出令人印象深刻的流畅性和事实回忆能力,但它们在执行复杂的推理(包括逻辑演绎、数学问题求解、常识推理和多步骤推理)方面的能力通常达不到人类的期望。本综述全面回顾了增强LLMs推理能力的新兴技术。我们将现有方法分为关键方法,包括提示策略(例如,思维链推理、自洽性和思维树推理)、架构创新(例如,检索增强模型、模块化推理网络和神经符号集成)和学习范式(例如,使用特定于推理的数据集进行微调、强化学习和自监督推理目标)。此外,我们还探讨了用于评估LLMs推理能力的评估框架,并强调了开放的挑战,例如幻觉、鲁棒性和跨不同任务的推理泛化。通过综合最近的进展,本综述旨在为推理增强型LLMs的未来研究和实际应用提供有希望的方向。
🔬 方法详解
问题定义:大型语言模型在复杂推理任务中表现不足,无法达到人类水平,尤其是在逻辑演绎、数学问题求解、常识推理和多步骤推理等任务上。现有方法在处理这些任务时,常常出现幻觉、缺乏鲁棒性,并且难以泛化到不同的任务领域。
核心思路:该综述的核心思路是对现有提升LLM推理能力的方法进行系统性地梳理和分类,从而为未来的研究提供指导。通过分析不同方法的优缺点,找出有前景的研究方向,并解决当前LLM推理能力面临的挑战。
技术框架:该综述没有提出新的技术框架,而是对现有技术进行了分类和总结。主要分为三个方面:1) 提示策略,例如思维链(Chain-of-Thought)、自洽性(Self-Consistency)和思维树(Tree-of-Thought);2) 架构创新,例如检索增强模型、模块化推理网络和神经符号集成;3) 学习范式,例如使用推理特定数据集进行微调、强化学习和自监督推理目标。
关键创新:该综述的创新之处在于对现有方法的系统性分类和总结,并指出了未来研究的潜在方向。它没有提出新的算法或模型,而是提供了一个全面的视角,帮助研究人员更好地理解LLM推理能力的现状和未来发展趋势。
关键设计:该综述没有涉及具体的技术细节,而是侧重于对现有方法的宏观分析和总结。因此,没有具体的参数设置、损失函数或网络结构等技术细节需要描述。
🖼️ 关键图片
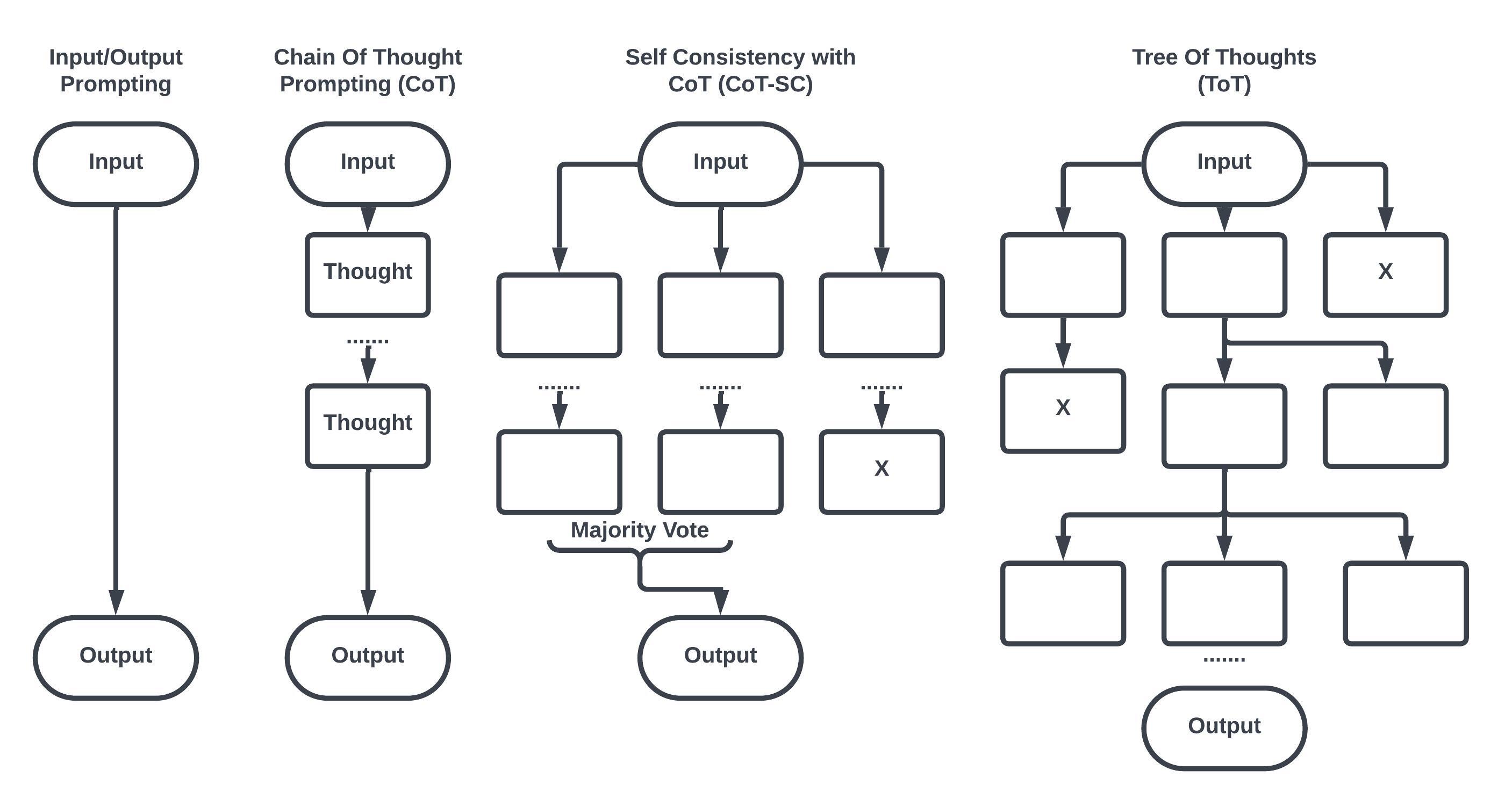
📊 实验亮点
该综述总结了多种提升LLM推理能力的方法,包括思维链、自洽性、检索增强、模块化推理网络等,并分析了它们的优缺点。文章还探讨了评估LLM推理能力的框架,并指出了幻觉、鲁棒性和泛化等方面的挑战,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于多个领域,例如智能问答系统、自动化推理引擎、智能客服和教育辅助工具。通过提升LLM的推理能力,可以使其在这些应用中表现得更加智能和可靠,从而提高工作效率和用户体验。未来的研究可以进一步探索如何将这些方法应用于更复杂的实际问题。
📄 摘要(原文)
Large Language Models (LLMs) have succeeded remarkably in various natural language processing (NLP) tasks, yet their reasoning capabilities remain a fundamental challenge. While LLMs exhibit impressive fluency and factual recall, their ability to perform complex reasoning-spanning logical deduction, mathematical problem-solving, commonsense inference, and multi-step reasoning-often falls short of human expectations. This survey provides a comprehensive review of emerging techniques enhancing reasoning in LLMs. We categorize existing methods into key approaches, including prompting strategies (e.g., Chain-of-Thought reasoning, Self-Consistency, and Tree-of-Thought reasoning), architectural innovations (e.g., retrieval-augmented models, modular reasoning networks, and neuro-symbolic integration), and learning paradigms (e.g., fine-tuning with reasoning-specific datasets, reinforcement learning, and self-supervised reasoning objectives). Additionally, we explore evaluation frameworks used to assess reasoning in LLMs and highlight open challenges, such as hallucinations, robustness, and reasoning generalization across diverse tasks. By synthesizing recent advancements, this survey aims to provide insights into promising directions for future research and practical applications of reasoning-augmented LLMs.