LIMO: Less is More for Reasoning
作者: Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, Pengfei Liu
分类: cs.CL, cs.AI
发布日期: 2025-02-05 (更新: 2025-07-29)
备注: COLM 2025
💡 一句话要点
LIMO:少量样本即可激发大语言模型的复杂推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 少量样本学习 数学推理 监督微调 认知模板 分布外泛化 预训练模型
📋 核心要点
- 现有方法依赖大量数据训练LLM,成本高昂且效率低下,难以适应资源受限场景。
- LIMO模型通过少量精心设计的示例,激发预训练LLM中已有的知识,实现高效推理。
- 实验表明,LIMO在数学推理任务上超越了使用更多数据训练的模型,并展现出强大的泛化能力。
📝 摘要(中文)
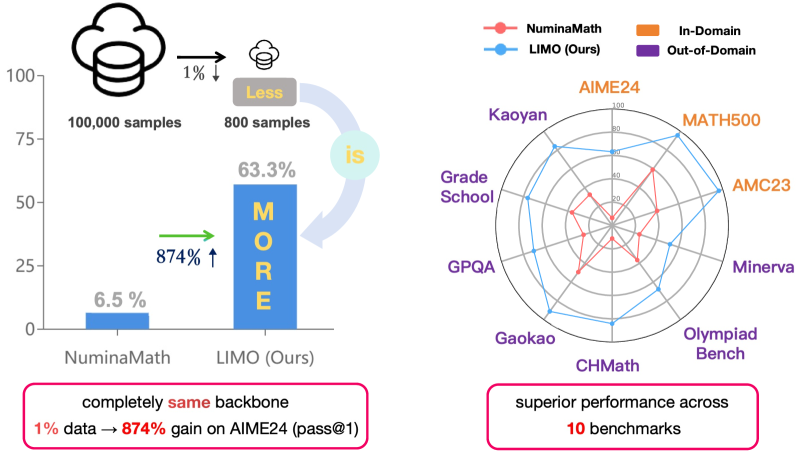
本文挑战了大型语言模型(LLM)中复杂推理需要海量训练数据的普遍假设。研究表明,仅通过少量示例即可激发复杂的数学推理能力。具体而言,通过简单的监督微调,LIMO模型在AIME24上实现了63.3%的准确率,在MATH500上实现了95.6%的准确率,超过了之前的微调模型(AIME24上为6.5%,MATH500上为59.2%),同时仅使用了先前方法所需训练数据的1%。此外,LIMO表现出强大的分布外泛化能力,在不同的基准测试中实现了45.8%的绝对改进,优于在多100倍数据上训练的模型。基于这些发现,我们提出了“少即是多推理假设”(LIMO假设):在预训练期间已全面编码领域知识的基础模型中,可以通过最少但经过策略性设计的认知过程演示来激发复杂的推理能力。该假设表明,激发复杂推理的阈值不是由任务复杂性决定的,而是由两个关键因素决定的:(1)模型预训练知识库的完整性;(2)后训练示例作为指导推理的“认知模板”的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂推理任务中对海量训练数据的依赖问题。现有方法通常需要大量的标注数据进行微调,这不仅耗费资源,而且可能导致模型过拟合,泛化能力下降。特别是在数学推理等需要特定领域知识的任务中,获取高质量的训练数据更加困难。因此,如何利用少量数据激发LLM的推理能力是一个重要的研究问题。
核心思路:论文的核心思路是“少即是多推理假设”(Less-Is-More Reasoning Hypothesis)。该假设认为,如果LLM在预训练阶段已经学习了足够的领域知识,那么只需要少量精心设计的示例,就可以引导模型进行复杂的推理。这些示例可以被视为“认知模板”,帮助模型理解任务要求,并利用已有的知识进行推理。关键在于示例的设计要能够有效地激活模型内部的知识,并引导模型按照正确的推理路径进行。
技术框架:LIMO模型的整体框架是基于预训练的LLM进行监督微调。具体流程如下:1) 选择一个合适的预训练LLM作为基础模型。2) 收集少量高质量的训练数据,这些数据包含输入问题和对应的推理过程。3) 使用这些数据对LLM进行微调,目标是让模型学习如何根据输入问题生成正确的推理过程。4) 在测试集上评估模型的性能,并与其他模型进行比较。
关键创新:论文最重要的技术创新点在于提出了“少即是多推理假设”,并验证了该假设的有效性。与以往依赖大量数据进行微调的方法不同,LIMO模型只需要少量示例就可以实现优秀的推理性能。这表明,LLM的推理能力很大程度上取决于其预训练阶段所学习的知识,而微调的作用是激活这些知识,并引导模型进行正确的推理。
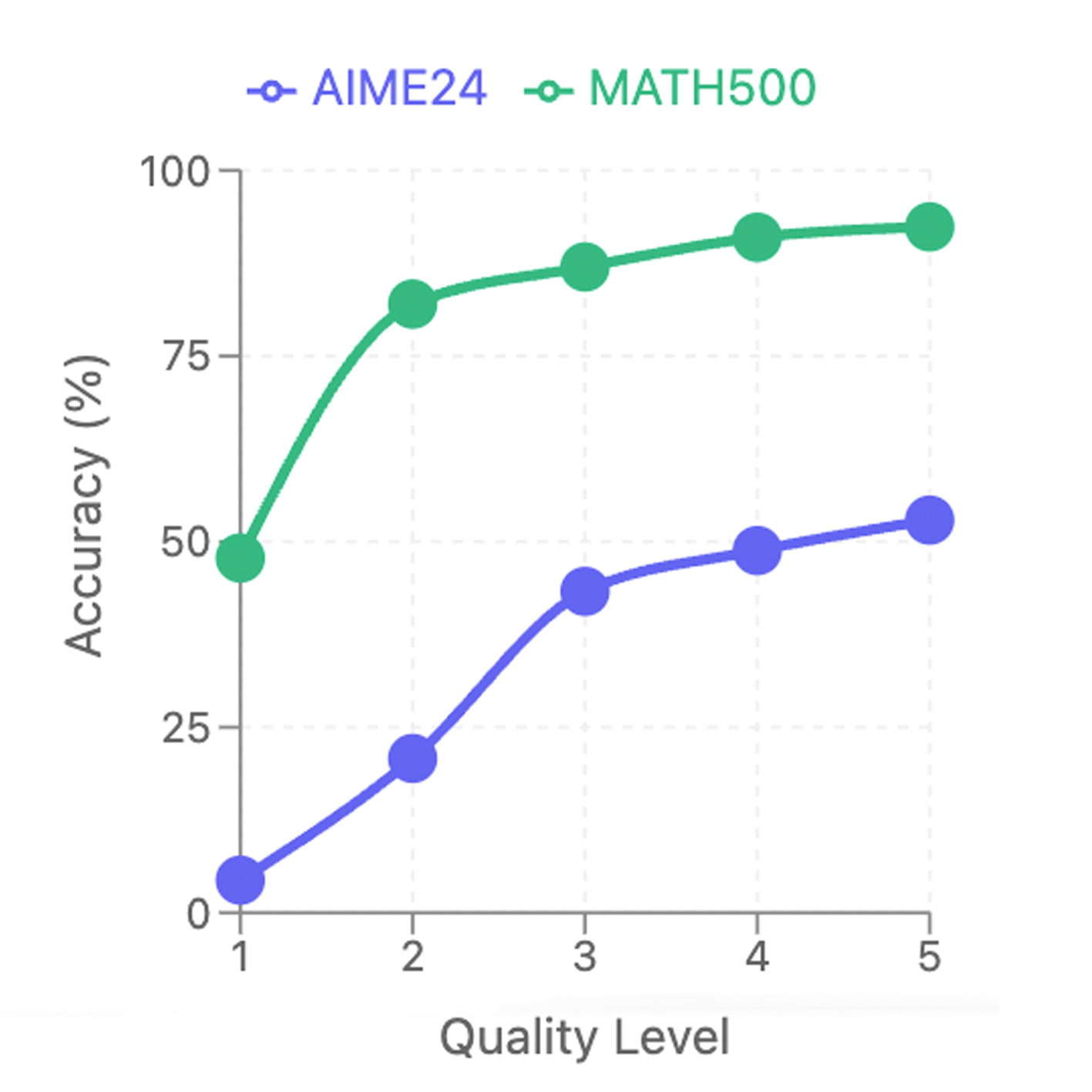
关键设计:LIMO的关键设计在于训练数据的选择和模型的微调策略。训练数据需要包含清晰的推理过程,以便模型学习如何进行推理。微调策略需要能够有效地激活模型内部的知识,并避免模型过拟合。论文中可能使用了特定的数据增强方法或者正则化技术来提高模型的泛化能力。具体的参数设置和网络结构细节需要在论文中查找。
🖼️ 关键图片

📊 实验亮点
LIMO模型在AIME24上实现了63.3%的准确率,在MATH500上实现了95.6%的准确率,显著超越了之前的微调模型(AIME24上为6.5%,MATH500上为59.2%)。同时,LIMO仅使用了先前方法所需训练数据的1%。此外,LIMO在分布外泛化能力方面表现出色,在不同的基准测试中实现了45.8%的绝对改进,优于在多100倍数据上训练的模型。
🎯 应用场景
LIMO的研究成果可应用于资源受限场景下的智能问答、数学解题、代码生成等领域。通过少量样本即可快速定制特定领域的推理模型,降低开发成本,加速AI应用落地。未来可探索将LIMO应用于更广泛的认知任务,例如常识推理、逻辑推理等,提升AI系统的智能化水平。
📄 摘要(原文)
We challenge the prevailing assumption that complex reasoning in large language models (LLMs) necessitates massive training data. We demonstrate that sophisticated mathematical reasoning can emerge with only a few examples. Specifically, through simple supervised fine-tuning, our model, LIMO, achieves 63.3\% accuracy on AIME24 and 95.6\% on MATH500, surpassing previous fine-tuned models (6.5\% on AIME24, 59.2\% on MATH500) while using only 1\% of the training data required by prior approaches. Furthermore, LIMO exhibits strong out-of-distribution generalization, achieving a 45.8\% absolute improvement across diverse benchmarks, outperforming models trained on 100x more data. Synthesizing these findings, we propose the Less-Is-More Reasoning Hypothesis (LIMO Hypothesis): In foundation models where domain knowledge has been comprehensively encoded during pre-training, sophisticated reasoning can emerge through minimal but strategically designed demonstrations of cognitive processes. This hypothesis suggests that the threshold for eliciting complex reasoning is not dictated by task complexity but rather by two key factors: (1) the completeness of the model's pre-trained knowledge base and (2) the effectiveness of post-training examples in serving as "cognitive templates" that guide reasoning.