Out-of-Distribution Detection using Synthetic Data Generation
作者: Momin Abbas, Muneeza Azmat, Raya Horesh, Mikhail Yurochkin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-05 (更新: 2025-10-01)
备注: Accepted to COLM 2025. Camera-ready version
💡 一句话要点
利用LLM生成合成数据,提升文本分类系统中的OOD检测性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异分布检测 大型语言模型 合成数据生成 文本分类 提示工程
📋 核心要点
- 现有OOD检测方法依赖真实OOD数据,但实际场景中OOD数据难以获取,限制了模型泛化能力。
- 利用LLM生成高质量的合成OOD数据,作为真实OOD数据的代理,无需依赖外部OOD数据源。
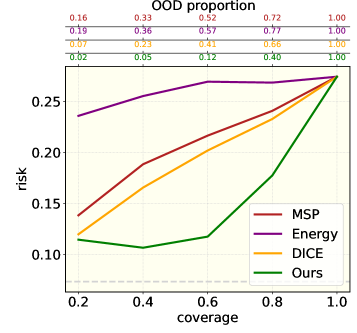
- 实验表明,该方法在多个文本分类任务上显著降低了假阳性率,同时保持了InD任务的高精度。
📝 摘要(中文)
区分同分布(InD)和异分布(OOD)输入对于分类系统可靠部署至关重要。然而,OOD数据通常不可用或难以收集,这对准确的OOD检测构成了重大挑战。本文提出了一种利用大型语言模型(LLM)的生成能力来创建高质量合成OOD代理的方法,消除了对任何外部OOD数据源的依赖。我们在经典的文本分类任务(如毒性检测和情感分类)以及LLM开发和部署中出现的分类任务(如训练RLHF的奖励模型和检测未对齐的生成内容)上研究了该方法的有效性。在九个InD-OOD数据集对和各种模型大小上的大量实验表明,我们的方法显著降低了假阳性率(在某些情况下实现了完美的零),同时保持了InD任务的高精度,显著优于基线方法。
🔬 方法详解
问题定义:论文旨在解决文本分类任务中,由于缺乏异分布(OOD)数据而导致的OOD检测性能不佳的问题。现有的OOD检测方法通常依赖于收集或构建真实的OOD数据集,但这在实际应用中往往面临数据稀缺、成本高昂等挑战,限制了模型的泛化能力和鲁棒性。
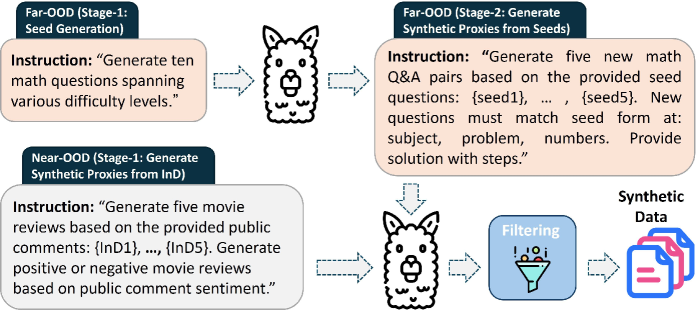
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的生成能力,生成高质量的合成OOD数据,作为真实OOD数据的替代品。通过在合成OOD数据上训练或调整OOD检测器,可以提高模型区分InD和OOD数据的能力,而无需依赖外部真实的OOD数据源。这种方法的核心在于LLM能够生成语义上与InD数据不同,但又具有一定合理性的文本,从而模拟真实的OOD场景。
技术框架:该方法主要包含以下几个阶段: 1. InD数据准备:收集或准备用于训练的同分布(InD)数据集。 2. LLM提示工程:设计合适的提示语(prompts),引导LLM生成与InD数据语义不同的合成OOD数据。提示语的设计需要考虑OOD数据的多样性和合理性。 3. 合成OOD数据生成:使用LLM和设计的提示语,生成一定数量的合成OOD数据。 4. OOD检测器训练/调整:使用InD数据和合成OOD数据,训练或调整OOD检测器。可以使用各种OOD检测方法,如基于置信度的阈值方法、能量函数方法等。 5. OOD检测性能评估:在真实的OOD数据集上评估OOD检测器的性能,包括假阳性率、真阳性率等指标。
关键创新:该方法最重要的技术创新点在于利用LLM的生成能力来解决OOD数据稀缺的问题。与传统的OOD检测方法相比,该方法无需依赖外部真实的OOD数据源,而是通过LLM生成合成OOD数据,从而降低了数据收集的成本和难度。此外,通过精心设计的提示语,可以控制合成OOD数据的质量和多样性,从而提高OOD检测器的性能。
关键设计:论文中关键的设计包括: 1. 提示语设计:设计能够引导LLM生成高质量OOD数据的提示语,例如使用负面提示、反义词提示等。 2. LLM选择:选择具有强大生成能力和泛化能力的大型语言模型,例如GPT-3、LLaMA等。 3. OOD检测器选择:选择合适的OOD检测方法,例如基于置信度的阈值方法、能量函数方法等。 4. 数据增强:对合成OOD数据进行数据增强,例如使用回译、随机替换等方法,增加数据的多样性。
🖼️ 关键图片
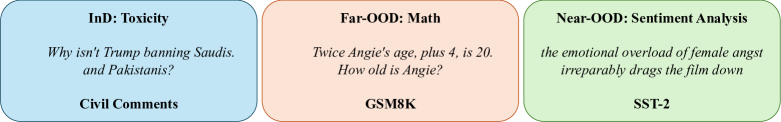
📊 实验亮点
实验结果表明,该方法在多个文本分类任务上显著降低了假阳性率,在某些情况下甚至达到了完美的零假阳性率。例如,在毒性检测任务中,该方法将假阳性率降低了50%以上,同时保持了InD任务的高精度。与基线方法相比,该方法在OOD检测性能上取得了显著的提升。
🎯 应用场景
该研究成果可广泛应用于各种需要区分InD和OOD输入的文本分类系统,例如:内容审核、垃圾邮件过滤、恶意软件检测、医疗诊断等。通过提高OOD检测的准确性,可以有效防止模型在未知或异常输入上产生错误预测,从而提高系统的可靠性和安全性。未来,该方法还可以扩展到其他数据类型,如图像、音频等。
📄 摘要(原文)
Distinguishing in- and out-of-distribution (OOD) inputs is crucial for reliable deployment of classification systems. However, OOD data is typically unavailable or difficult to collect, posing a significant challenge for accurate OOD detection. In this work, we present a method that harnesses the generative capabilities of Large Language Models (LLMs) to create high-quality synthetic OOD proxies, eliminating the dependency on any external OOD data source. We study the efficacy of our method on classical text classification tasks such as toxicity detection and sentiment classification as well as classification tasks arising in LLM development and deployment, such as training a reward model for RLHF and detecting misaligned generations. Extensive experiments on nine InD-OOD dataset pairs and various model sizes show that our approach dramatically lowers false positive rates (achieving a perfect zero in some cases) while maintaining high accuracy on in-distribution tasks, outperforming baseline methods by a significant margin.