Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning
作者: DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, Qinqing Zheng
分类: cs.CL, cs.AI, cs.LG, cs.LO
发布日期: 2025-02-05 (更新: 2025-09-01)
💡 一句话要点
提出Token Assorted方法,通过混合隐变量和文本token提升语言模型推理能力。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 推理 VQ-VAE 潜在变量 混合表示
📋 核心要点
- 现有LLM推理依赖冗长的文本token,计算成本高昂,且大量token仅用于保证文本连贯性,而非核心推理。
- 提出混合表示方法,利用VQ-VAE生成潜在离散token抽象推理步骤,缩短推理轨迹,降低计算成本。
- 通过混合潜在和文本token的训练策略,模型能快速适应新token,并在逻辑、数学推理等任务上超越基线。
📝 摘要(中文)
大型语言模型(LLMs)在经过思维链(CoT)数据训练后,在推理和规划方面表现出色,CoT数据通过文本token显式地概述了逐步的思考过程。然而,这导致了冗长的输入,其中许多词支持文本连贯性而非核心推理信息,并且处理这些输入消耗了大量的计算资源。本文提出了一种推理过程的混合表示,其中我们使用VQ-VAE生成的潜在离散token部分地抽象掉初始推理步骤,从而显著减少推理轨迹的长度。我们探索了在两种场景中使用潜在轨迹抽象:1)从头开始训练模型解决寻钥匙迷宫问题,2)在包含未见过的潜在token的扩展词汇表的混合数据上微调LLM,用于逻辑和数学推理问题。为了促进有效的学习,我们引入了一个简单的训练过程,随机混合潜在和文本token,从而能够快速适应新的潜在token。我们的方法在各种基准测试中始终优于基线方法。
🔬 方法详解
问题定义:现有的大型语言模型在进行复杂推理时,依赖于Chain-of-Thought (CoT) 数据,即逐步的思考过程以文本token的形式显式地呈现。这种方法虽然有效,但导致输入序列过长,其中许多token仅仅是为了保证文本的连贯性,而非携带核心的推理信息。这不仅增加了计算负担,也降低了推理效率。因此,需要一种更紧凑、更高效的推理表示方法。
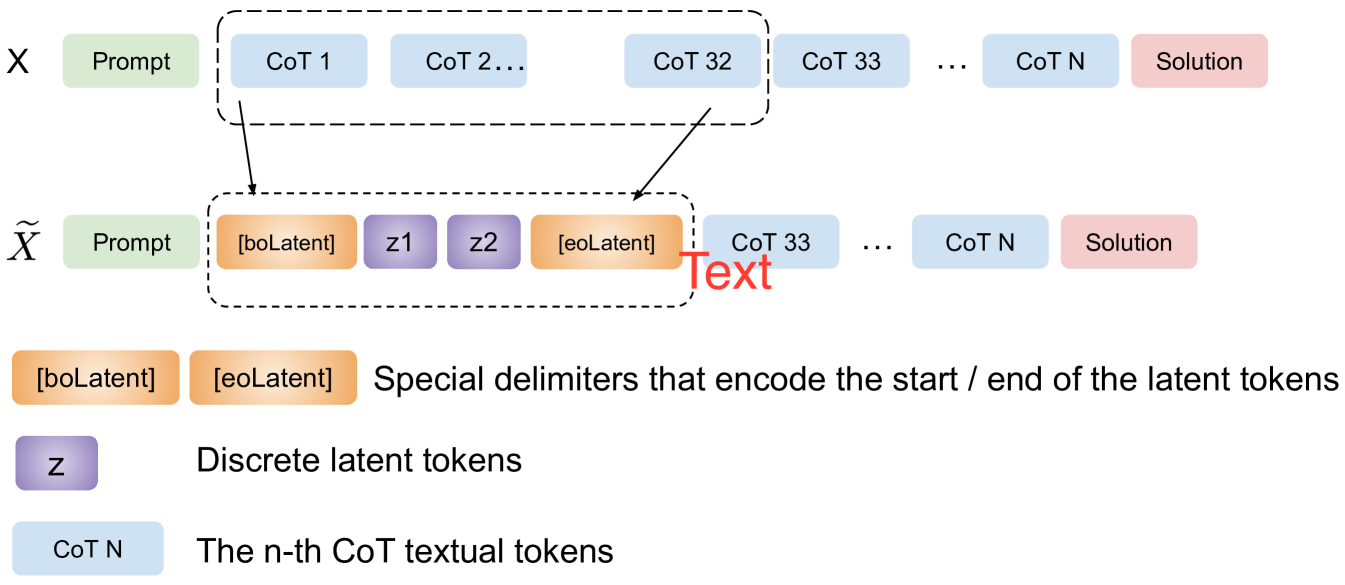
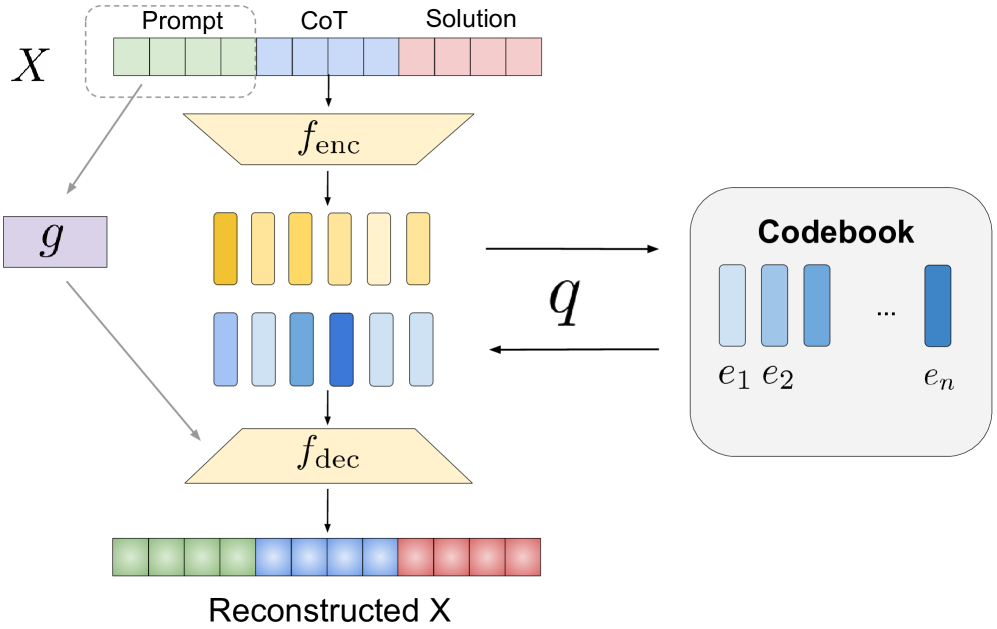
核心思路:本文的核心思路是将推理过程中的一部分步骤用潜在离散token来表示,从而减少输入序列的长度。具体来说,利用VQ-VAE(Vector Quantized Variational Autoencoder)将初始的推理步骤抽象成离散的隐变量表示。这样,模型只需要处理更短的序列,从而降低计算成本,并可能提高推理效率。这种混合表示方法旨在保留关键的推理信息,同时减少冗余的文本信息。
技术框架:整体框架包含以下几个主要模块:1) VQ-VAE:用于将文本推理步骤编码为离散的潜在token。2) 扩展词汇表的LLM:LLM的词汇表被扩展以包含VQ-VAE生成的潜在token。3) 混合训练策略:在训练过程中,随机混合文本token和潜在token,使模型能够同时理解和处理这两种类型的token。训练过程包括从头训练和微调两种方式。从头训练用于简单的迷宫问题,而微调则用于更复杂的逻辑和数学推理问题。
关键创新:该方法最重要的创新点在于提出了推理过程的混合表示,即同时使用文本token和潜在token。与完全依赖文本token的CoT方法相比,该方法能够显著减少输入序列的长度,从而降低计算成本。此外,通过随机混合文本和潜在token的训练策略,模型能够快速适应新的潜在token,提高了模型的泛化能力。
关键设计:在VQ-VAE的设计上,需要选择合适的码本大小,以平衡表示能力和离散性。在训练过程中,需要调整文本token和潜在token的混合比例,以获得最佳的性能。损失函数包括VQ-VAE的重构损失和LLM的语言模型损失。对于微调任务,需要选择合适的学习率和微调轮数,以避免过拟合。
🖼️ 关键图片
📊 实验亮点
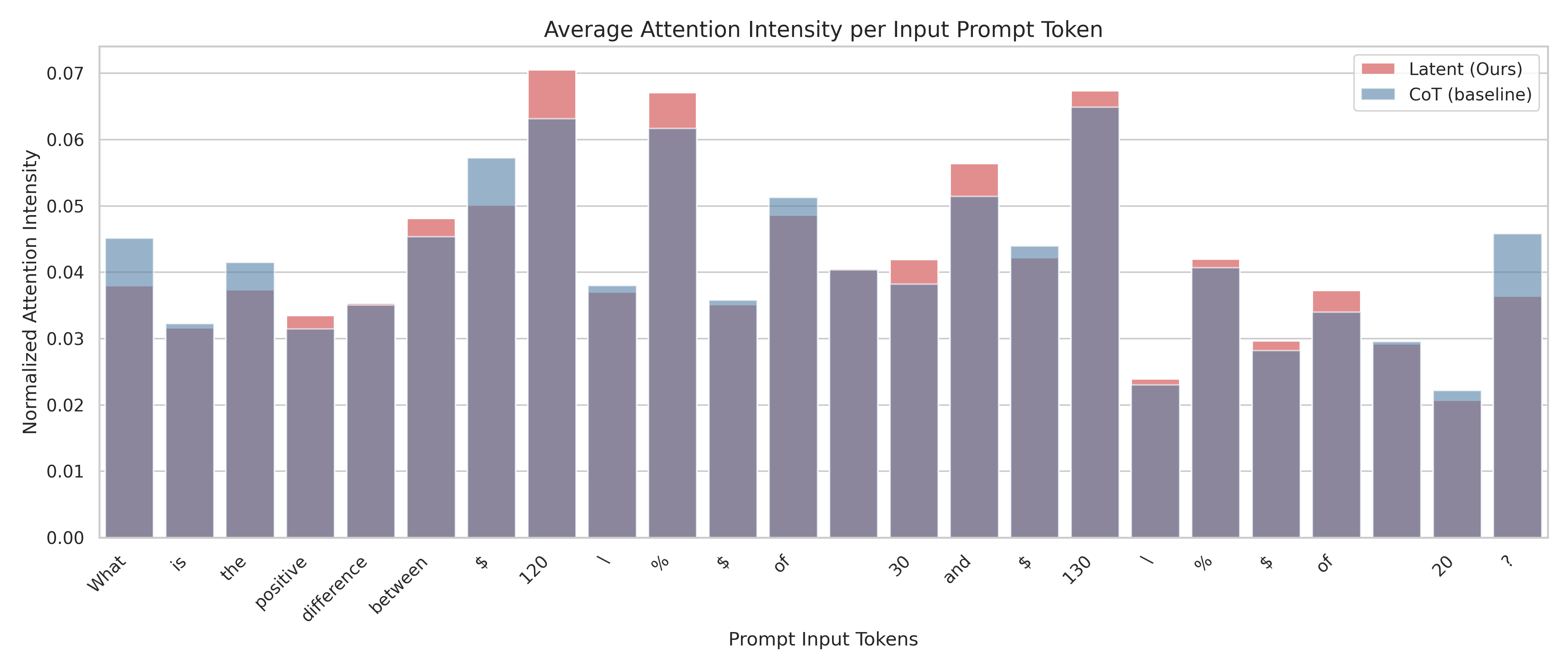
实验结果表明,Token Assorted方法在寻钥匙迷宫问题上能够从头训练模型并取得良好效果。在逻辑和数学推理问题上,通过微调LLM,该方法在各种基准测试中始终优于基线方法,证明了混合表示和混合训练策略的有效性。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如智能客服、自动编程、科学发现等。通过减少推理过程中的计算量,可以提高系统的响应速度和效率,降低部署成本。未来,该方法可以进一步扩展到其他模态的数据,例如图像和语音,从而实现更通用的推理能力。
📄 摘要(原文)
Large Language Models (LLMs) excel at reasoning and planning when trained on chainof-thought (CoT) data, where the step-by-step thought process is explicitly outlined by text tokens. However, this results in lengthy inputs where many words support textual coherence rather than core reasoning information, and processing these inputs consumes substantial computation resources. In this work, we propose a hybrid representation of the reasoning process, where we partially abstract away the initial reasoning steps using latent discrete tokens generated by VQ-VAE, significantly reducing the length of reasoning traces. We explore the use of latent trace abstractions in two scenarios: 1) training the model from scratch for the Keys-Finding Maze problem, 2) fine-tuning LLMs on this hybrid data with an extended vocabulary including unseen latent tokens, for both logical and mathematical reasoning problems. To facilitate effective learning, we introduce a simple training procedure that randomly mixes latent and text tokens, which enables fast adaptation to new latent tokens. Our approach consistently outperforms the baselines methods in various benchmarks.