iVISPAR -- An Interactive Visual-Spatial Reasoning Benchmark for VLMs
作者: Julius Mayer, Mohamad Ballout, Serwan Jassim, Farbod Nosrat Nezami, Elia Bruni
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-02-05 (更新: 2025-09-30)
💡 一句话要点
iVISPAR:一个用于评估视觉语言模型交互式视觉空间推理能力的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 空间推理 交互式基准 滑块拼图 多模态学习
📋 核心要点
- 现有视觉语言模型在空间推理和视觉对齐方面存在不足,难以处理复杂场景。
- iVISPAR基准通过滑块拼图游戏,评估VLMs在不同模态下的空间推理和规划能力。
- 实验结果表明,VLMs在2D任务上表现较好,但在复杂空间配置中远低于人类水平。
📝 摘要(中文)
视觉语言模型(VLMs)在空间推理和视觉对齐方面存在困难。为了克服这些局限性,我们提出了iVISPAR,这是一个交互式多模态基准,旨在评估作为智能体的VLMs的空间推理能力。iVISPAR基于滑块拼图的变体,这是一个需要逻辑规划、空间意识和多步推理的经典问题。该基准支持视觉3D、2D和基于文本的输入模态,从而能够全面评估VLMs的规划和推理技能。我们评估了一系列最先进的开源和闭源VLMs,比较它们的性能,同时提供最佳路径解决方案和人类基线,以评估任务对人类的复杂性和可行性。结果表明,虽然VLMs在2D任务上的表现优于3D或基于文本的设置,但它们在复杂的空间配置中表现不佳,并且始终低于人类的表现,这说明了视觉对齐方面持续存在的挑战。这突出了当前VLM能力的关键差距,强调了它们在实现人类水平认知方面的局限性。
🔬 方法详解
问题定义:现有视觉语言模型在理解和推理空间关系方面存在困难,尤其是在需要多步推理和规划的复杂任务中。现有的评估方法往往缺乏交互性,难以全面评估模型在真实场景中的应用能力。滑块拼图游戏是一个经典的需要逻辑规划、空间意识和多步推理的问题,可以用来评估VLMs的空间推理能力。
核心思路:论文的核心思路是构建一个交互式的多模态基准测试环境,通过滑块拼图游戏来评估VLMs的空间推理能力。该基准允许VLMs作为智能体与环境进行交互,并根据不同的输入模态(3D视觉、2D视觉、文本)进行推理和规划。通过比较VLMs在不同模态下的表现,可以深入了解其在空间推理方面的优势和不足。
技术框架:iVISPAR基准测试环境包含以下主要模块:1) 滑块拼图游戏环境:提供不同难度和配置的滑块拼图游戏;2) 多模态输入接口:支持3D视觉、2D视觉和文本输入;3) VLM智能体接口:允许VLMs与环境进行交互,并执行移动操作;4) 评估指标:评估VLMs完成任务的成功率、步数和时间。整体流程是,VLM接收环境输入(图像或文本),根据当前状态进行推理和规划,输出移动指令,环境执行指令并更新状态,VLM再次接收新的环境输入,重复以上过程直到完成拼图或达到最大步数。
关键创新:iVISPAR的关键创新在于其交互性和多模态性。与传统的静态图像或文本推理任务不同,iVISPAR允许VLMs与环境进行交互,并根据环境反馈进行动态调整。此外,iVISPAR支持多种输入模态,可以全面评估VLMs在不同模态下的空间推理能力。另一个创新点是提供了最优路径解决方案和人类基线,可以更客观地评估VLMs的性能。
关键设计:iVISPAR的关键设计包括:1) 滑块拼图游戏的难度设置:通过调整拼图的大小和初始状态,可以控制任务的难度;2) 多模态输入的设计:针对不同的输入模态,设计了不同的输入表示方法,例如,3D视觉输入使用点云表示,2D视觉输入使用图像表示,文本输入使用自然语言描述;3) 评估指标的设计:除了成功率之外,还考虑了步数和时间等指标,以更全面地评估VLMs的性能。
🖼️ 关键图片
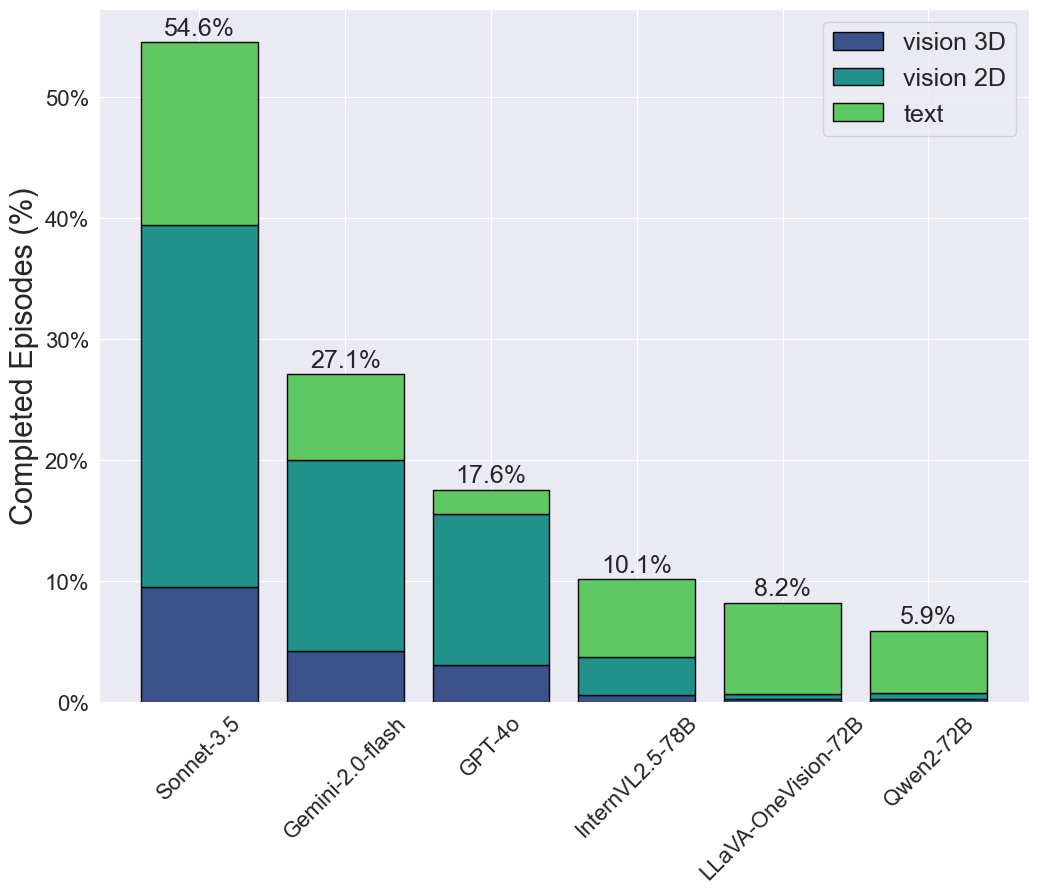

📊 实验亮点
实验结果表明,当前最先进的VLMs在iVISPAR基准上的表现远低于人类水平,尤其是在3D和文本模态下。虽然VLMs在2D任务上表现相对较好,但在复杂的空间配置中仍然存在困难。例如,在某些3D拼图任务中,VLMs的成功率仅为个位数,而人类的成功率接近100%。这表明当前VLMs在视觉空间推理方面仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、智能家居等领域。通过提高视觉语言模型在空间推理方面的能力,可以使机器人更好地理解和操作周围环境,从而实现更智能、更自主的任务执行。此外,该基准测试环境也可以用于评估和改进其他类型的智能体,例如游戏AI和虚拟助手。
📄 摘要(原文)
Vision-Language Models (VLMs) are known to struggle with spatial reasoning and visual alignment. To help overcome these limitations, we introduce iVISPAR, an interactive multimodal benchmark designed to evaluate the spatial reasoning capabilities of VLMs acting as agents. \mbox{iVISPAR} is based on a variant of the sliding tile puzzle, a classic problem that demands logical planning, spatial awareness, and multi-step reasoning. The benchmark supports visual 3D, 2D, and text-based input modalities, enabling comprehensive assessments of VLMs' planning and reasoning skills. We evaluate a broad suite of state-of-the-art open-source and closed-source VLMs, comparing their performance while also providing optimal path solutions and a human baseline to assess the task's complexity and feasibility for humans. Results indicate that while VLMs perform better on 2D tasks compared to 3D or text-based settings, they struggle with complex spatial configurations and consistently fall short of human performance, illustrating the persistent challenge of visual alignment. This underscores critical gaps in current VLM capabilities, highlighting their limitations in achieving human-level cognition. Project website: https://microcosm.ai/ivispar