Position: Editing Large Language Models Poses Serious Safety Risks
作者: Paul Youssef, Zhixue Zhao, Daniel Braun, Jörg Schlötterer, Christin Seifert
分类: cs.CL
发布日期: 2025-02-05 (更新: 2025-06-17)
备注: Accepted at ICML 2025
💡 一句话要点
知识编辑技术对大语言模型构成严重安全风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识编辑 安全风险 模型篡改 AI生态安全
📋 核心要点
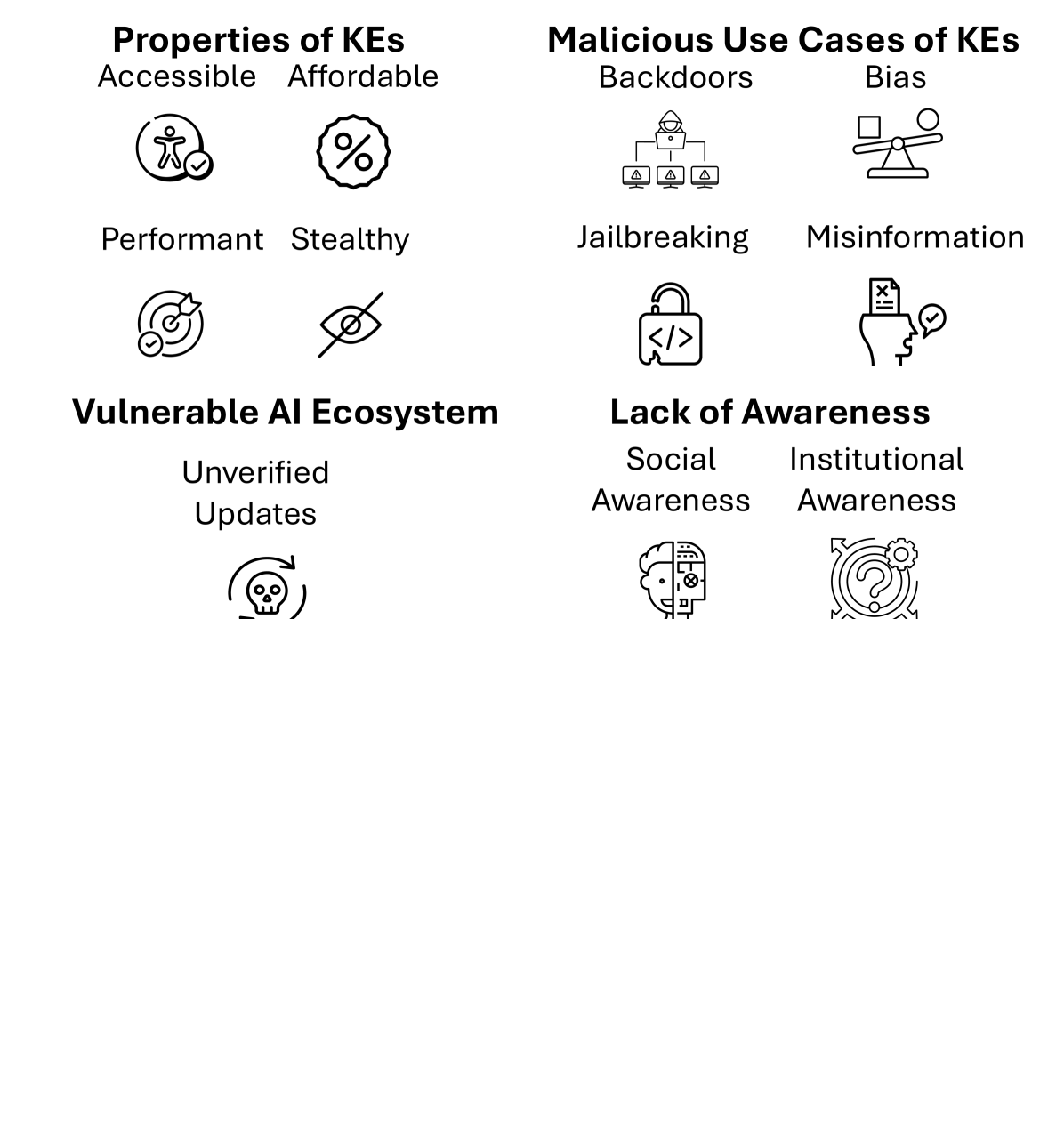
- 现有知识编辑方法缺乏对潜在安全风险的充分考虑,可能被恶意利用。
- 论文强调知识编辑技术的易用性和隐蔽性使其成为恶意攻击的理想工具。
- 论文呼吁社区关注AI生态安全,研究防篡改模型和恶意编辑的对策。
📝 摘要(中文)
大型语言模型(LLM)包含大量关于世界的知识。这些知识会随着时间推移而过时,因此出现了知识编辑(KE)方法,该方法可以在有限的副作用下更改LLM中的特定事实。本文认为,编辑LLM会带来严重的安全风险,而这些风险在很大程度上被忽视了。首先,KE的广泛可用性、低计算成本、高性能和隐蔽性使其成为恶意行为者的诱人工具。其次,我们讨论了KE的恶意用例,展示了如何轻松地将KE用于各种恶意目的。第三,我们强调了AI生态系统中的漏洞,这些漏洞允许不受限制地上传和下载更新后的模型而无需验证。第四,我们认为,社会和机构意识的缺乏加剧了这种风险,并讨论了对不同利益相关者的影响。我们呼吁社区(i)研究防篡改模型和对抗恶意模型编辑的对策,以及(ii)积极参与保护AI生态系统。
🔬 方法详解
问题定义:论文关注的是大型语言模型(LLM)的知识编辑技术可能带来的安全风险。现有的知识编辑方法主要集中在如何高效、准确地修改LLM中过时的或错误的知识,而忽略了这些技术可能被恶意利用,例如传播虚假信息、操纵舆论等。现有方法缺乏对模型篡改的防御机制,以及对上传模型的验证机制。
核心思路:论文的核心思路是强调知识编辑技术的“双刃剑”特性,即在修正模型知识的同时,也可能被恶意行为者利用来篡改模型,从而造成危害。论文通过分析知识编辑技术的特点,以及AI生态系统中的漏洞,揭示了潜在的安全风险,并呼吁社区重视并采取相应的安全措施。
技术框架:本文并非提出一种新的技术框架,而是从宏观层面分析了知识编辑技术与AI生态系统之间的交互关系,并指出了其中存在的安全漏洞。主要关注点包括:知识编辑方法的易用性、AI模型的上传/下载机制、以及社会和机构对潜在风险的认知程度。
关键创新:论文的创新之处在于其视角,即从安全角度审视知识编辑技术,并将其与AI生态系统联系起来。它没有提出新的算法或模型,而是通过分析现有技术和系统,揭示了潜在的安全风险,并提出了相应的建议。
关键设计:论文没有涉及具体的技术细节,而是从宏观层面提出了安全建议,例如:研究防篡改模型、加强模型验证机制、提高社会和机构的风险意识等。这些建议旨在提高AI生态系统的整体安全性,防止知识编辑技术被恶意利用。
🖼️ 关键图片
📊 实验亮点
本文并非实验性研究,而是立场性论文,因此没有具体的实验结果。其亮点在于对知识编辑技术潜在安全风险的深刻分析,以及对AI生态系统安全漏洞的揭示。它呼吁社区关注这些风险,并积极采取措施来保障AI系统的安全。
🎯 应用场景
该研究成果对所有涉及大型语言模型开发、部署和维护的组织和个人都具有重要意义。它提醒人们在追求模型知识更新的同时,必须高度重视潜在的安全风险,并采取相应的安全措施,以防止模型被恶意篡改和利用。这对于维护AI系统的可靠性和安全性至关重要。
📄 摘要(原文)
Large Language Models (LLMs) contain large amounts of facts about the world. These facts can become outdated over time, which has led to the development of knowledge editing methods (KEs) that can change specific facts in LLMs with limited side effects. This position paper argues that editing LLMs poses serious safety risks that have been largely overlooked. First, we note the fact that KEs are widely available, computationally inexpensive, highly performant, and stealthy makes them an attractive tool for malicious actors. Second, we discuss malicious use cases of KEs, showing how KEs can be easily adapted for a variety of malicious purposes. Third, we highlight vulnerabilities in the AI ecosystem that allow unrestricted uploading and downloading of updated models without verification. Fourth, we argue that a lack of social and institutional awareness exacerbates this risk, and discuss the implications for different stakeholders. We call on the community to (i) research tamper-resistant models and countermeasures against malicious model editing, and (ii) actively engage in securing the AI ecosystem.