LLM-KT: Aligning Large Language Models with Knowledge Tracing using a Plug-and-Play Instruction
作者: Ziwei Wang, Jie Zhou, Qin Chen, Min Zhang, Bo Jiang, Aimin Zhou, Qinchun Bai, Liang He
分类: cs.CL, cs.AI
发布日期: 2025-02-05
💡 一句话要点
LLM-KT:利用即插即用指令对齐大语言模型与知识追踪
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识追踪 大语言模型 个性化教育 序列建模 即插即用 上下文建模 模态对齐
📋 核心要点
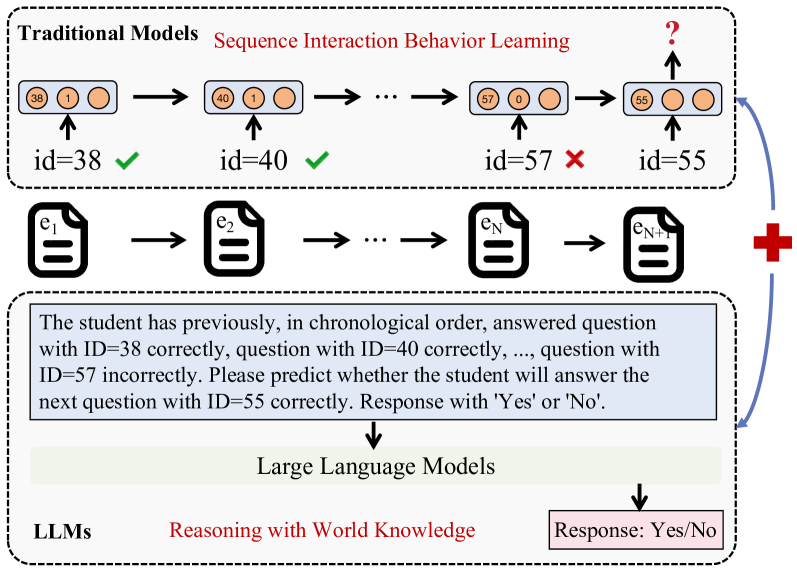
- 现有知识追踪方法难以充分捕捉学生行为模式,缺乏对问题相关世界知识的推理能力。
- LLM-KT框架通过即插即用指令对齐LLM与知识追踪任务,并整合传统序列交互模型的优势。
- 实验结果表明,LLM-KT在四个典型数据集上取得了最先进的性能,显著优于现有方法。
📝 摘要(中文)
知识追踪(KT)是个性化教育中一个极其重要的课题,旨在根据学生过去的问答记录预测他们是否能正确回答下一个问题。先前的工作主要集中于基于ID或文本信息学习行为序列。然而,这些研究通常无法在没有关于问题的丰富世界知识推理的情况下捕捉到学生充分的行为模式。在本文中,我们提出了一个基于大语言模型(LLM)的KT框架,名为 exttt{ extbf{LLM-KT}},以整合LLM和传统序列交互模型的优势。对于任务层面的对齐,我们设计了即插即用指令来将LLM与KT对齐,利用LLM丰富的知识和强大的推理能力。对于模态层面的对齐,我们设计了插件上下文和序列来整合传统方法学习到的多种模态。为了捕捉历史记录的长上下文,我们提出了一种插件上下文,使用问题特定和概念特定的token将压缩的上下文嵌入灵活地插入到LLM中。此外,我们引入了一个插件序列,通过序列适配器增强LLM,使其具有传统序列模型学习到的序列交互行为表示。大量的实验表明,通过与大约20个强大的基线进行比较, exttt{ extbf{LLM-KT}}在四个典型数据集上获得了最先进的性能。
🔬 方法详解
问题定义:知识追踪旨在根据学生的历史答题记录预测其未来答题表现。现有方法主要依赖ID或文本信息,缺乏对问题相关知识的推理,难以充分捕捉学生行为模式。这些方法无法有效利用外部知识来提升预测准确性。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大知识和推理能力来增强知识追踪模型。通过设计即插即用的指令和模态对齐机制,将LLM与传统的序列交互模型相结合,从而提升知识追踪的性能。
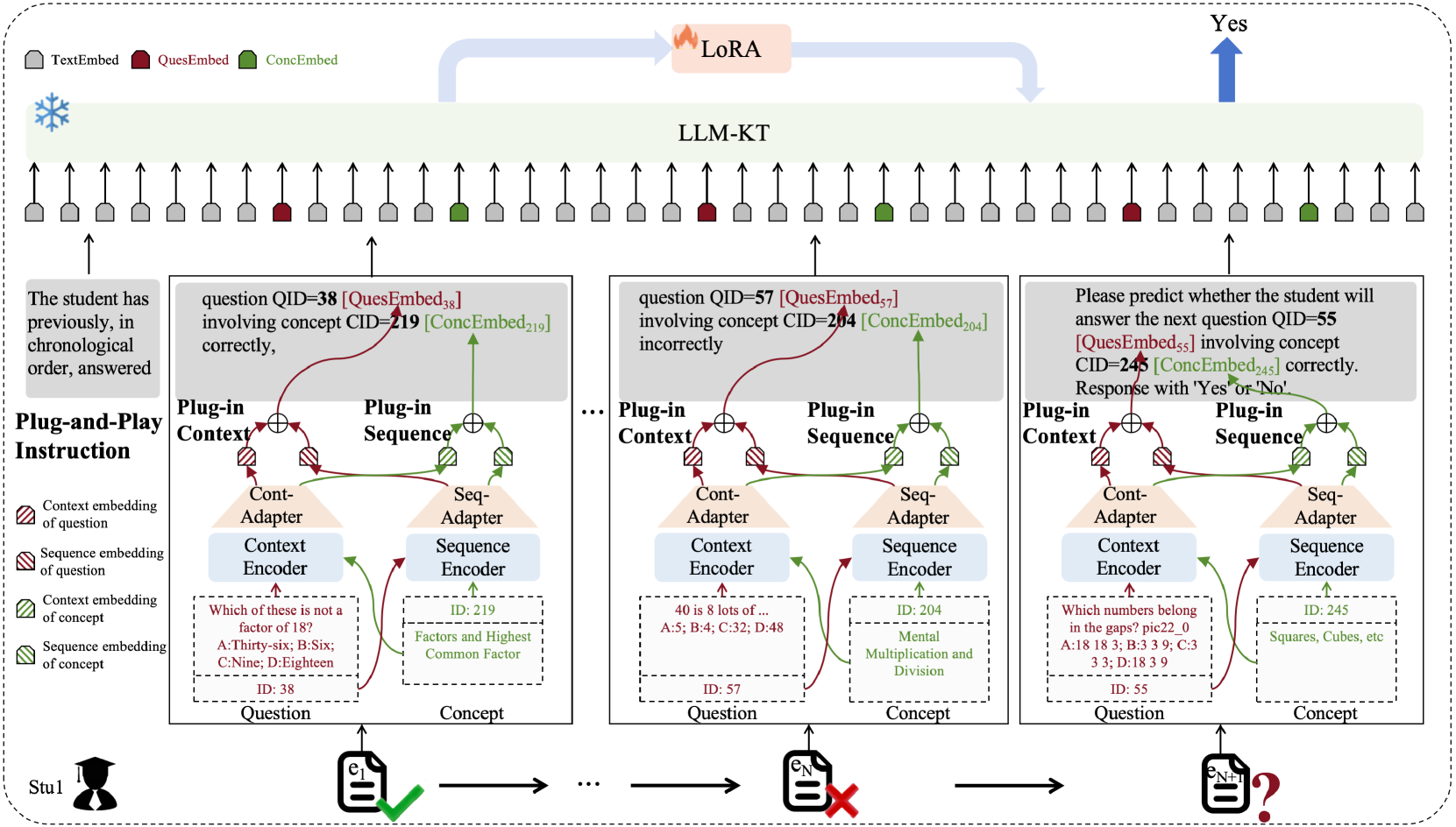
技术框架:LLM-KT框架包含以下主要模块: 1. Plug-and-Play Instruction: 用于任务层面的对齐,指导LLM执行知识追踪任务。 2. Plug-in Context: 用于整合历史答题记录的长上下文信息,通过问题和概念特定的token将压缩的上下文嵌入到LLM中。 3. Plug-in Sequence: 用于整合传统序列模型学习到的序列交互行为表示,通过序列适配器增强LLM。
关键创新:该论文的关键创新在于: 1. 任务层面的对齐:设计了即插即用指令,使得LLM能够理解并执行知识追踪任务。 2. 模态层面的对齐:通过插件上下文和序列,将LLM与传统序列模型学习到的信息进行有效整合。 3. 长上下文建模:提出了插件上下文,能够有效地利用历史答题记录的长上下文信息。
关键设计: 1. Plug-and-Play Instruction: 具体指令的设计方式未知,但其目标是引导LLM进行知识追踪推理。 2. Plug-in Context: 使用问题特定和概念特定的token来压缩和嵌入上下文信息,具体压缩算法未知。 3. Plug-in Sequence: 使用序列适配器来融合传统序列模型的输出,适配器的具体结构和参数设置未知。
🖼️ 关键图片
📊 实验亮点
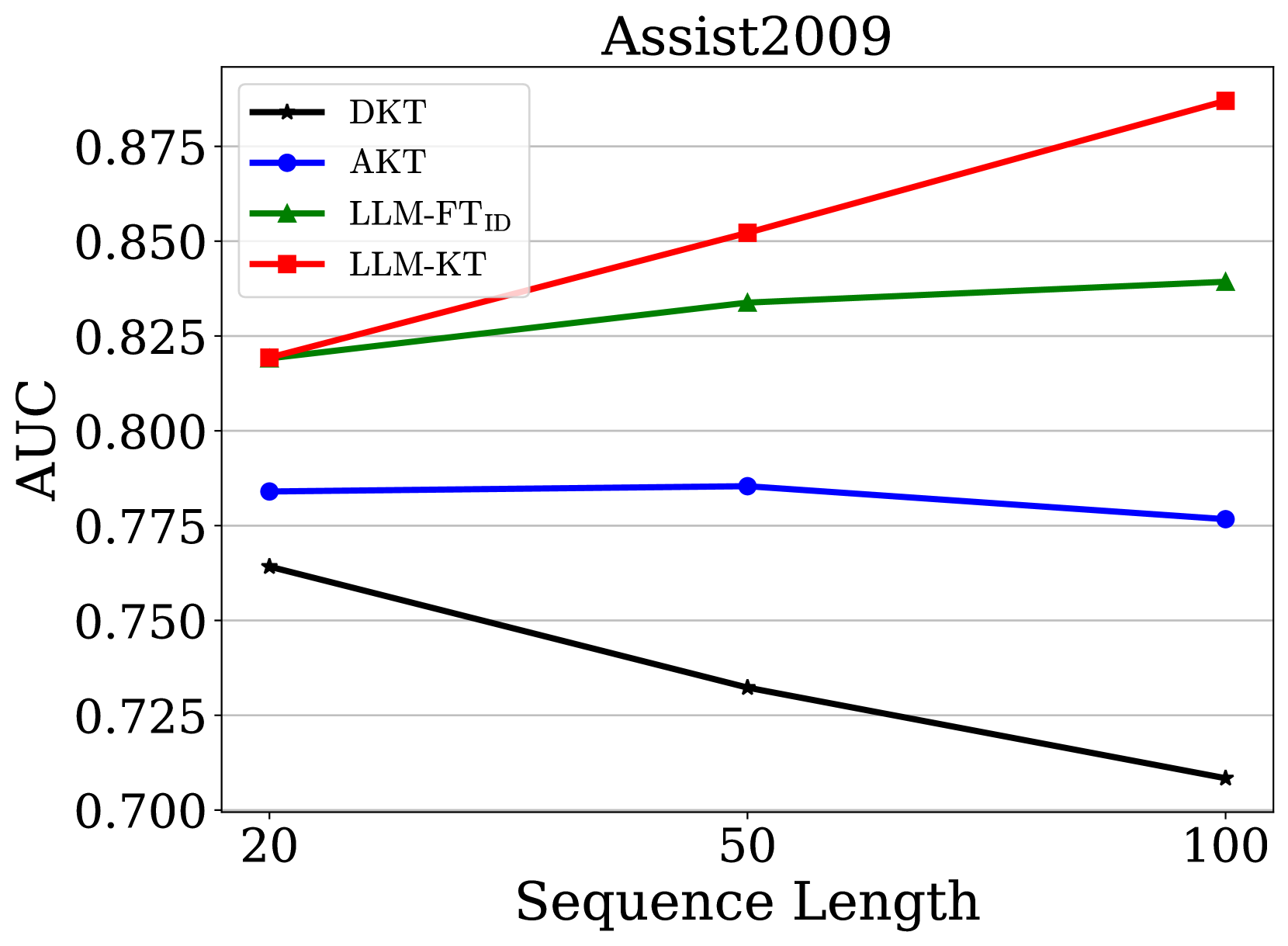
LLM-KT在四个典型数据集上取得了state-of-the-art的性能,显著优于大约20个强大的基线模型。具体的性能提升幅度未知,但摘要强调了其超越现有方法的优越性。实验结果验证了LLM与知识追踪任务结合的有效性,以及即插即用指令和模态对齐机制的优越性。
🎯 应用场景
LLM-KT具有广泛的应用前景,可用于个性化学习推荐、智能辅导系统、在线教育平台等领域。通过更准确地预测学生的知识掌握情况,可以为学生提供定制化的学习内容和学习路径,提高学习效率和学习效果。该研究有助于推动个性化教育的发展,并为构建更智能、更高效的教育系统提供技术支持。
📄 摘要(原文)
The knowledge tracing (KT) problem is an extremely important topic in personalized education, which aims to predict whether students can correctly answer the next question based on their past question-answer records. Prior work on this task mainly focused on learning the sequence of behaviors based on the IDs or textual information. However, these studies usually fail to capture students' sufficient behavioral patterns without reasoning with rich world knowledge about questions. In this paper, we propose a large language models (LLMs)-based framework for KT, named \texttt{\textbf{LLM-KT}}, to integrate the strengths of LLMs and traditional sequence interaction models. For task-level alignment, we design Plug-and-Play instruction to align LLMs with KT, leveraging LLMs' rich knowledge and powerful reasoning capacity. For modality-level alignment, we design the plug-in context and sequence to integrate multiple modalities learned by traditional methods. To capture the long context of history records, we present a plug-in context to flexibly insert the compressed context embedding into LLMs using question-specific and concept-specific tokens. Furthermore, we introduce a plug-in sequence to enhance LLMs with sequence interaction behavior representation learned by traditional sequence models using a sequence adapter. Extensive experiments show that \texttt{\textbf{LLM-KT}} obtains state-of-the-art performance on four typical datasets by comparing it with approximately 20 strong baselines.