ScholaWrite: A Dataset of End-to-End Scholarly Writing Process
作者: Khanh Chi Le, Linghe Wang, Minhwa Lee, Ross Volkov, Luan Tuyen Chau, Dongyeop Kang
分类: cs.HC, cs.CL, q-bio.NC
发布日期: 2025-02-05 (更新: 2025-10-21)
备注: Equal contribution: Khanh Chi Le, Linghe Wang, Minhwa Lee | project page: https://minnesotanlp.github.io/scholawrite/
💡 一句话要点
ScholaWrite:构建端到端学术写作过程数据集,助力写作助手开发
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 学术写作 写作过程 端到端数据集 认知意图 大型语言模型
📋 核心要点
- 现有写作助手难以捕捉作者完整的思维过程,无法真正理解写作意图并提供有效帮助。
- ScholaWrite通过Chrome插件记录Overleaf上的写作过程,构建包含细粒度认知意图标注的学术手稿语料库。
- 分析表明,当前大型语言模型在理解人类写作过程方面存在差距,端到端数据对于开发更智能的写作助手至关重要。
📝 摘要(中文)
写作是一项认知需求高的活动,需要持续决策、高度依赖工作记忆,并在不同目标的任务间频繁切换。为了构建真正符合作者认知的写作助手,我们必须捕捉并解码作者将想法转化为最终文本的完整思维过程。我们提出了ScholaWrite,这是第一个端到端学术写作数据集,追踪从初始草稿到最终稿件的多月过程。我们贡献了三个关键进展:(1)一个Chrome扩展程序,可以不引人注目地记录Overleaf上的击键,从而能够收集真实的、原位的写作数据;(2)一个新颖的完整学术手稿语料库,其中包含对认知写作意图的细粒度注释。该数据集包括来自五个计算机科学预印本的基于\LaTeX的编辑,捕获了四个月内近62K个文本更改;(3)对学术写作微观动态的分析和见解,突出了人类写作过程与大型语言模型(LLM)在提供有意义的帮助方面的当前能力之间的差距。ScholaWrite强调了捕获端到端写作数据对于开发未来写作助手的重要性,这些助手可以支持而不是取代科学家的认知工作。
🔬 方法详解
问题定义:现有写作辅助工具无法充分理解作者的写作意图和认知过程,导致提供的帮助不够有效。痛点在于缺乏能够捕捉从初始想法到最终文本的完整写作过程的数据集,使得模型难以学习人类写作的微观动态。
核心思路:通过记录作者在Overleaf上的写作过程,构建一个包含细粒度认知意图标注的端到端学术写作数据集。核心在于捕捉真实的写作过程数据,并对其进行详细的标注,从而为开发更智能的写作助手提供基础。
技术框架:ScholaWrite数据集的构建主要包含以下几个阶段:1. 开发Chrome扩展程序,用于记录Overleaf上的击键和其他写作行为。2. 收集来自计算机科学预印本的\LaTeX文本编辑数据。3. 对收集到的数据进行细粒度的认知意图标注。4. 对数据集进行分析,揭示学术写作的微观动态。
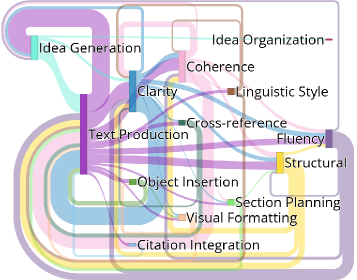
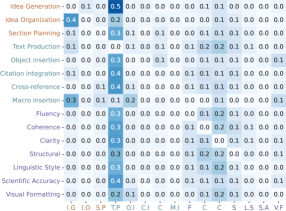
关键创新:ScholaWrite是第一个端到端学术写作数据集,它不仅记录了最终的文本,还记录了作者的写作过程,包括击键、编辑和认知意图。这种端到端的数据对于理解人类写作的微观动态至关重要。
关键设计:Chrome扩展程序的设计需要保证不干扰作者的写作过程,同时能够准确地记录所有的写作行为。认知意图标注需要定义清晰的标注规范,并由专业的标注人员进行标注。数据集的分析需要使用合适的统计方法和机器学习模型,以揭示学术写作的微观动态。
🖼️ 关键图片
📊 实验亮点
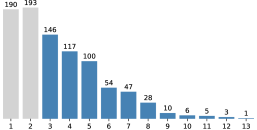
ScholaWrite数据集包含来自五个计算机科学预印本的\LaTeX文本编辑数据,捕获了四个月内近62K个文本更改。通过对数据集的分析,研究人员发现当前大型语言模型在理解人类写作过程方面存在差距,表明端到端数据对于开发更智能的写作助手至关重要。
🎯 应用场景
ScholaWrite数据集可用于开发更智能的写作助手,帮助研究人员提高写作效率和质量。例如,可以利用该数据集训练模型,预测作者的写作意图,并提供个性化的写作建议。此外,该数据集还可以用于研究人类写作的认知过程,为教育和心理学研究提供新的视角。
📄 摘要(原文)
Writing is a cognitively demanding activity that requires constant decision-making, heavy reliance on working memory, and frequent shifts between tasks of different goals. To build writing assistants that truly align with writers' cognition, we must capture and decode the complete thought process behind how writers transform ideas into final texts. We present ScholaWrite, the first dataset of end-to-end scholarly writing, tracing the multi-month journey from initial drafts to final manuscripts. We contribute three key advances: (1) a Chrome extension that unobtrusively records keystrokes on Overleaf, enabling the collection of realistic, in-situ writing data; (2) a novel corpus of full scholarly manuscripts, enriched with fine-grained annotations of cognitive writing intentions. The dataset includes \LaTeX-based edits from five computer science preprints, capturing nearly 62K text changes over four months; and (3) analyses and insights into the micro-dynamics of scholarly writing, highlighting gaps between human writing processes and the current capabilities of large language models (LLMs) in providing meaningful assistance. ScholaWrite underscores the value of capturing end-to-end writing data to develop future writing assistants that support, not replace, the cognitive work of scientists.