Lowering the Barrier of Machine Learning: Achieving Zero Manual Labeling in Review Classification Using LLMs
作者: Yejian Zhang, Shingo Takada
分类: cs.CL
发布日期: 2025-02-05
备注: Accepted to 2025 11th International Conference on Computing and Artificial Intelligence (ICCAI 2025)
💡 一句话要点
提出一种基于LLM的零标注评论分类方法,降低中小企业应用门槛。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感分类 大型语言模型 零标注学习 评论分析 GPT BERT 自然语言处理 机器学习
📋 核心要点
- 现有机器学习情感分类技术复杂,中小企业难以应用,导致与大型企业在客户满意度提升方面差距扩大。
- 利用大型语言模型(LLM),特别是GPT和BERT,无需手动标注即可实现高精度的情感分类。
- 实验表明,该方法在多个数据集上无需人工标注、专家调参和大量算力,仍能保持较高的分类准确率。
📝 摘要(中文)
随着互联网的发展,消费者越来越依赖在线评论来选择服务或产品,这使得企业需要分析大量的客户反馈以改进其产品。虽然基于机器学习的情感分类在这方面显示出潜力,但其技术复杂性常常阻碍小型企业和个人利用这些进步,这最终可能导致大小企业在提高客户满意度方面的竞争差距进一步扩大。本文介绍了一种集成大型语言模型(LLM)的方法,特别是基于生成式预训练Transformer(GPT)和基于Transformer的双向编码器表示(BERT)的模型,使其能够被更广泛的受众所使用。我们在各种数据集上的实验证实,我们的方法在不需要手动标注、调整和数据注释方面的专家知识或大量计算能力的情况下,仍保持了较高的分类准确率。通过显著降低应用情感分类技术的门槛,我们的方法提高了竞争力,并为使机器学习技术能够被更广泛的受众所使用铺平了道路。
🔬 方法详解
问题定义:论文旨在解决小型企业和个人难以应用机器学习进行情感分类的问题。现有方法需要大量手动标注数据、专家知识进行模型调优以及较高的计算资源,这使得小型企业在利用机器学习提升客户满意度方面处于劣势。
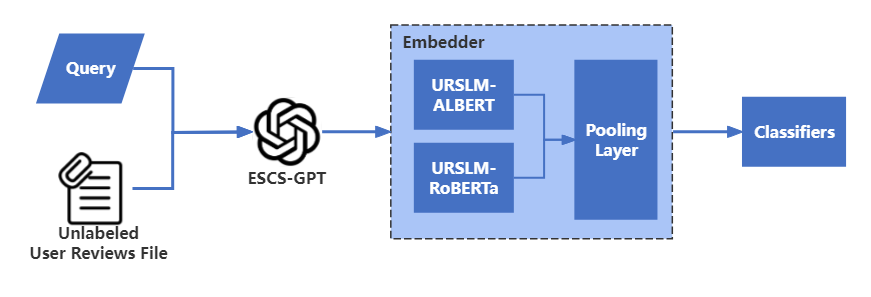
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大zero-shot或few-shot学习能力,直接对评论进行情感分类,从而避免了手动标注数据的需求。通过使用预训练的GPT和BERT模型,可以有效地捕捉评论中的语义信息,并进行准确的情感判断。
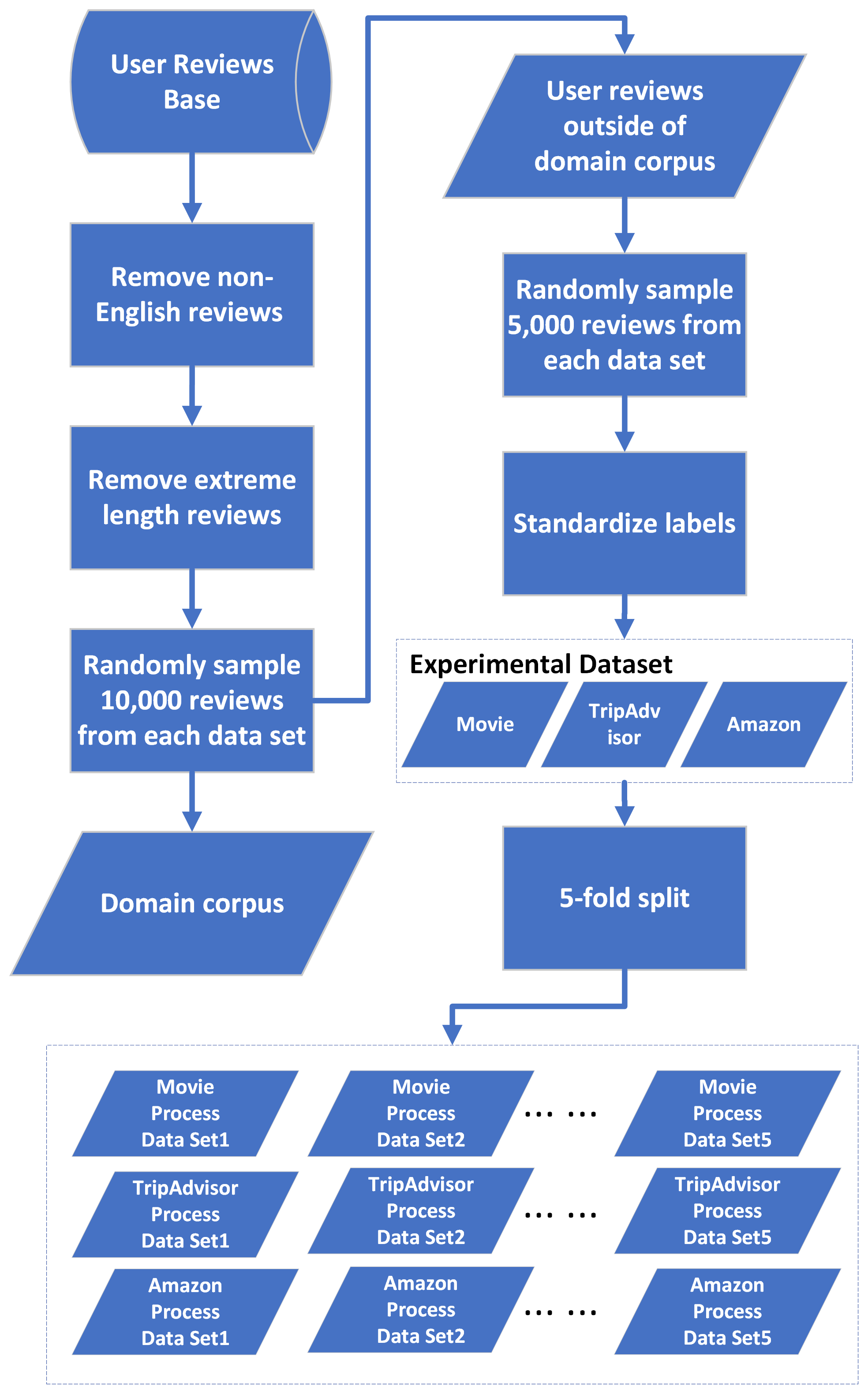
技术框架:该方法的技术框架主要包括以下几个阶段:1) 数据准备:收集需要进行情感分类的评论数据。2) 模型选择:选择合适的预训练LLM,例如GPT或BERT。3) 情感分类:使用LLM直接对评论进行情感分类,无需额外的训练或微调(zero-shot)或使用少量标注数据进行微调(few-shot)。4) 结果评估:评估LLM在情感分类任务上的准确率和性能。
关键创新:论文的关键创新在于提出了一种完全依赖预训练LLM进行情感分类的方法,无需任何手动标注数据。这极大地降低了应用机器学习进行情感分类的门槛,使得小型企业和个人也能轻松利用该技术。与传统方法相比,该方法避免了耗时耗力的数据标注过程,并且不需要专业的机器学习知识。
关键设计:论文的关键设计在于选择合适的预训练LLM,并探索不同的prompt工程方法来引导LLM进行情感分类。例如,可以使用不同的prompt来询问LLM评论的情感倾向,并根据LLM的输出来判断评论的情感极性。此外,还可以探索使用少量标注数据对LLM进行微调,以进一步提高情感分类的准确率。
🖼️ 关键图片

📊 实验亮点
该研究通过实验验证了基于LLM的零标注评论分类方法的可行性和有效性。实验结果表明,该方法在多个数据集上无需人工标注的情况下,仍能保持较高的分类准确率,与需要大量标注数据的传统方法相比,具有显著的优势。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可广泛应用于在线评论情感分析、客户反馈分析、舆情监控等领域。小型企业和个人可以利用该方法快速分析客户评论,了解客户需求,改进产品和服务,提升客户满意度。该方法还有助于降低机器学习的应用门槛,促进人工智能技术的普及。
📄 摘要(原文)
With the internet's evolution, consumers increasingly rely on online reviews for service or product choices, necessitating that businesses analyze extensive customer feedback to enhance their offerings. While machine learning-based sentiment classification shows promise in this realm, its technical complexity often bars small businesses and individuals from leveraging such advancements, which may end up making the competitive gap between small and large businesses even bigger in terms of improving customer satisfaction. This paper introduces an approach that integrates large language models (LLMs), specifically Generative Pre-trained Transformer (GPT) and Bidirectional Encoder Representations from Transformers (BERT)-based models, making it accessible to a wider audience. Our experiments across various datasets confirm that our approach retains high classification accuracy without the need for manual labeling, expert knowledge in tuning and data annotation, or substantial computational power. By significantly lowering the barriers to applying sentiment classification techniques, our methodology enhances competitiveness and paves the way for making machine learning technology accessible to a broader audience.