Position: Multimodal Large Language Models Can Significantly Advance Scientific Reasoning
作者: Yibo Yan, Shen Wang, Jiahao Huo, Jingheng Ye, Zhendong Chu, Xuming Hu, Philip S. Yu, Carla Gomes, Bart Selman, Qingsong Wen
分类: cs.CL, cs.AI
发布日期: 2025-02-05
💡 一句话要点
多模态大语言模型显著提升科学推理能力,助力AGI实现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 科学推理 人工智能 通用人工智能 多模态融合
📋 核心要点
- 现有科学推理模型在跨领域泛化和多模态感知方面存在不足,限制了其在复杂科学问题中的应用。
- 论文提出利用多模态大语言模型(MLLMs)整合文本、图像等多种模态信息,增强科学推理能力。
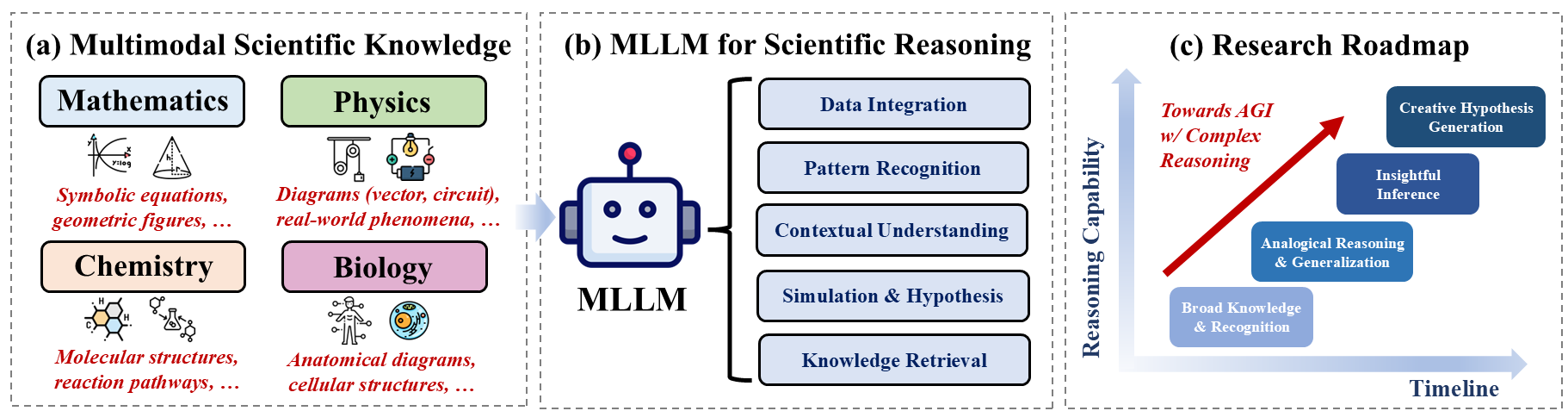
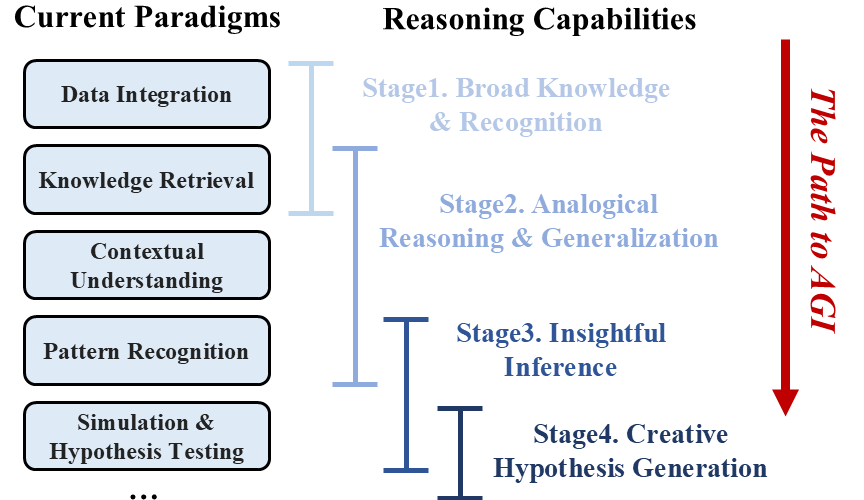
- 论文构建了科学推理能力的四阶段路线图,并分析了MLLM在科学推理中的应用现状和未来挑战。
📝 摘要(中文)
本文提出了一种观点,认为多模态大语言模型(MLLMs)能够显著提升数学、物理、化学和生物等学科的科学推理能力。科学推理是人类运用逻辑、证据和批判性思维来探索和解释科学现象的过程,对于推动各个领域的知识推理至关重要。尽管当前科学推理模型取得了显著进展,但仍然难以跨领域泛化,并且在多模态感知方面存在不足。MLLMs集成了文本、图像和其他模态,为克服这些限制和增强科学推理提供了令人兴奋的机会。本文首先提出了一个科学推理能力的四阶段研究路线图,并强调了MLLM在科学推理中的应用现状,指出了它们整合和推理不同数据类型的能力。其次,总结了阻碍MLLM充分发挥潜力的关键挑战。为了应对这些挑战,我们为未来提出了可行的见解和建议。总的来说,我们的工作为MLLM与科学推理的集成提供了一个新的视角,为LLM社区提供了一个实现通用人工智能(AGI)的宝贵愿景。
🔬 方法详解
问题定义:当前科学推理模型难以有效处理涉及多种数据类型的复杂科学问题,例如需要结合文本描述和图像信息的化学反应预测。现有方法在跨领域泛化能力和多模态信息融合方面存在瓶颈,限制了其在实际科学研究中的应用。
核心思路:论文的核心思路是利用MLLMs强大的多模态信息处理和推理能力,将文本、图像等多种模态的信息整合起来,从而提升模型在科学推理任务中的性能。通过让模型学习不同模态之间的关联,可以更好地理解科学现象,并进行更准确的预测和解释。
技术框架:论文提出了一个四阶段的科学推理能力研究路线图,但并未提供具体的模型架构或训练流程。文章主要侧重于分析MLLM在科学推理中的潜力,并探讨了未来研究方向。整体框架可以理解为:输入多模态科学数据 -> MLLM进行信息融合和推理 -> 输出科学结论或预测。
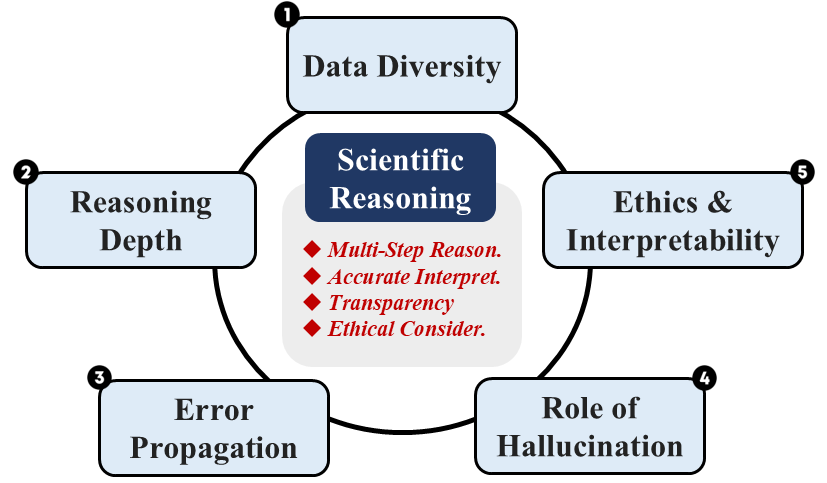
关键创新:论文的主要创新在于提出了将MLLMs应用于科学推理任务的观点,并分析了其潜在优势和挑战。虽然没有提出新的模型结构,但强调了多模态信息融合对于提升科学推理能力的重要性,为未来的研究方向提供了指导。
关键设计:论文没有涉及具体的模型设计细节,而是侧重于对现有MLLM在科学推理任务中应用的分析和展望。未来的研究可以探索如何设计更有效的多模态融合机制,以及如何利用领域知识来提升模型的推理能力。例如,可以考虑使用注意力机制来学习不同模态之间的关联,或者使用知识图谱来增强模型的推理能力。具体的参数设置、损失函数、网络结构等技术细节需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
本文是一篇立场性论文,主要贡献在于提出了利用MLLMs提升科学推理能力的观点,并分析了其潜在优势和挑战。论文没有提供具体的实验结果,而是侧重于对未来研究方向的展望。未来的研究可以基于本文提出的观点,设计更有效的多模态科学推理模型,并在实际数据集上进行验证。
🎯 应用场景
该研究具有广泛的应用前景,例如可以应用于新材料发现、药物研发、疾病诊断等领域。通过结合文本、图像等多种模态的信息,MLLMs可以帮助科学家更高效地进行科学研究,加速科学发现的进程。此外,该研究还可以促进人工智能在科学领域的应用,推动人工智能与科学研究的深度融合。
📄 摘要(原文)
Scientific reasoning, the process through which humans apply logic, evidence, and critical thinking to explore and interpret scientific phenomena, is essential in advancing knowledge reasoning across diverse fields. However, despite significant progress, current scientific reasoning models still struggle with generalization across domains and often fall short of multimodal perception. Multimodal Large Language Models (MLLMs), which integrate text, images, and other modalities, present an exciting opportunity to overcome these limitations and enhance scientific reasoning. Therefore, this position paper argues that MLLMs can significantly advance scientific reasoning across disciplines such as mathematics, physics, chemistry, and biology. First, we propose a four-stage research roadmap of scientific reasoning capabilities, and highlight the current state of MLLM applications in scientific reasoning, noting their ability to integrate and reason over diverse data types. Second, we summarize the key challenges that remain obstacles to achieving MLLM's full potential. To address these challenges, we propose actionable insights and suggestions for the future. Overall, our work offers a novel perspective on MLLM integration with scientific reasoning, providing the LLM community with a valuable vision for achieving Artificial General Intelligence (AGI).