SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
作者: Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Gabriel Martín Blázquez, Guilherme Penedo, Lewis Tunstall, Andrés Marafioti, Hynek Kydlíček, Agustín Piqueres Lajarín, Vaibhav Srivastav, Joshua Lochner, Caleb Fahlgren, Xuan-Son Nguyen, Clémentine Fourrier, Ben Burtenshaw, Hugo Larcher, Haojun Zhao, Cyril Zakka, Mathieu Morlon, Colin Raffel, Leandro von Werra, Thomas Wolf
分类: cs.CL
发布日期: 2025-02-04
💡 一句话要点
SmolLM2:通过数据为中心训练,打造高性能小规模语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 数据为中心训练 多阶段训练 知识蒸馏 模型优化 数学数据集 代码数据集
📋 核心要点
- 大型语言模型计算成本高,部署困难,限制了其在资源受限环境中的应用。
- SmolLM2通过多阶段训练,混合网络文本与专业数据,并引入新数据集,提升小模型的性能。
- 实验表明,SmolLM2在多个基准测试中优于Qwen2.5-1.5B和Llama3.2-1B等同规模模型。
📝 摘要(中文)
大型语言模型在人工智能的许多应用中取得了突破,但其固有的规模使其计算成本高昂,难以在资源受限的环境中部署。本文记录了SmolLM2的开发过程,这是一个最先进的“小型”(17亿参数)语言模型(LM)。为了获得强大的性能,我们使用多阶段训练过程,在约11万亿个token的数据上过度训练SmolLM2,该过程混合了网络文本与专门的数学、代码和指令遵循数据。此外,我们还在现有数据集规模过小或质量较低的阶段引入了新的专门数据集(FineMath、Stack-Edu和SmolTalk)。为了指导我们的设计决策,我们进行了小规模消融实验以及手动优化过程,该过程基于前一阶段的性能更新每个阶段的数据集混合比例。最终,我们证明SmolLM2优于其他最近的小型LM,包括Qwen2.5-1.5B和Llama3.2-1B。为了促进未来对LM开发以及小型LM应用的研究,我们发布了SmolLM2以及我们在本项目过程中准备的所有数据集。
🔬 方法详解
问题定义:论文旨在解决在资源受限环境下部署高性能语言模型的问题。现有的大型语言模型参数量巨大,计算成本高昂,难以在边缘设备或低算力环境中应用。因此,需要开发一种参数量小、性能优异的小型语言模型。
核心思路:论文的核心思路是通过数据为中心的方法,即通过精心设计和优化训练数据,以及采用多阶段训练策略,来提升小型语言模型的性能。通过高质量、多样化的数据训练,使模型在有限的参数量下也能学习到丰富的知识和能力。
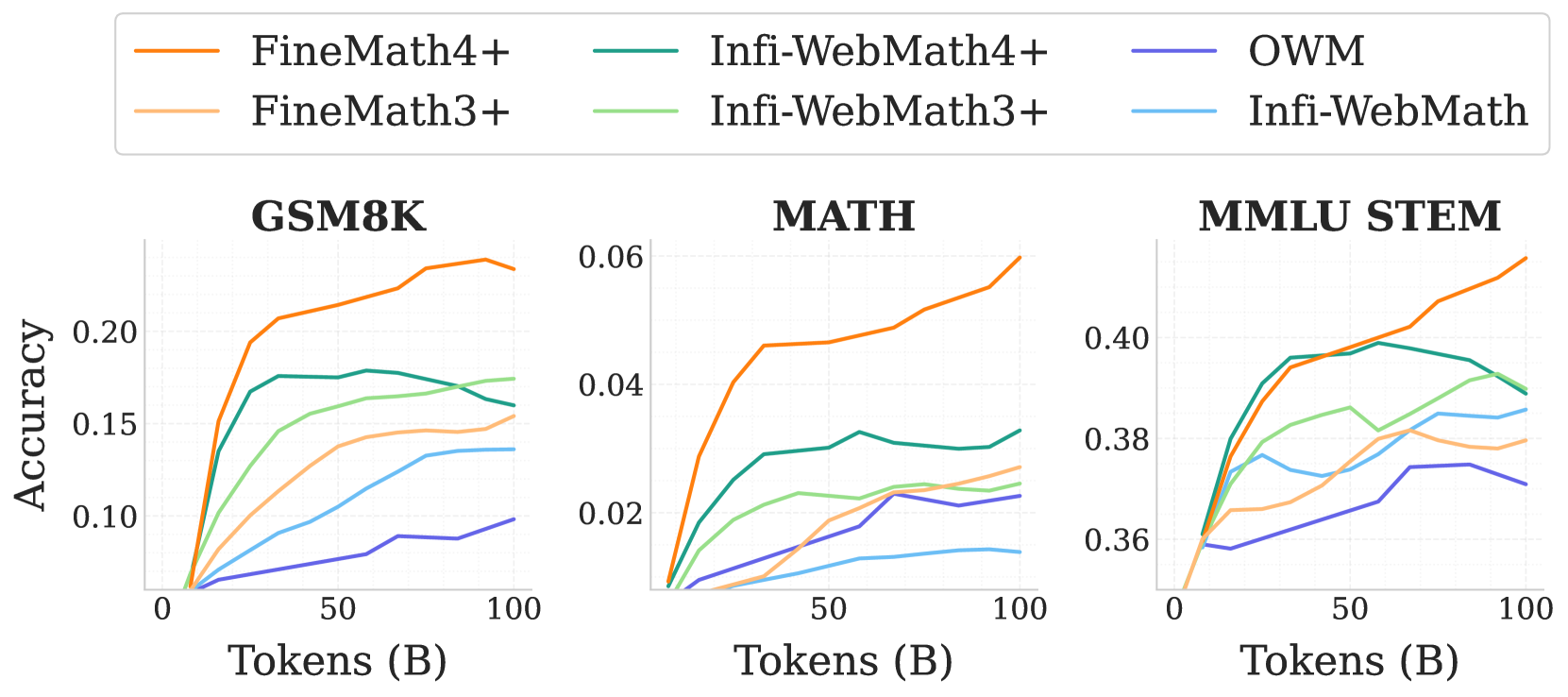
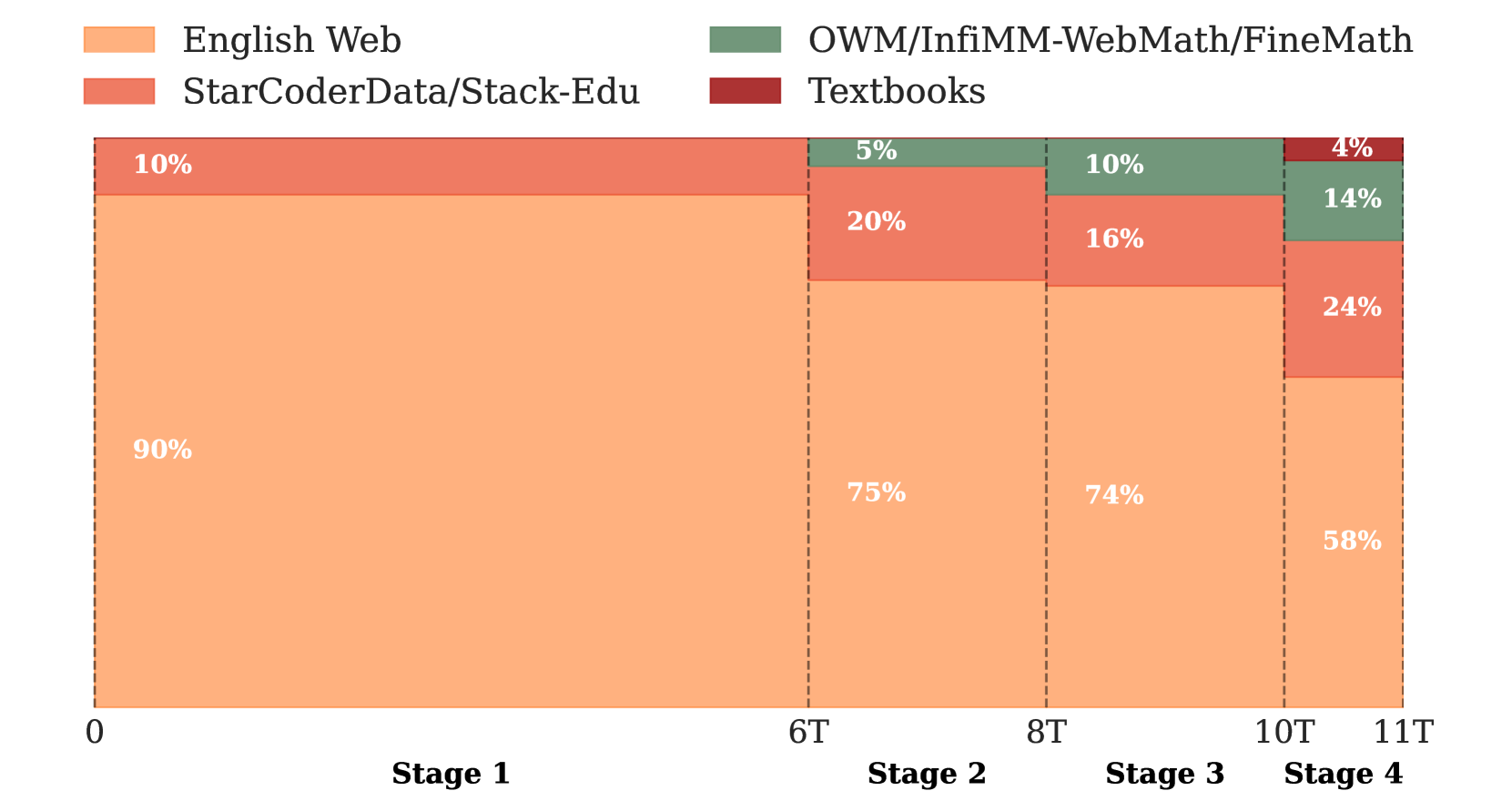
技术框架:SmolLM2的训练过程采用多阶段训练框架。首先,使用通用网络文本进行预训练。然后,在后续阶段,逐步引入专门的数学、代码和指令遵循数据,以增强模型在特定领域的性能。此外,还引入了新的专门数据集(FineMath、Stack-Edu和SmolTalk),以解决现有数据集规模或质量不足的问题。在每个阶段,根据模型在前一阶段的性能,手动调整数据集的混合比例。
关键创新:论文的关键创新在于数据为中心的训练方法和新数据集的引入。通过精心策划和混合训练数据,以及针对性地构建高质量数据集,显著提升了小型语言模型的性能。此外,手动调整数据集混合比例的策略,能够根据模型在不同阶段的学习情况,动态优化训练过程。
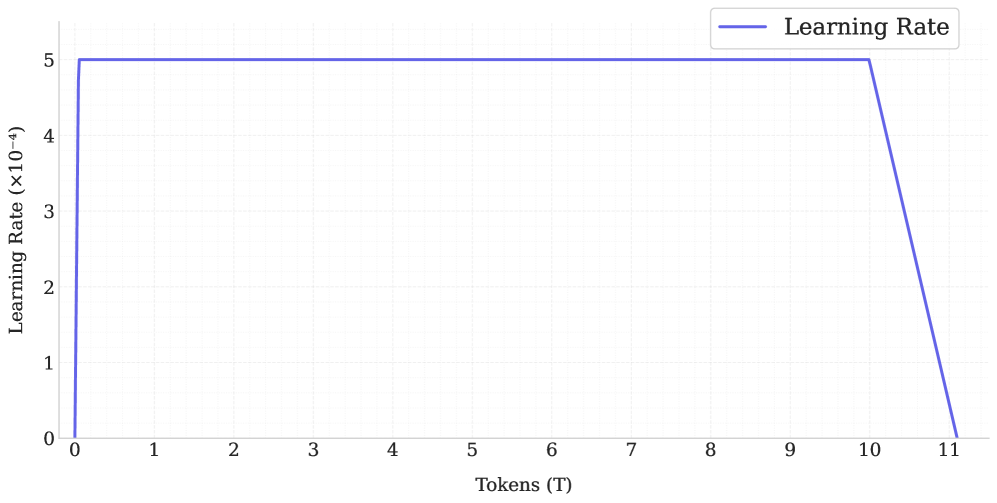
关键设计:SmolLM2模型参数量为17亿。训练数据包含约11万亿个token。多阶段训练过程中,数据集混合比例根据模型在每个阶段的性能进行手动调整。论文还设计了FineMath、Stack-Edu和SmolTalk等新的专门数据集,以提升模型在数学、编程和对话方面的能力。具体参数设置和损失函数等细节未在摘要中详细说明,需要查阅论文全文。
🖼️ 关键图片
📊 实验亮点
SmolLM2在17亿参数规模下,性能优于Qwen2.5-1.5B和Llama3.2-1B等其他同等规模的语言模型。论文通过多阶段训练和数据优化,显著提升了小型语言模型的性能,证明了数据为中心训练方法在小模型上的有效性。同时,论文开源了SmolLM2模型和所有准备的数据集,为后续研究提供了宝贵的资源。
🎯 应用场景
SmolLM2的潜在应用领域包括:边缘计算设备(如智能手机、物联网设备)、低算力服务器、嵌入式系统等。该研究的实际价值在于降低了语言模型的部署成本和资源需求,使其能够在更广泛的场景中应用。未来,这种小型高性能语言模型有望推动人工智能在资源受限环境中的普及。
📄 摘要(原文)
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.