Adaptive Self-improvement LLM Agentic System for ML Library Development
作者: Genghan Zhang, Weixin Liang, Olivia Hsu, Kunle Olukotun
分类: cs.CL
发布日期: 2025-02-04 (更新: 2025-09-19)
💡 一句话要点
提出自适应自提升LLM Agent系统,用于机器学习库的自动开发
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 机器学习库 代码生成 自适应学习 特定领域架构
📋 核心要点
- 现有方法难以利用LLM生成高性能ML库,主要挑战在于ASPL的复杂性和训练数据稀缺。
- 论文提出一种自适应自提升的Agent系统,通过迭代优化和自我反馈来提升LLM在ASPL代码生成方面的能力。
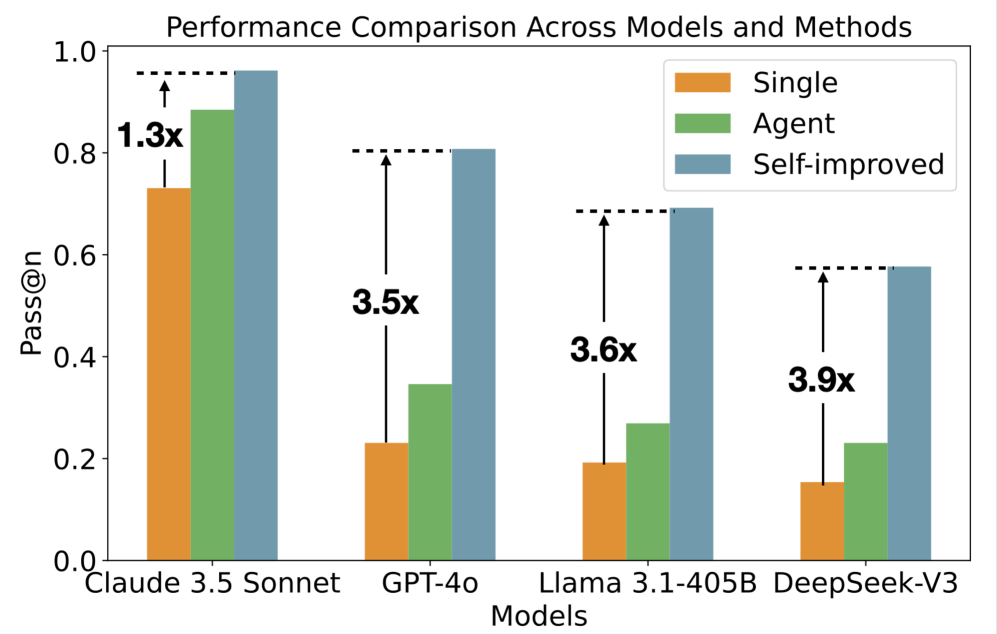
- 实验结果表明,该系统在ML库生成任务上显著优于单LLM,性能提升高达3.9倍。
📝 摘要(中文)
高效的机器学习系统依赖于特定架构编程语言(ASPL)编写的ML库。然而,编写这些高性能ML库极具挑战,因为它需要ML算法和ASPL的专业知识。大型语言模型(LLM)虽然展现了通用的编码能力,但将其用于使用ASPL生成ML库仍然面临挑战,原因在于:1)即使对于经验丰富的程序员来说,这项任务也很复杂;2)由于ASPL的深奥性和不断发展的特性,可用的代码示例有限。因此,LLM需要有限数据下的复杂推理才能完成此任务。为了应对这些挑战,我们引入了一种自适应自提升的Agent系统。为了评估我们系统的有效性,我们构建了一个典型ML库的基准,并在此基准上使用开源和闭源LLM生成ASPL代码。结果表明,相比于基线单LLM,性能提升高达3.9倍。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型(LLM)自动生成针对特定领域架构的机器学习(ML)库代码的问题。现有方法,即直接使用LLM生成代码,面临两个主要痛点:一是即使对于经验丰富的程序员来说,使用ASPL编写ML库代码也是一项复杂的任务;二是由于ASPL的专业性和快速发展,可用的训练数据非常有限。因此,LLM难以在缺乏足够训练数据的情况下进行有效的复杂推理和代码生成。
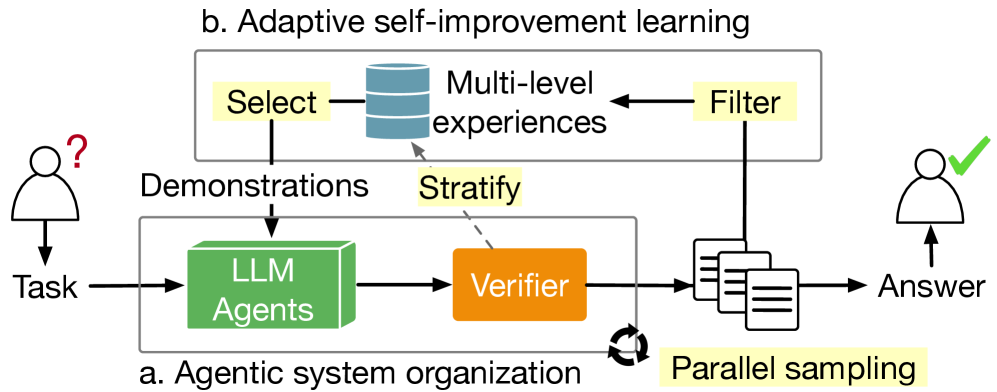
核心思路:论文的核心思路是构建一个自适应自提升的Agent系统,该系统能够通过迭代优化和自我反馈来逐步提升LLM在ASPL代码生成方面的能力。该系统模拟了人类专家在解决复杂问题时的学习和改进过程,通过不断试错、评估和调整,最终生成高质量的ML库代码。
技术框架:该Agent系统包含以下主要模块:1) LLM代码生成器:负责根据任务描述和上下文信息生成ASPL代码;2) 代码执行器:负责执行生成的代码,并收集执行结果和性能指标;3) 评估器:负责评估代码的质量和性能,并生成反馈信息;4) 改进器:负责根据反馈信息调整LLM的参数和策略,以提升代码生成能力。整个流程是一个迭代循环,LLM不断生成代码、执行代码、评估代码、改进代码,最终达到预期的性能目标。
关键创新:该论文最重要的技术创新点在于提出了自适应自提升的Agent系统,该系统能够有效地利用有限的数据进行复杂推理和代码生成。与直接使用LLM生成代码相比,该系统能够通过迭代优化和自我反馈来显著提升代码的质量和性能。此外,该系统还能够根据不同的任务和ASPL进行自适应调整,具有很强的通用性和可扩展性。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节。但是,可以推断,评估器可能使用了诸如代码覆盖率、执行时间、内存占用等指标来评估代码的质量和性能。改进器可能使用了强化学习或进化算法等方法来调整LLM的参数和策略。具体的实现细节可能需要参考相关的文献或代码。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该自适应自提升Agent系统在ML库生成任务上显著优于基线单LLM。在特定基准测试中,该系统相比于单LLM,性能提升高达3.9倍。这表明该系统能够有效地利用有限的数据进行复杂推理和代码生成,具有很强的实用价值。
🎯 应用场景
该研究成果可应用于自动化机器学习库开发,降低开发成本,提高开发效率。尤其是在特定领域架构上,可以快速生成优化的ML库,加速相关应用的落地。未来,该技术有望扩展到其他领域的代码生成,例如操作系统、数据库等。
📄 摘要(原文)
ML libraries, often written in architecture-specific programming languages (ASPLs) that target domain-specific architectures, are key to efficient ML systems. However, writing these high-performance ML libraries is challenging because it requires expert knowledge of ML algorithms and the ASPL. Large language models (LLMs), on the other hand, have shown general coding capabilities. However, challenges remain when using LLMs for generating ML libraries using ASPLs because 1) this task is complicated even for experienced human programmers and 2) there are limited code examples because of the esoteric and evolving nature of ASPLs. Therefore, LLMs need complex reasoning with limited data in order to complete this task. To address these challenges, we introduce an adaptive self-improvement agentic system. In order to evaluate the effectiveness of our system, we construct a benchmark of a typical ML library and generate ASPL code with both open and closed-source LLMs on this benchmark. Our results show improvements of up to $3.9\times$ over a baseline single LLM.