SAISA: Towards Multimodal Large Language Models with Both Training and Inference Efficiency
作者: Qianhao Yuan, Yanjiang Liu, Yaojie Lu, Hongyu Lin, Ben He, Xianpei Han, Le Sun
分类: cs.CL, cs.CV
发布日期: 2025-02-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出SAISA,一种提升训练和推理效率的多模态大语言模型架构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 训练效率 推理效率 自注意力机制 视觉语言对齐
📋 核心要点
- 现有MLLM在训练和推理效率上存在trade-off,嵌入空间对齐推理慢,交叉注意力空间对齐训练慢。
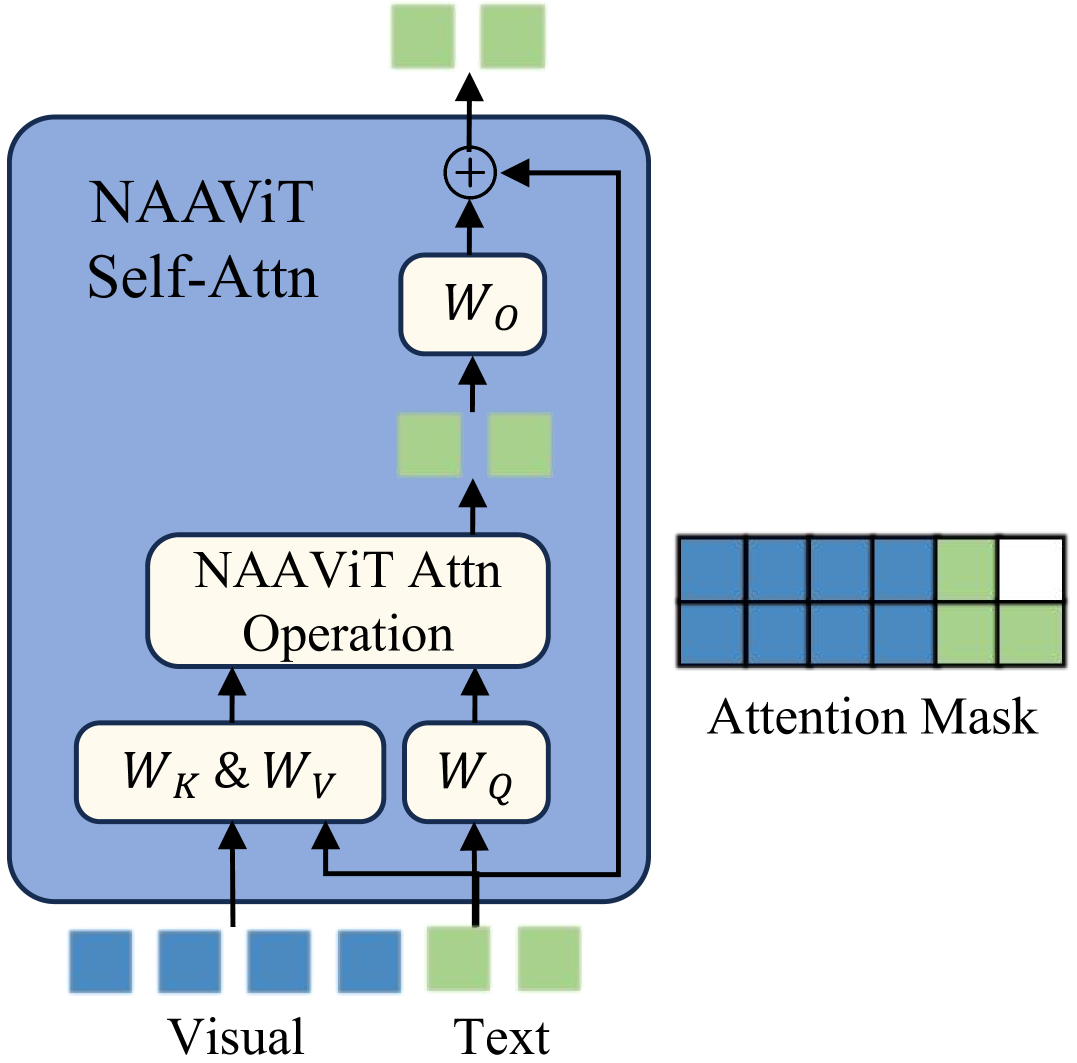
- 提出SAISA架构,通过消除视觉tokens间的自注意力(NAAViT),并直接对齐视觉特征到自注意力输入空间,提升效率。
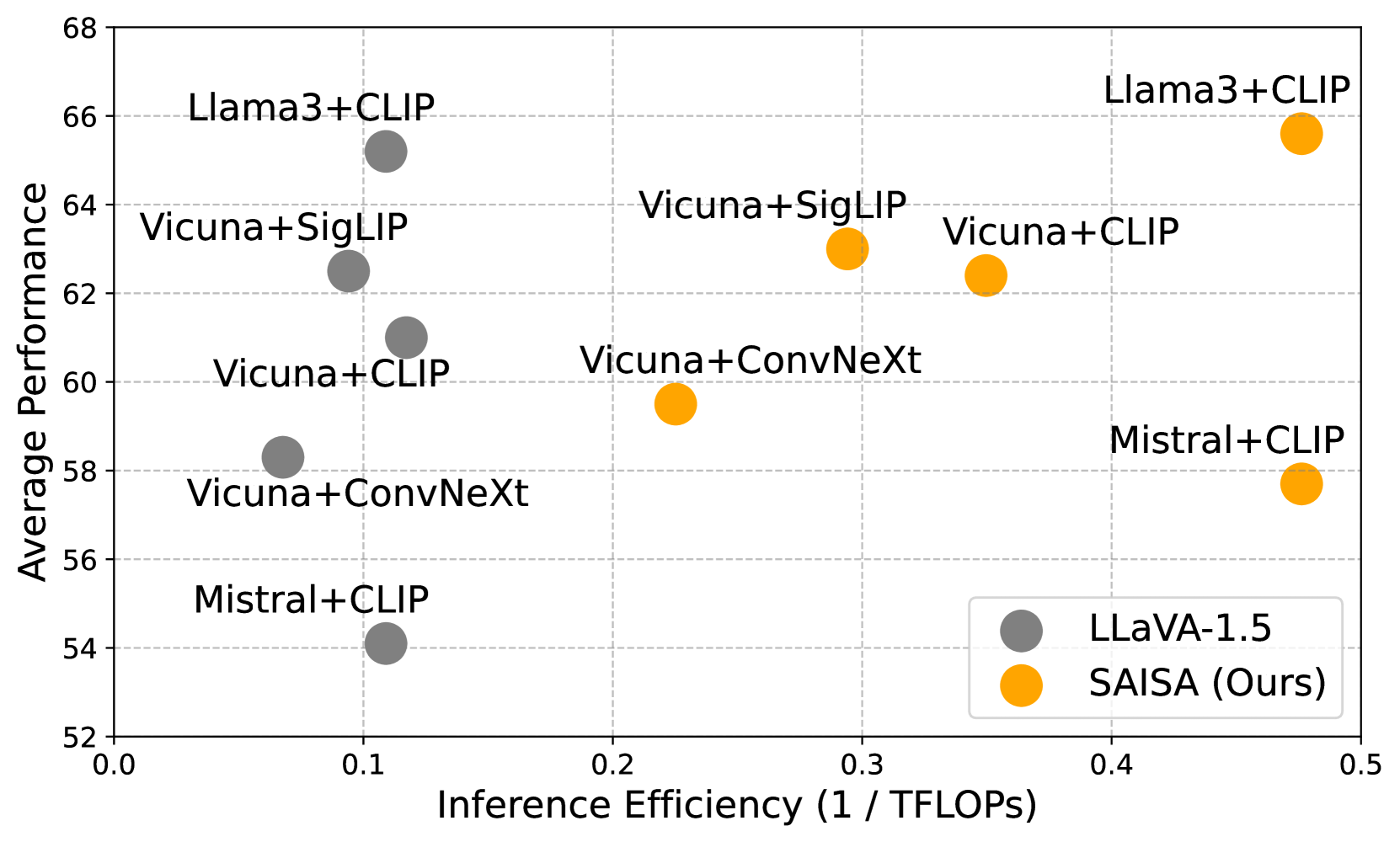
- 实验表明,SAISA在保持或提升准确率的同时,显著降低了推理FLOPs(66%)和训练预算(26%)。
📝 摘要(中文)
多模态大语言模型(MLLMs)主要分为两种架构,它们在训练和推理效率之间存在权衡:嵌入空间对齐(如LLaVA-1.5)在推理过程中效率较低,而交叉注意力空间对齐(如Flamingo)在训练过程中效率较低。本文比较了这两种架构,并确定了构建高效MLLM的关键因素。它们之间的一个主要区别在于注意力如何应用于视觉tokens,特别是它们彼此之间的交互。为了研究视觉tokens之间的注意力是否必要,我们提出了一种新的自注意力机制NAAViT( extbf{N}o extbf{A}ttention extbf{A}mong extbf{Vi}sual extbf{T}okens),它消除了这种类型的注意力。我们在LLaVA-1.5上的初步实验表明,视觉tokens之间的注意力是高度冗余的。基于这些见解,我们引入了SAISA( extbf{S}elf- extbf{A}ttention extbf{I}nput extbf{S}pace extbf{A}lignment),一种新的架构,可以提高训练和推理效率。SAISA直接将视觉特征与NAAViT自注意力块的输入空间对齐,从而减少了自注意力块和前馈网络(FFN)中的计算开销。使用与LLaVA-1.5相同的配置,SAISA将推理FLOPs降低了66%,训练预算降低了26%,同时在准确性方面实现了卓越的性能。全面的消融研究进一步验证了SAISA在各种LLM和视觉编码器中的有效性。代码和模型将在https://github.com/icip-cas/SAISA上公开发布。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLMs)在训练和推理效率上存在瓶颈。嵌入空间对齐的方法(如LLaVA-1.5)在推理时需要大量的计算资源,而交叉注意力空间对齐的方法(如Flamingo)在训练时计算成本很高。因此,如何设计一种既能高效训练又能高效推理的MLLM是一个关键问题。
核心思路:论文的核心思路是减少视觉tokens之间的冗余计算。作者通过实验发现,视觉tokens之间的自注意力在MLLM中是高度冗余的,因此提出了NAAViT机制,即No Attention Among Visual Tokens。在此基础上,SAISA架构通过将视觉特征直接对齐到NAAViT自注意力块的输入空间,进一步减少了计算开销。
技术框架:SAISA架构主要包含视觉编码器、线性投影层、NAAViT自注意力块和语言模型。视觉编码器负责提取图像特征,线性投影层将视觉特征映射到与语言模型输入空间相同的维度。NAAViT自注意力块处理视觉和文本特征,语言模型则负责生成文本。整体流程是:图像通过视觉编码器提取特征,然后通过线性投影层对齐到语言模型的输入空间,再与文本tokens一起输入到NAAViT自注意力块中进行处理,最后由语言模型生成文本。
关键创新:SAISA的关键创新在于NAAViT自注意力机制和自注意力输入空间对齐。NAAViT通过消除视觉tokens之间的自注意力,显著减少了计算量。自注意力输入空间对齐则避免了额外的特征转换,进一步提高了效率。与现有方法相比,SAISA在不损失甚至提升性能的情况下,显著降低了训练和推理的计算成本。
关键设计:NAAViT自注意力块的设计关键在于移除视觉tokens之间的自注意力计算。具体实现方式是,在计算注意力权重时,只考虑视觉tokens与文本tokens之间的关系,而不考虑视觉tokens之间的关系。此外,SAISA使用线性投影层将视觉特征映射到与语言模型输入空间相同的维度,避免了复杂的非线性变换。损失函数方面,SAISA沿用了LLaVA-1.5的损失函数,即next token prediction loss。
🖼️ 关键图片

📊 实验亮点
SAISA在与LLaVA-1.5相同的配置下,将推理FLOPs降低了66%,训练预算降低了26%,同时在准确性方面实现了卓越的性能。消融实验验证了NAAViT自注意力机制和自注意力输入空间对齐的有效性。实验结果表明,SAISA在各种LLM和视觉编码器中都具有良好的泛化能力。
🎯 应用场景
SAISA架构具有广泛的应用前景,例如在智能客服、图像描述、视觉问答等领域。由于其高效的训练和推理能力,SAISA可以部署在资源受限的设备上,例如移动设备和嵌入式系统。此外,SAISA还可以用于构建更大规模的多模态模型,从而提高模型的性能和泛化能力。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) mainly fall into two architectures, each involving a trade-off between training and inference efficiency: embedding space alignment (e.g., LLaVA-1.5) is inefficient during inference, while cross-attention space alignment (e.g., Flamingo) is inefficient in training. In this paper, we compare these two architectures and identify the key factors for building efficient MLLMs. A primary difference between them lies in how attention is applied to visual tokens, particularly in their interactions with each other. To investigate whether attention among visual tokens is necessary, we propose a new self-attention mechanism, NAAViT (\textbf{N}o \textbf{A}ttention \textbf{A}mong \textbf{Vi}sual \textbf{T}okens), which eliminates this type of attention. Our pilot experiment on LLaVA-1.5 shows that attention among visual tokens is highly redundant. Based on these insights, we introduce SAISA (\textbf{S}elf-\textbf{A}ttention \textbf{I}nput \textbf{S}pace \textbf{A}lignment), a novel architecture that enhance both training and inference efficiency. SAISA directly aligns visual features with the input spaces of NAAViT self-attention blocks, reducing computational overhead in both self-attention blocks and feed-forward networks (FFNs). Using the same configuration as LLaVA-1.5, SAISA reduces inference FLOPs by 66\% and training budget by 26\%, while achieving superior performance in terms of accuracy. Comprehensive ablation studies further validate the effectiveness of SAISA across various LLMs and visual encoders. The code and model will be publicly available at https://github.com/icip-cas/SAISA.