Premise-Augmented Reasoning Chains Improve Error Identification in Math reasoning with LLMs
作者: Sagnik Mukherjee, Abhinav Chinta, Takyoung Kim, Tarun Anoop Sharma, Dilek Hakkani-Tür
分类: cs.CL
发布日期: 2025-02-04 (更新: 2025-09-23)
备注: Accepted at ICML 2025
💡 一句话要点
提出PARC:通过前提增强推理链提升LLM数学推理中的错误识别
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 思维链 前提增强 错误识别 有向无环图 可解释性
📋 核心要点
- LLM的思维链(CoT)推理虽然增强了数学推理能力,但冗长的推理链使得验证和问题追踪变得困难。
- 论文提出前提增强推理链(PARC),通过显式地链接每个推理步骤的前提,将线性推理链转化为有向无环图。
- 实验表明,LLM能有效识别前提,且PARC能显著提升推理错误识别的准确率,最高提升达16%。
📝 摘要(中文)
本文提出了一种新的框架,通过识别每个步骤的前提来改进对LLM推理过程的评估。该框架将传统的线性推理链重构为前提增强推理链(PARC),通过引入前提链接,形成一个有向无环图,其中节点代表步骤,边代表前提链接。论文构建了一个基于PARC的数据集PERL(LLM中前提和错误识别),实验表明LLM能够可靠地识别复杂推理链中的前提。即使是开源LLM也能在前提识别中达到90%的召回率。PARC还有助于更可靠地识别推理链中的错误,在前提条件下进行逐步验证时,错误识别的准确率提高了6%到16%。研究结果强调了以前提为中心的表示在解决复杂问题中的效用,并为提高基于LLM的推理评估的可靠性开辟了新途径。
🔬 方法详解
问题定义:现有的大语言模型(LLM)在进行数学推理时,通常采用思维链(Chain-of-Thought, CoT)的方式,生成逐步的解决方案。然而,由于LLM的冗长性,生成的推理链可能非常长,这使得验证每个步骤的正确性以及追踪由步骤之间的依赖关系导致的问题变得困难。尤其当依赖的步骤在序列中相隔较远时,问题定位更加困难。
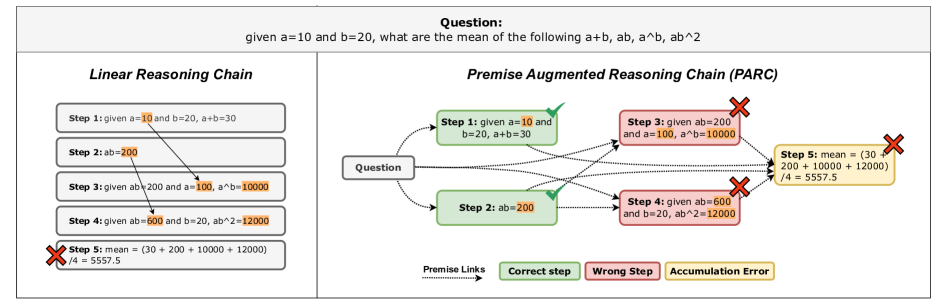
核心思路:论文的核心思路是将传统的线性推理链转化为一种更结构化的表示,即前提增强推理链(Premise Augmented Reasoning Chains, PARC)。PARC通过显式地识别并链接每个推理步骤所依赖的前提,从而形成一个有向无环图。这种结构化的表示使得错误定位和推理验证更加容易。
技术框架:PARC框架主要包含以下几个步骤:1) 对于给定的数学问题,首先使用LLM生成一个初始的线性推理链。2) 然后,对于推理链中的每一个步骤,使用LLM来识别该步骤所依赖的前提,即推理链中之前的哪些步骤是推导出当前步骤所必需的。3) 基于识别出的前提,构建一个有向无环图,其中节点代表推理步骤,边代表前提链接。4) 最后,利用构建好的PARC进行错误识别和推理验证。
关键创新:论文的关键创新在于提出了PARC这种新的推理表示方法。与传统的线性推理链相比,PARC通过显式地表示步骤之间的依赖关系,使得推理过程更加透明和可解释。这种结构化的表示方式使得错误定位和推理验证更加容易,并且可以提高LLM推理的可靠性。
关键设计:论文构建了一个名为PERL(Premises and ERrors identification in LLMs)的数据集,用于评估PARC的性能。PERL数据集包含数学问题、对应的线性推理链以及每个步骤的前提标注。实验中,使用了不同的LLM(包括开源和闭源模型)来识别前提和错误。评估指标包括前提识别的召回率和错误识别的准确率。没有特别提及损失函数或网络结构等技术细节,重点在于PARC的结构和应用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是开源LLM也能在前提识别中达到90%的召回率。此外,PARC显著提升了推理错误识别的准确率,在前提条件下进行逐步验证时,错误识别的准确率提高了6%到16%。这些结果验证了PARC在提高LLM推理可靠性方面的有效性。
🎯 应用场景
该研究成果可应用于提升LLM在数学、逻辑推理等领域的可靠性和可解释性。通过PARC,可以更有效地诊断LLM推理过程中的错误,从而改进模型训练和推理策略。此外,该方法还可以应用于教育领域,帮助学生理解数学推理的步骤和依赖关系。
📄 摘要(原文)
Chain-of-Thought (CoT) prompting enhances mathematical reasoning in large language models (LLMs) by enabling detailed step-by-step solutions. However, due to the verbosity of LLMs, the resulting reasoning chains can be long, making it harder to verify the reasoning steps and trace issues resulting from dependencies between the steps that may be farther away in the sequence of steps. Importantly, mathematical reasoning allows each step to be derived from a small set of premises, which are a subset of the preceding steps in the reasoning chain. In this paper, we present a framework that identifies the premises for each step, to improve the evaluation of reasoning. We restructure conventional linear reasoning chains into Premise Augmented Reasoning Chains (PARC) by introducing premise links, resulting in a directed acyclic graph where the nodes are the steps and the edges are the premise links. Through experiments with a PARC-based dataset that we built, namely PERL (Premises and ERrors identification in LLMs), we demonstrate that LLMs can reliably identify premises within complex reasoning chains. In particular, even open-source LLMs achieve 90% recall in premise identification. We also show that PARC helps to identify errors in reasoning chains more reliably. The accuracy of error identification improves by 6% to 16% absolute when step-by-step verification is carried out in PARC under the premises. Our findings highlight the utility of premise-centric representations in addressing complex problem-solving tasks and open new avenues for improving the reliability of LLM-based reasoning evaluations.