ReSpark: Leveraging Previous Data Reports as References to Generate New Reports with LLMs
作者: Yuan Tian, Chuhan Zhang, Xiaotong Wang, Sitong Pan, Weiwei Cui, Haidong Zhang, Dazhen Deng, Yingcai Wu
分类: cs.HC, cs.CL
发布日期: 2025-02-04 (更新: 2025-09-30)
💡 一句话要点
ReSpark:利用LLM和历史报告生成新数据报告,降低分析门槛
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据报告生成 大型语言模型 分析逻辑提取 知识迁移 人机交互
📋 核心要点
- 现有数据报告生成依赖手动分析逻辑构建,过程繁琐且认知负担重,难以复用。
- ReSpark利用LLM从现有报告中提取分析逻辑,并将其适配到新的数据集上,自动生成分析步骤草案。
- 通过比较研究和用户研究,验证了ReSpark在降低数据报告生成门槛方面的有效性。
📝 摘要(中文)
创建数据报告是一项劳动密集型任务,涉及迭代的数据探索、洞察提取和叙述构建。一个关键挑战在于构建分析逻辑——从定义目标和转换数据到识别和交流洞察。手动构建这种逻辑在认知上要求很高。虽然经验丰富的分析师经常重用过去项目的脚本,但为新数据集找到完全匹配的脚本很少见。即使在线提供类似的分析,它们通常只共享结果或可视化,而不共享底层代码,这使得重用变得困难。为了解决这个问题,我们提出了ReSpark,一个利用大型语言模型(LLM)从现有报告中逆向工程分析逻辑并将其适应于新数据集的系统。通过生成分析步骤草案,ReSpark为用户提供了一个良好的开端。它还支持交互式改进,允许用户检查中间输出、插入目标和修改内容。我们通过比较研究和用户研究评估了ReSpark,证明了它在降低生成数据报告的门槛方面的有效性,而无需依赖现有的分析代码。
🔬 方法详解
问题定义:数据报告生成过程复杂,需要数据探索、洞察提取和叙述构建,手动构建分析逻辑耗时耗力。现有方法难以复用历史分析代码,即使有相似的分析,也往往只提供结果或可视化,缺乏底层代码,阻碍了知识的迁移和复用。
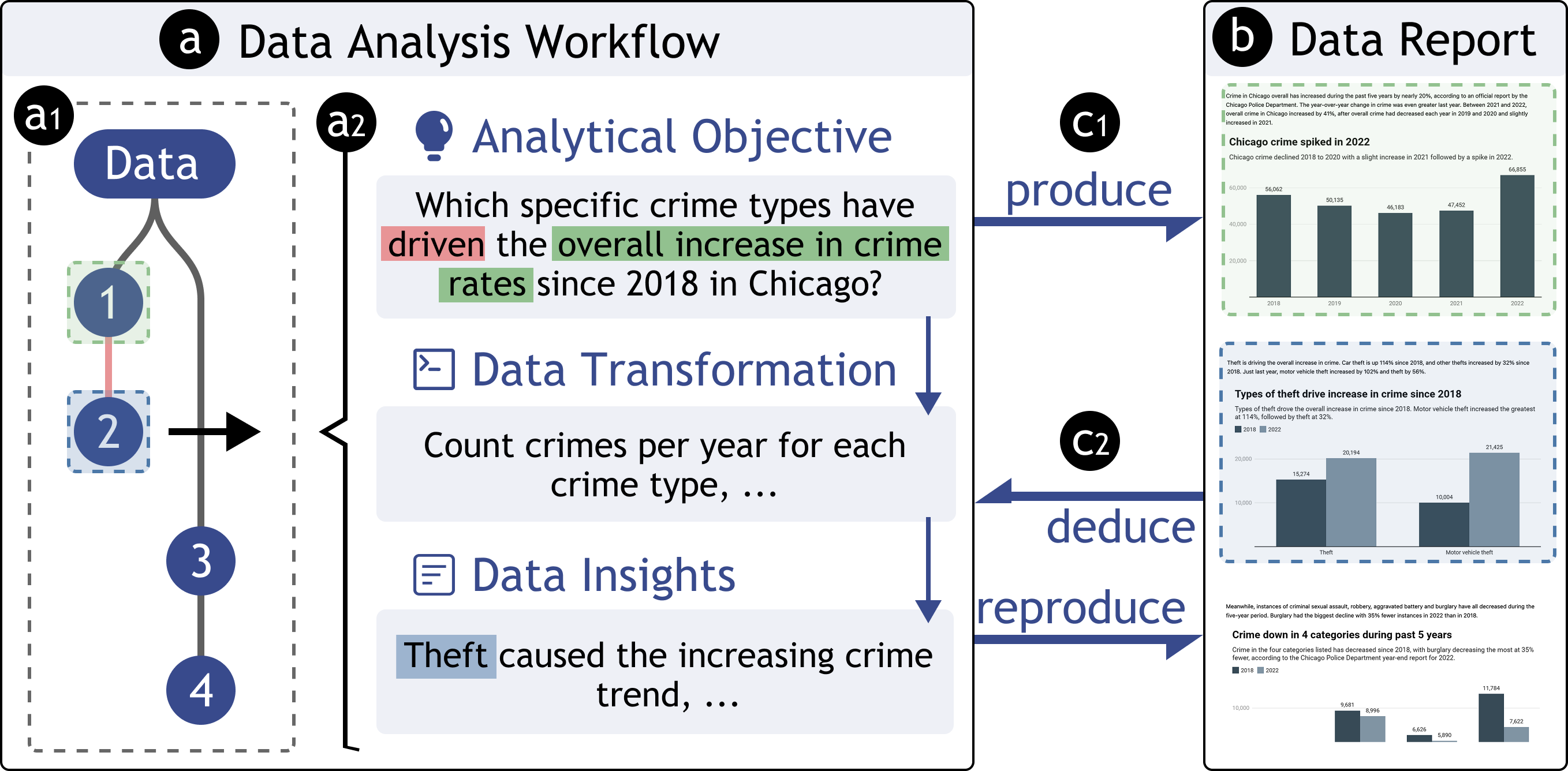
核心思路:利用大型语言模型(LLM)的强大能力,从现有的数据报告中逆向工程分析逻辑,并将其迁移到新的数据集上。通过LLM生成分析步骤的草案,为用户提供一个良好的起点,降低数据报告生成的门槛。
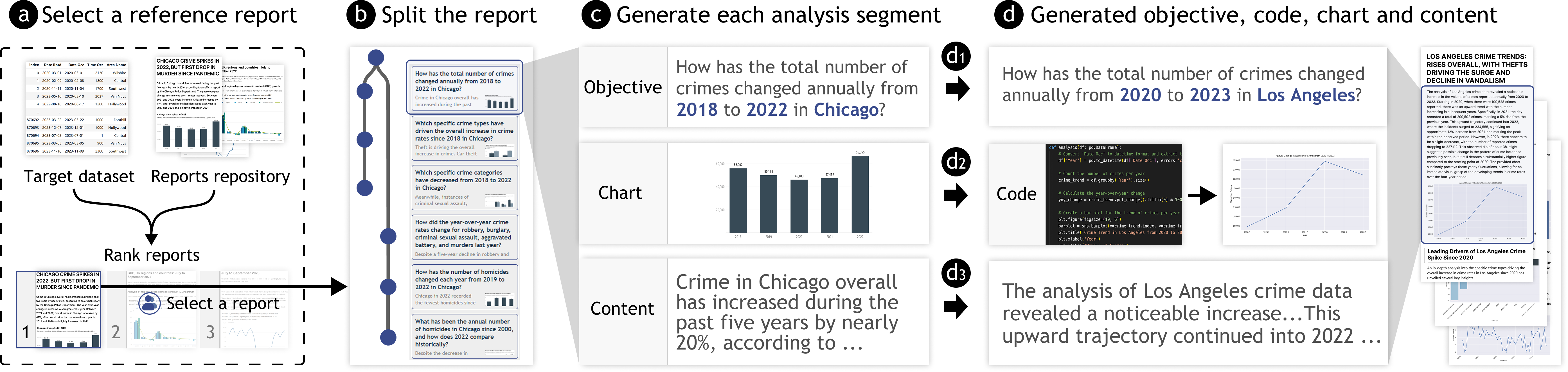
技术框架:ReSpark系统主要包含以下几个阶段:1) 输入现有数据报告和新的数据集;2) 利用LLM分析现有报告,提取分析逻辑;3) 将提取的分析逻辑适配到新的数据集上,生成分析步骤草案;4) 用户交互式改进,包括检查中间输出、插入目标和修改内容。
关键创新:ReSpark的核心创新在于利用LLM自动提取和迁移数据报告的分析逻辑,无需人工编写代码,降低了数据报告生成的门槛。与传统方法相比,ReSpark能够从现有的报告中学习,并将知识迁移到新的数据集上,提高了效率和可复用性。
关键设计:ReSpark的具体实现细节未知,论文中没有详细描述LLM的具体选择、prompt的设计、以及如何将分析逻辑适配到新的数据集上。这些细节可能涉及到复杂的自然语言处理和数据分析技术。
🖼️ 关键图片

📊 实验亮点
论文通过比较研究和用户研究验证了ReSpark的有效性。具体性能数据未知,但研究表明ReSpark能够显著降低生成数据报告的门槛,无需依赖现有的分析代码。用户研究也表明,ReSpark能够帮助用户更快地生成数据报告,并提高报告的质量。
🎯 应用场景
ReSpark可应用于各种需要生成数据报告的领域,例如商业分析、科学研究、金融分析等。它可以帮助分析师快速生成数据报告草案,节省时间和精力,提高工作效率。此外,ReSpark还可以降低数据分析的门槛,使更多的人能够参与到数据分析中来。
📄 摘要(原文)
Creating data reports is a labor-intensive task involving iterative data exploration, insight extraction, and narrative construction. A key challenge lies in composing the analysis logic-from defining objectives and transforming data to identifying and communicating insights. Manually crafting this logic can be cognitively demanding. While experienced analysts often reuse scripts from past projects, finding a perfect match for a new dataset is rare. Even when similar analyses are available online, they usually share only results or visualizations, not the underlying code, making reuse difficult. To address this, we present ReSpark, a system that leverages large language models (LLMs) to reverse-engineer analysis logic from existing reports and adapt it to new datasets. By generating draft analysis steps, ReSpark provides a warm start for users. It also supports interactive refinement, allowing users to inspect intermediate outputs, insert objectives, and revise content. We evaluate ReSpark through comparative and user studies, demonstrating its effectiveness in lowering the barrier to generating data reports without relying on existing analysis code.