Reasoning Bias of Next Token Prediction Training
作者: Pengxiao Lin, Zhongwang Zhang, Zhi-Qin John Xu
分类: cs.CL, cs.LG
发布日期: 2025-02-04 (更新: 2025-02-20)
备注: 19 pages, 11 figures
💡 一句话要点
揭示NTP训练的推理偏好:噪声正则化提升LLM泛化与鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 下一个token预测 关键token预测 推理能力 噪声正则化
📋 核心要点
- 现有LLM训练方法在推理能力上存在瓶颈,尤其是在噪声环境下,容易过拟合无关信息。
- 论文提出NTP训练方法,通过噪声的正则化作用,提升模型在推理任务上的泛化性和鲁棒性。
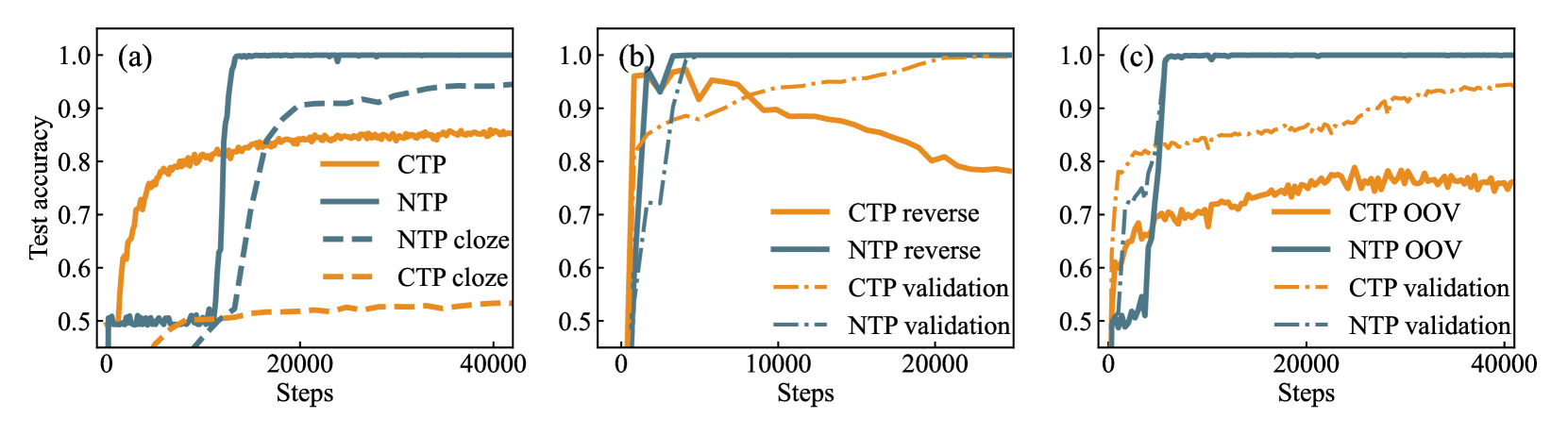
- 实验结果表明,NTP训练的模型在多个推理数据集上优于CTP,且对扰动更具抵抗力。
📝 摘要(中文)
大型语言模型(LLM)训练的关键挑战在于如何高效地提升其推理能力。目前主流的训练范式是基于下一个token预测(NTP)。另一种方法,关键token预测(CTP),则专注于预测特定的关键token(例如问答数据集中的答案),旨在减少无关信息和噪声的过拟合。与最初的假设相反,我们的研究表明,尽管NTP在训练过程中暴露于噪声,但其推理能力优于CTP。我们将这种反直觉的结果归因于噪声对训练动态的正则化影响。我们的经验分析表明,NTP训练的模型在各种基准推理数据集上表现出更强的泛化性和鲁棒性,对扰动具有更强的抵抗力,并实现了更平坦的损失最小值。这些发现表明,NTP有助于在预训练期间培养推理能力,而CTP更适合微调,从而丰富了我们对LLM开发中最佳训练策略的理解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)训练中,如何更有效地提升模型推理能力的问题。现有方法,如关键token预测(CTP),虽然试图减少噪声干扰,但可能导致模型泛化能力不足。因此,如何平衡噪声与模型性能,是本文要解决的核心问题。
核心思路:论文的核心思路是,虽然下一个token预测(NTP)训练过程中会引入噪声,但这种噪声实际上起到了正则化的作用,有助于模型学习到更鲁棒的特征表示,从而提升其泛化能力和推理能力。这种噪声正则化效应使得模型能够更好地抵抗扰动,并找到更平坦的损失最小值。
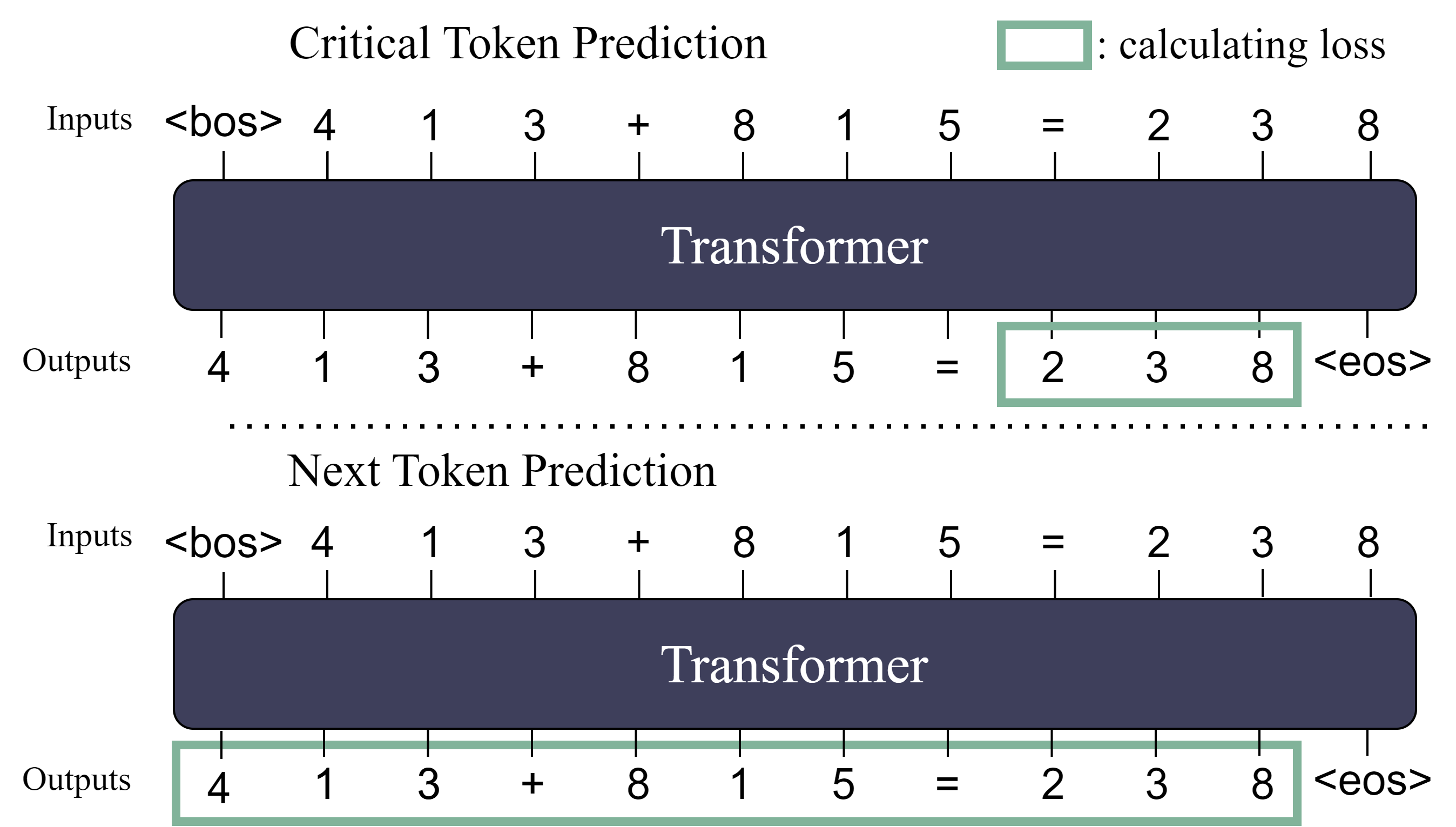
技术框架:论文主要通过对比NTP和CTP两种训练范式,来分析噪声对模型推理能力的影响。整体流程包括:1)使用NTP和CTP分别训练LLM;2)在多个推理基准数据集上评估模型的性能;3)分析模型对扰动的抵抗能力;4)研究损失函数的最小值形态。
关键创新:论文最重要的创新点在于,颠覆了以往认为噪声会损害模型性能的认知,揭示了NTP训练中噪声的正则化作用。与CTP相比,NTP通过引入噪声,反而提升了模型的泛化能力和鲁棒性,使其在推理任务上表现更佳。
关键设计:论文的关键设计在于对比了NTP和CTP两种训练方法。NTP训练使用标准的下一个token预测目标函数,而CTP则只预测关键token。通过控制训练数据和目标函数的差异,研究人员能够更清晰地观察到噪声对模型性能的影响。具体的参数设置和网络结构可能与所使用的LLM架构有关,论文中可能未详细说明。
🖼️ 关键图片

📊 实验亮点
研究表明,NTP训练的模型在多个基准推理数据集上表现出更强的泛化性和鲁棒性,优于CTP训练的模型。NTP训练的模型对扰动具有更强的抵抗力,并且能够达到更平坦的损失最小值,这表明NTP训练有助于模型学习到更鲁棒的特征表示。
🎯 应用场景
该研究成果可应用于各种需要强大推理能力的自然语言处理任务,例如问答系统、机器翻译、文本摘要等。通过采用合适的训练策略,可以提升LLM在实际应用中的性能和可靠性。未来的研究可以进一步探索如何更有效地利用噪声进行正则化,并将其应用于其他机器学习模型。
📄 摘要(原文)
Since the inception of Large Language Models (LLMs), the quest to efficiently train them for superior reasoning capabilities has been a pivotal challenge. The dominant training paradigm for LLMs is based on next token prediction (NTP). Alternative methodologies, called Critical Token Prediction (CTP), focused exclusively on specific critical tokens (such as the answer in Q\&A dataset), aiming to reduce the overfitting of extraneous information and noise. Contrary to initial assumptions, our research reveals that despite NTP's exposure to noise during training, it surpasses CTP in reasoning ability. We attribute this counterintuitive outcome to the regularizing influence of noise on the training dynamics. Our empirical analysis shows that NTP-trained models exhibit enhanced generalization and robustness across various benchmark reasoning datasets, demonstrating greater resilience to perturbations and achieving flatter loss minima. These findings illuminate that NTP is instrumental in fostering reasoning abilities during pretraining, whereas CTP is more effective for finetuning, thereby enriching our comprehension of optimal training strategies in LLM development.