CITER: Collaborative Inference for Efficient Large Language Model Decoding with Token-Level Routing
作者: Wenhao Zheng, Yixiao Chen, Weitong Zhang, Souvik Kundu, Yun Li, Zhengzhong Liu, Eric P. Xing, Hongyi Wang, Huaxiu Yao
分类: cs.CL, cs.AI, cs.LG, cs.PF
发布日期: 2025-02-04 (更新: 2025-09-10)
🔗 代码/项目: GITHUB
💡 一句话要点
CITER:通过令牌级路由实现高效大语言模型协同推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理加速 令牌级路由 策略优化 资源受限 协同推理 模型选择
📋 核心要点
- 现有大语言模型推理计算成本高,难以在资源受限场景部署。
- CITER通过令牌级路由,将非关键令牌交给小模型处理,关键令牌交给大模型处理,实现效率与质量的平衡。
- 实验表明,CITER在降低推理成本的同时,保持了高质量的生成效果,适用于实时和资源受限应用。
📝 摘要(中文)
大型语言模型在各种任务中取得了显著成功,但在推理过程中计算成本高昂,限制了其在资源受限应用中的部署。为了解决这个问题,我们提出了一种新颖的协同推理框架,称为CITER,它通过令牌级路由策略实现小型和大型语言模型(SLM和LLM)之间的高效协作。具体来说,CITER将非关键令牌路由到SLM以提高效率,并将关键令牌路由到LLM以提高泛化质量。我们将路由器训练建模为策略优化,其中路由器根据预测质量和生成推理成本获得奖励。这使得路由器能够学习预测令牌级路由分数,并根据当前令牌及其决策的未来影响做出路由决策。为了进一步加速奖励评估过程,我们引入了一种快捷方式,显著降低了奖励估计的成本,提高了我们方法的实用性。在五个基准数据集上的大量实验表明,CITER降低了推理成本,同时保持了高质量的生成,为实时和资源受限的应用提供了一个有希望的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推理过程中计算成本过高的问题,尤其是在资源受限的场景下。现有的方法要么只使用小型模型(SLM)牺牲性能,要么只使用大型模型(LLM)成本过高,无法兼顾效率和质量。
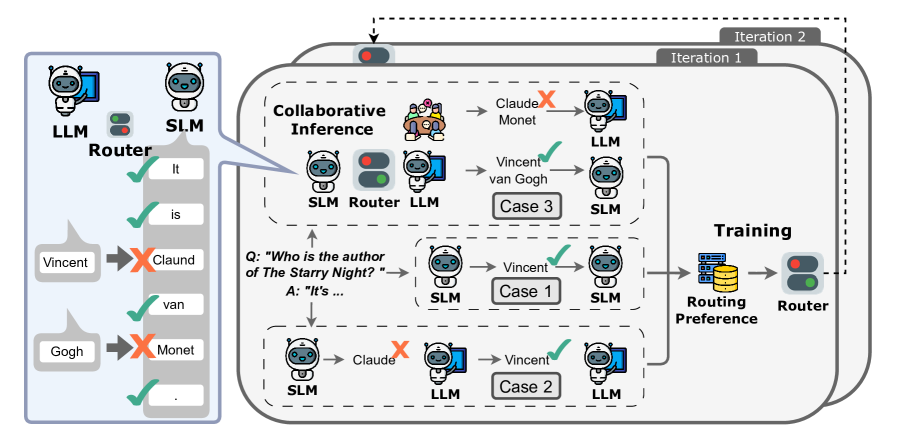
核心思路:论文的核心思路是利用令牌级路由,根据每个令牌的重要性,动态地选择使用小型模型(SLM)或大型模型(LLM)进行处理。对于非关键的令牌,使用SLM以降低计算成本;对于关键的令牌,使用LLM以保证生成质量。通过这种方式,在整体上降低推理成本,同时保持较高的生成质量。
技术框架:CITER框架包含两个主要模块:小型语言模型(SLM)、大型语言模型(LLM)和一个路由器。输入文本首先经过令牌化处理,然后路由器根据每个令牌的特征,预测一个路由分数。该分数决定了该令牌将被路由到SLM还是LLM进行处理。SLM和LLM分别生成对应的输出,最终合并成完整的输出序列。路由器的训练采用策略优化方法,目标是最大化生成质量并最小化推理成本。
关键创新:CITER的关键创新在于令牌级路由策略和路由器训练方法。传统的模型选择通常是针对整个句子或段落,而CITER能够细粒度地针对每个令牌进行选择,更加灵活高效。路由器训练采用策略优化,将生成质量和推理成本纳入奖励函数,使得路由器能够学习到最优的路由策略。此外,论文还提出了一种快捷方式来加速奖励评估过程,提高了方法的实用性。
关键设计:路由器采用神经网络结构,输入是当前令牌的嵌入表示,输出是路由分数。奖励函数综合考虑了生成质量(例如困惑度)和推理成本(例如模型大小和计算时间)。策略优化采用REINFORCE算法,通过采样不同的路由决策并根据奖励更新路由器参数。快捷方式通过预先计算部分奖励,减少了在线评估的计算量。
🖼️ 关键图片
📊 实验亮点
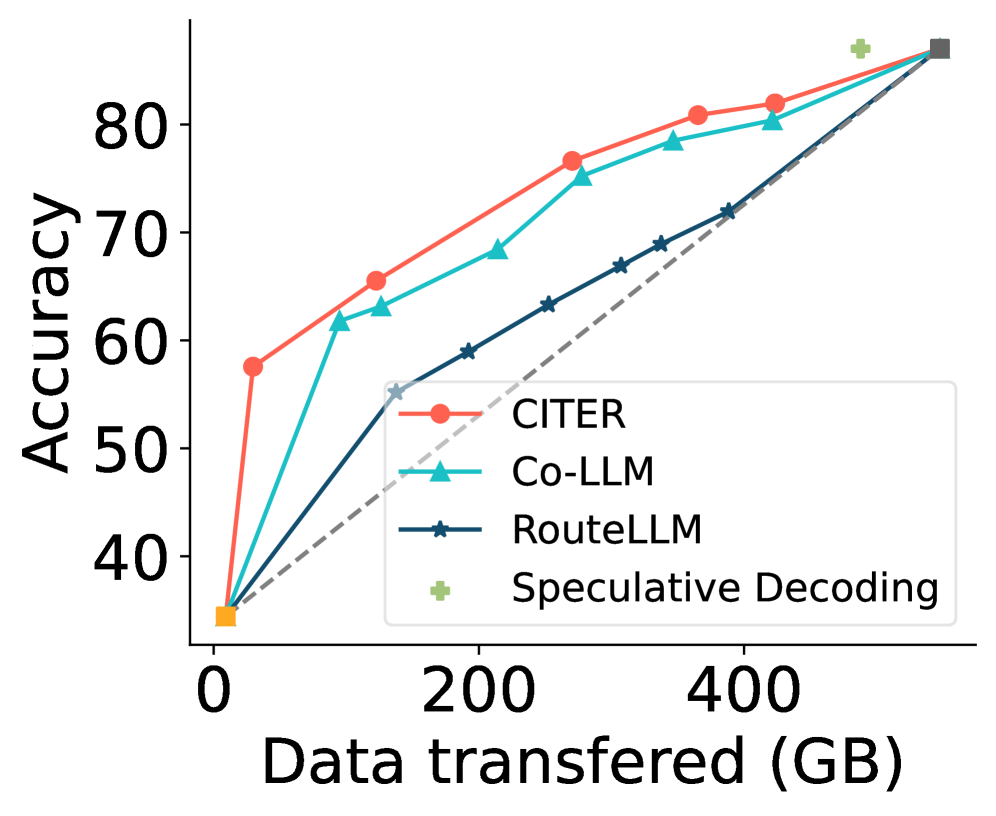
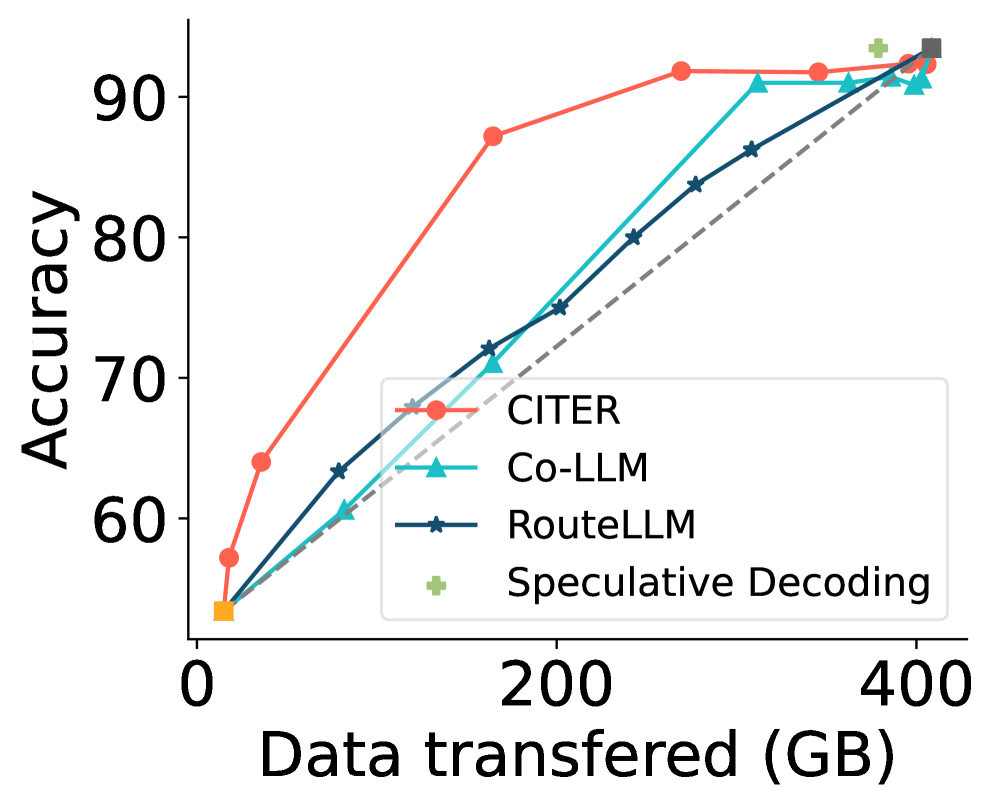
实验结果表明,CITER在五个基准数据集上实现了显著的性能提升。例如,在某些数据集上,CITER能够在保持与LLM相当的生成质量的前提下,将推理成本降低高达40%。与传统的模型选择方法相比,CITER在效率和质量之间取得了更好的平衡,证明了其有效性和实用性。
🎯 应用场景
CITER适用于各种需要高效推理的场景,例如移动设备上的实时翻译、智能客服中的快速回复、以及边缘计算环境下的自然语言处理任务。该方法可以显著降低计算成本,使得大型语言模型能够在资源受限的环境中部署,从而扩展了其应用范围,并加速了AI技术的普及。
📄 摘要(原文)
Large language models have achieved remarkable success in various tasks but suffer from high computational costs during inference, limiting their deployment in resource-constrained applications. To address this issue, we propose a novel Collaborative Inference with Token-lEvel Routing (CITER) framework that enables efficient collaboration between small and large language models (SLMs \& LLMs) through a token-level routing strategy. Specifically, CITER routes non-critical tokens to an SLM for efficiency and routes critical tokens to an LLM for generalization quality. We formulate router training as a policy optimization, where the router receives rewards based on both the quality of predictions and the inference costs of generation. This allows the router to learn to predict token-level routing scores and make routing decisions based on both the current token and the future impact of its decisions. To further accelerate the reward evaluation process, we introduce a shortcut which significantly reduces the costs of the reward estimation and improving the practicality of our approach. Extensive experiments on five benchmark datasets demonstrate that CITER reduces the inference costs while preserving high-quality generation, offering a promising solution for real-time and resource-constrained applications. Our data and code are available at https://github.com/aiming-lab/CITER.