Token Cleaning: Fine-Grained Data Selection for LLM Supervised Fine-Tuning
作者: Jinlong Pang, Na Di, Zhaowei Zhu, Jiaheng Wei, Hao Cheng, Chen Qian, Yang Liu
分类: cs.CL, cs.AI
发布日期: 2025-02-04 (更新: 2025-06-09)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Token Cleaning方法,通过细粒度数据选择提升LLM监督微调效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 监督微调 数据清洗 Token选择 噪声标签
📋 核心要点
- 现有SFT方法忽略了样本内token质量差异,冗余或有害token会降低模型性能。
- Token Cleaning通过评估模型更新对每个token的影响,过滤无信息token,保留关键token。
- 实验表明,该框架能持续提升下游任务性能,验证了token级别数据清洗的有效性。
📝 摘要(中文)
最近的研究表明,在大语言模型(LLM)的监督微调(SFT)中,数据质量比数量更重要。虽然大多数数据清洗方法侧重于过滤整个样本,但样本中各个token的质量可能差异很大。即使在高质量的样本中,经过预训练后,与任务无关的模式或短语也可能是冗余的、无信息的,甚至是有害的。继续在这些模式上进行微调可能收益有限,甚至会降低下游任务的性能。在本文中,我们从噪声标签的角度研究了token质量,并为SFT任务提出了一个通用的token清洗流程。我们的方法过滤掉无信息的token,同时保留那些携带关键任务特定信息的token。具体来说,我们首先通过检查模型更新对每个token的影响来评估token质量,然后应用基于阈值的分离。token影响可以通过使用固定参考模型的单次传递来测量,也可以通过使用自演化参考模型的迭代来测量。通过误差上界分析了这两种方法的优点和局限性。大量的实验表明,我们的框架始终如一地提高了下游性能。
🔬 方法详解
问题定义:现有的大语言模型监督微调(SFT)方法通常关注于样本级别的质量控制,例如过滤掉低质量的样本。然而,即使在高品质的样本中,也可能存在大量与特定任务无关、冗余甚至有害的token。这些token的存在会降低微调的效率,甚至损害模型在下游任务上的表现。因此,如何识别并去除这些“噪声”token,从而提升SFT的效果,是本文要解决的核心问题。
核心思路:本文的核心思路是,将token质量评估视为一个噪声标签问题。通过考察模型在微调过程中对每个token的“关注”程度,来判断该token是否包含有用的信息。具体来说,如果模型对某个token的更新幅度很小,则认为该token的重要性较低,可以被过滤掉。反之,如果模型对某个token的更新幅度很大,则认为该token包含了关键的任务信息,应该被保留。
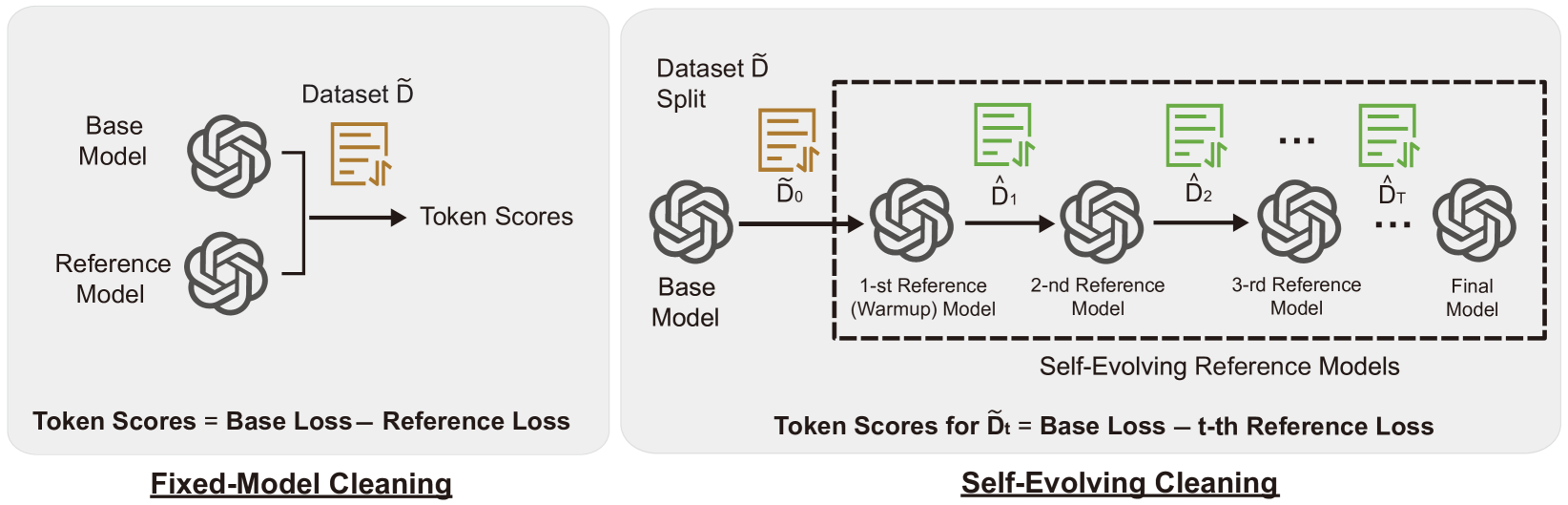
技术框架:Token Cleaning框架主要包含以下几个阶段:1. Token影响评估:使用参考模型(可以是预训练模型或迭代更新的模型)计算每个token对模型更新的影响。影响的计算基于模型参数更新的梯度或变化量。2. 阈值分离:设定一个阈值,将token分为两类:影响大于阈值的token被认为是“有用”的token,保留;影响小于阈值的token被认为是“无用”的token,过滤。3. 微调:使用清洗后的数据进行SFT。
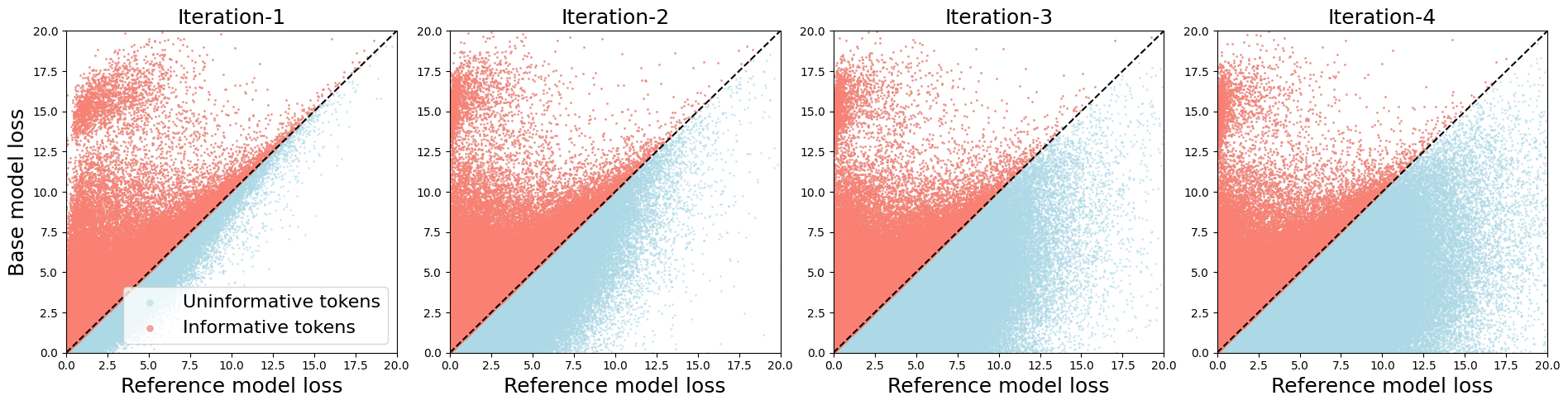
关键创新:该方法最重要的创新点在于,它将数据清洗的粒度从样本级别细化到了token级别。与传统的样本过滤方法相比,Token Cleaning能够更精确地识别和去除噪声数据,从而提升SFT的效果。此外,该方法还提出了两种不同的token影响评估策略:基于固定参考模型和基于自演化参考模型,并分析了它们的优缺点。
关键设计:在token影响评估方面,论文提出了两种策略:1. 单次传递(Single Pass):使用预训练模型作为参考模型,计算每个token对模型更新的影响。这种方法的优点是计算效率高,但缺点是参考模型可能与微调任务不匹配。2. 迭代(Iterative):使用自演化参考模型,即在每次迭代中使用上一次迭代的模型作为参考模型。这种方法的优点是参考模型能够更好地适应微调任务,但缺点是计算成本较高。阈值的选择可以基于统计分析或经验设定。
🖼️ 关键图片
📊 实验亮点
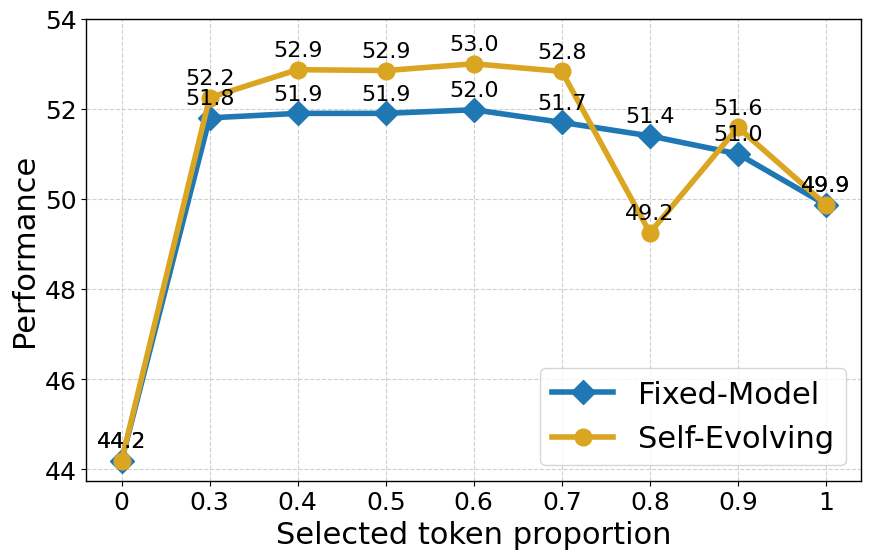
实验结果表明,Token Cleaning框架在多个下游任务上均取得了显著的性能提升。例如,在某些任务上,使用Token Cleaning后,模型的准确率提升了超过2%。此外,实验还验证了自演化参考模型策略的有效性,表明其能够更好地适应微调任务,从而获得更好的性能。
🎯 应用场景
Token Cleaning方法可广泛应用于各种大语言模型的监督微调任务中,尤其是在数据质量参差不齐的情况下。通过去除冗余和有害的token,可以提升模型的训练效率和下游任务性能。该方法在自然语言处理、文本生成、对话系统等领域具有重要的应用价值,并有望推动LLM在实际应用中的普及。
📄 摘要(原文)
Recent studies show that in supervised fine-tuning (SFT) of large language models (LLMs), data quality matters more than quantity. While most data cleaning methods concentrate on filtering entire samples, the quality of individual tokens within a sample can vary significantly. After pre-training, even in high-quality samples, patterns or phrases that are not task-related can be redundant, uninformative, or even harmful. Continuing to fine-tune on these patterns may offer limited benefit and even degrade downstream task performance. In this paper, we investigate token quality from a noisy-label perspective and propose a generic token cleaning pipeline for SFT tasks. Our method filters out uninformative tokens while preserving those carrying key task-specific information. Specifically, we first evaluate token quality by examining the influence of model updates on each token, then apply a threshold-based separation. The token influence can be measured in a single pass with a fixed reference model or iteratively with self-evolving reference models. The benefits and limitations of both methods are analyzed theoretically by error upper bounds. Extensive experiments show that our framework consistently improves downstream performance. Code is available at https://github.com/UCSC-REAL/TokenCleaning.