SelfCheck-Eval: A Multi-Module Framework for Zero-Resource Hallucination Detection in Large Language Models
作者: Diyana Muhammed, Giusy Giulia Tuccari, Gollam Rabby, Sören Auer, Sahar Vahdati
分类: cs.CL, cs.LG
发布日期: 2025-02-03 (更新: 2025-12-28)
💡 一句话要点
提出SelfCheck-Eval框架,用于零资源检测大语言模型中的幻觉问题,并构建数学推理幻觉数据集AIME。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 黑盒方法 数学推理 多模块架构
📋 核心要点
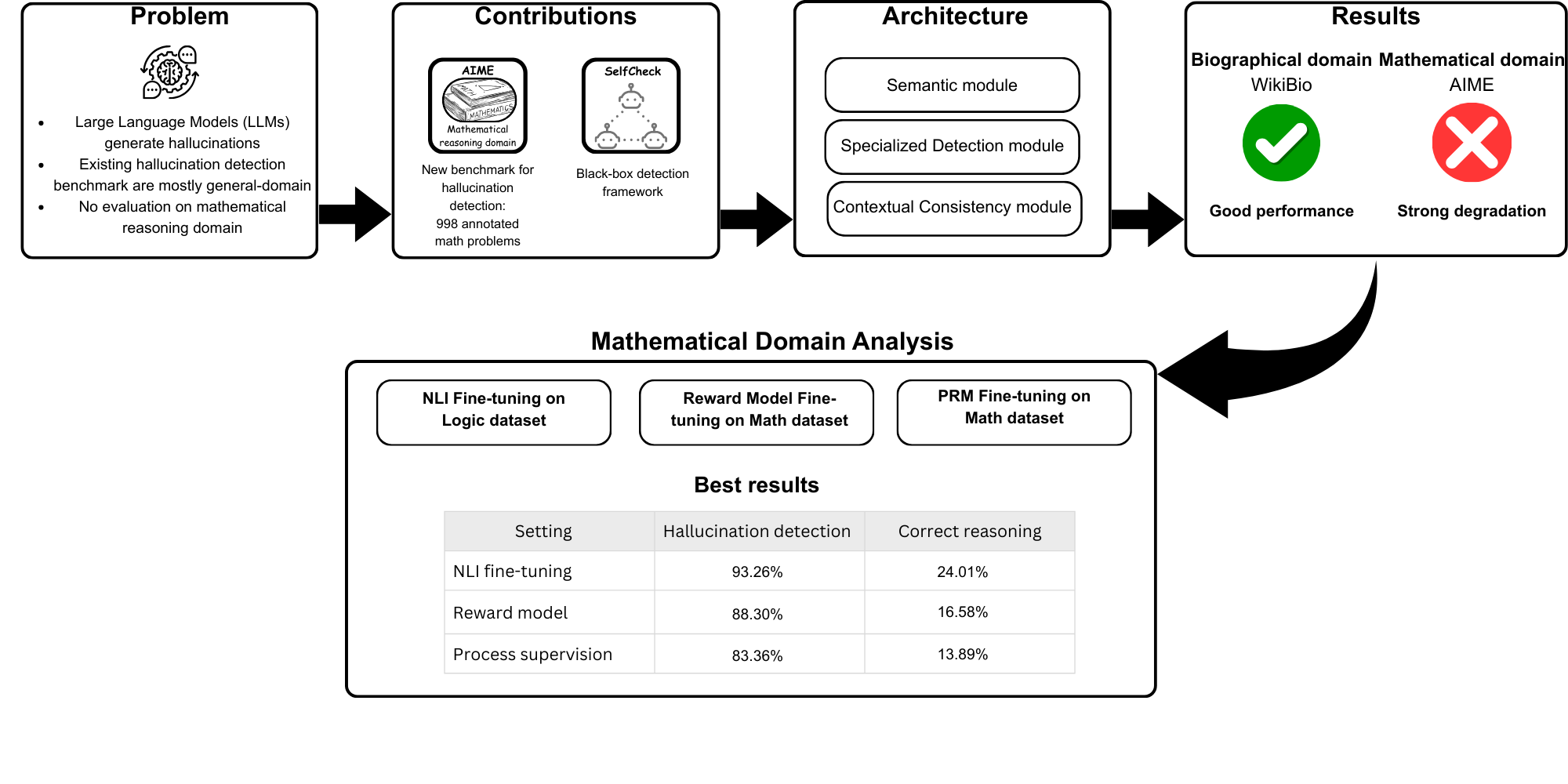
- 现有幻觉检测基准主要集中于通用知识,缺乏对数学等专业领域的评估,限制了LLM在高风险场景的应用。
- SelfCheck-Eval框架采用多模块架构,包含语义、专业检测和上下文一致性三个模块,实现黑盒幻觉检测。
- 实验表明,现有方法在数学推理方面表现不佳,凸显了SelfCheck-Eval框架在专业领域幻觉检测方面的必要性。
📝 摘要(中文)
大型语言模型(LLMs)在各种应用中表现出卓越的能力,从开放域问答到科学写作、医疗决策支持和法律分析。然而,它们生成不正确或捏造内容的倾向,通常被称为幻觉,是其在高风险领域可靠部署的关键障碍。当前的幻觉检测基准在范围上受到限制,主要关注一般知识领域,而忽略了准确性至关重要的专业领域。为了解决这一差距,我们引入了AIME Math Hallucination数据集,这是第一个专门为评估数学推理幻觉而设计的综合基准。此外,我们提出SelfCheck-Eval,一个与LLM无关的黑盒幻觉检测框架,适用于开放和闭源LLM。我们的方法利用了一种新颖的多模块架构,该架构集成了三种独立的检测策略:语义模块、专业检测模块和上下文一致性模块。我们的评估揭示了跨领域的系统性性能差异:现有方法在传记内容上表现良好,但在数学推理方面表现不佳,这一挑战在NLI微调、偏好学习和过程监督方法中仍然存在。这些发现突出了当前检测方法在数学领域中的根本局限性,并强调了对专门的、黑盒兼容方法以确保可靠的LLM部署的关键需求。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在数学推理等专业领域中产生幻觉的问题。现有幻觉检测方法主要集中在通用知识领域,无法有效检测LLMs在专业领域的错误或捏造内容,阻碍了LLMs在高风险领域的可靠应用。
核心思路:论文的核心思路是设计一个与LLM无关的黑盒幻觉检测框架,该框架能够通过多种独立的检测策略来识别LLMs生成的幻觉。通过结合语义理解、专业知识和上下文一致性检查,更全面地评估LLMs的输出质量。
技术框架:SelfCheck-Eval框架包含三个主要模块:1) 语义模块:评估LLM生成内容的语义合理性;2) 专业检测模块:利用专业知识库或规则来验证LLM生成内容的正确性;3) 上下文一致性模块:检查LLM生成内容在上下文中的一致性。这三个模块独立运行,并结合它们的输出来确定是否存在幻觉。
关键创新:SelfCheck-Eval的关键创新在于其多模块架构和黑盒特性。多模块架构能够从多个角度评估LLM的输出,提高幻觉检测的准确性。黑盒特性使得该框架可以应用于各种LLMs,无需访问LLMs的内部参数或进行微调。此外,AIME Math Hallucination数据集的构建也填补了数学推理幻觉检测基准的空白。
关键设计:具体的技术细节包括:语义模块可能使用预训练的语言模型来计算生成文本的语义相似度或困惑度;专业检测模块可能依赖于符号计算引擎或定理证明器来验证数学公式的正确性;上下文一致性模块可能使用信息检索技术来查找与生成内容相关的上下文信息,并检查一致性。具体的参数设置、损失函数和网络结构等细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有幻觉检测方法在数学推理方面表现显著不足,而SelfCheck-Eval框架通过多模块协同工作,能够更有效地检测数学推理中的幻觉。具体性能数据和提升幅度在摘要中未明确给出,属于未知信息,但强调了该框架在专业领域的优势。
🎯 应用场景
SelfCheck-Eval框架可应用于各种需要LLM提供可靠信息的领域,如医疗诊断、金融分析、法律咨询和科学研究。通过检测和纠正LLM的幻觉,可以提高LLM在这些领域的应用价值,并降低因错误信息带来的风险。该研究还有助于推动LLM的可信赖性和安全性。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse applications, from open-domain question answering to scientific writing, medical decision support, and legal analysis. However, their tendency to generate incorrect or fabricated content, commonly known as hallucinations, represents a critical barrier to reliable deployment in high-stakes domains. Current hallucination detection benchmarks are limited in scope, focusing primarily on general-knowledge domains while neglecting specialised fields where accuracy is paramount. To address this gap, we introduce the AIME Math Hallucination dataset, the first comprehensive benchmark specifically designed for evaluating mathematical reasoning hallucinations. Additionally, we propose SelfCheck-Eval, a LLM-agnostic, black-box hallucination detection framework applicable to both open and closed-source LLMs. Our approach leverages a novel multi-module architecture that integrates three independent detection strategies: the Semantic module, the Specialised Detection module, and the Contextual Consistency module. Our evaluation reveals systematic performance disparities across domains: existing methods perform well on biographical content but struggle significantly with mathematical reasoning, a challenge that persists across NLI fine-tuning, preference learning, and process supervision approaches. These findings highlight the fundamental limitations of current detection methods in mathematical domains and underscore the critical need for specialised, black-box compatible approaches to ensure reliable LLM deployment.