Evaluation of Large Language Models via Coupled Token Generation
作者: Nina Corvelo Benz, Stratis Tsirtsis, Eleni Straitouri, Ivi Chatzi, Ander Artola Velasco, Suhas Thejaswi, Manuel Gomez-Rodriguez
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-02-03 (更新: 2025-08-25)
💡 一句话要点
提出基于耦合Token生成的大语言模型评估方法,减少评估样本量并发现传统评估的潜在偏差。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型评估 耦合自回归生成 随机性控制 基准测试 成对比较
📋 核心要点
- 大语言模型评估受随机性影响,多次提问结果不一致,现有评估方法未能有效控制这种随机性。
- 提出耦合自回归生成方法,通过共享随机源,使不同模型在相同随机条件下生成响应,从而更公平地评估模型性能。
- 实验表明,耦合方法在基准测试中减少了高达75%的样本需求,并在成对比较中揭示了传统评估方法可能存在的偏差。
📝 摘要(中文)
当前的大语言模型依赖随机化来响应提示。因此,对于相同的提示,模型多次响应可能不同。本文认为,大语言模型的评估和排序应控制其运行机制中的随机性。首先,本文提出了耦合自回归生成的因果模型,允许多个大语言模型使用相同的随机源来采样响应。在此基础上,本文证明了在基于基准数据集的评估中,耦合自回归生成与普通自回归生成得出相同的结论,但使用的样本量更少。然而,在基于(人工)成对比较的评估中,当比较两个以上的模型时,即使有无限的样本,耦合和普通自回归生成也可能导致不同的排名。这表明,现有评估协议中一个模型相对于其他模型的明显优势可能并非真实,而是受到生成过程固有随机性的干扰。为了说明和补充理论结果,本文使用Llama、Mistral和Qwen系列中的多个大型语言模型进行了实验。结果表明,在多个基准数据集上,耦合自回归生成达到与普通自回归生成相同结论所需的样本量最多减少75%。此外,本文发现,在LMSYS Chatbot Arena平台的提示下,强大的大型语言模型通过成对比较得出的胜率在耦合和普通自回归生成下有所不同。
🔬 方法详解
问题定义:现有大语言模型评估方法,如基于基准数据集的指标计算和基于人工成对比较的胜率统计,受到模型生成过程中的随机性的影响。这意味着即使是相同的模型和相同的提示,多次运行也可能得到不同的结果,从而导致评估结果的不稳定性和偏差。现有方法未能有效控制这种随机性,使得模型之间的比较可能受到随机因素的干扰,难以准确反映模型的真实性能。
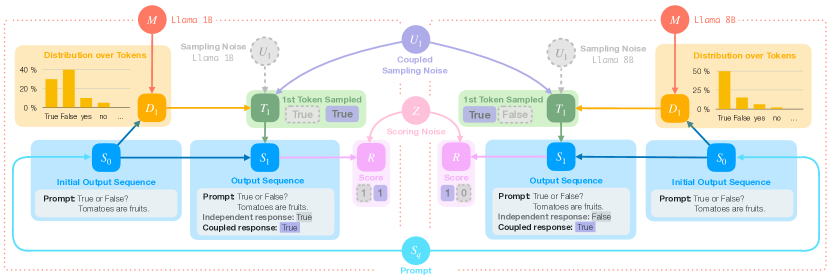
核心思路:本文的核心思路是通过耦合自回归生成过程,使得不同的大语言模型在相同的随机条件下生成响应。具体来说,就是让不同的模型共享相同的随机数种子,从而在生成token的过程中,每个模型都使用相同的随机数来决定下一个token的选择。这样,就可以消除由于随机性带来的干扰,从而更公平地比较不同模型的性能。
技术框架:本文提出了一个耦合自回归生成的因果模型。该模型的核心思想是,通过共享随机数种子,使得不同的模型在生成token的过程中,使用相同的随机数。具体来说,该模型包含以下几个主要模块:1) 随机数生成器:生成随机数种子;2) token生成器:根据随机数种子和模型参数,生成token;3) 评估模块:根据生成的token,计算评估指标或进行人工比较。整个流程是,首先由随机数生成器生成随机数种子,然后将该种子传递给不同的token生成器,每个token生成器根据该种子和自身的模型参数,生成token序列,最后由评估模块根据生成的token序列,计算评估指标或进行人工比较。
关键创新:本文最重要的技术创新点是提出了耦合自回归生成方法。与传统的自回归生成方法相比,该方法通过共享随机数种子,使得不同的模型在相同的随机条件下生成响应。这可以消除由于随机性带来的干扰,从而更公平地比较不同模型的性能。此外,本文还提出了一个耦合自回归生成的因果模型,该模型可以用于分析和理解耦合自回归生成过程。
关键设计:在实验中,作者使用了Llama、Mistral和Qwen等多个大型语言模型。对于每个模型,作者都使用了相同的随机数种子,并生成了多个token序列。然后,作者使用这些token序列来计算评估指标或进行人工比较。作者还研究了不同随机数种子对评估结果的影响。此外,作者还分析了耦合自回归生成过程中的一些关键参数,如温度系数和top-p采样概率。
🖼️ 关键图片
📊 实验亮点
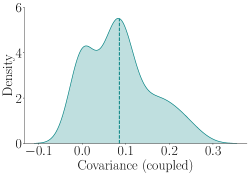
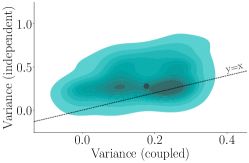
实验结果表明,在多个基准数据集上,耦合自回归生成达到与普通自回归生成相同结论所需的样本量最多减少75%。此外,在LMSYS Chatbot Arena平台的提示下,强大的大型语言模型通过成对比较得出的胜率在耦合和普通自回归生成下有所不同,揭示了传统评估方法可能存在的偏差。
🎯 应用场景
该研究成果可应用于大语言模型的公平评估与基准测试,帮助研究者和开发者更准确地了解模型的真实性能。通过减少评估所需的样本量,可以降低评估成本,加速模型迭代。此外,该方法有助于发现现有评估方法中存在的偏差,从而改进评估协议,提升评估的可靠性。
📄 摘要(原文)
State of the art large language models rely on randomization to respond to a prompt. As an immediate consequence, a model may respond differently to the same prompt if asked multiple times. In this work, we argue that the evaluation and ranking of large language models should control for the randomization underpinning their functioning. Our starting point is the development of a causal model for coupled autoregressive generation, which allows different large language models to sample responses with the same source of randomness. Building upon our causal model, we first show that, on evaluations based on benchmark datasets, coupled autoregressive generation leads to the same conclusions as vanilla autoregressive generation but using provably fewer samples. However, we further show that, on evaluations based on (human) pairwise comparisons, coupled and vanilla autoregressive generation can surprisingly lead to different rankings when comparing more than two models, even with an infinite amount of samples. This suggests that the apparent advantage of a model over others in existing evaluation protocols may not be genuine but rather confounded by the randomness inherent to the generation process. To illustrate and complement our theoretical results, we conduct experiments with several large language models from the Llama, Mistral and Qwen families. We find that, across multiple benchmark datasets, coupled autoregressive generation requires up to 75% fewer samples to reach the same conclusions as vanilla autoregressive generation. Further, we find that the win-rates derived from pairwise comparisons by a strong large language model to prompts from the LMSYS Chatbot Arena platform differ under coupled and vanilla autoregressive generation.