LLM-TA: An LLM-Enhanced Thematic Analysis Pipeline for Transcripts from Parents of Children with Congenital Heart Disease
作者: Muhammad Zain Raza, Jiawei Xu, Terence Lim, Lily Boddy, Carlos M. Mery, Andrew Well, Ying Ding
分类: cs.CL, cs.HC
发布日期: 2025-02-03
备注: Accepted by GenAI for Health Workshop @ AAAI 2025, Philadelphia
🔗 代码/项目: GITHUB
💡 一句话要点
提出LLM-TA:一种LLM增强的主题分析流程,用于分析先天性心脏病患儿父母的访谈记录。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 主题分析 医疗保健 提示工程 LangChain
📋 核心要点
- 传统主题分析资源密集且难以扩展到大型复杂数据集,限制了其在高风险医疗环境中的应用。
- LLM-TA流程利用GPT-4o mini等LLM,结合LangChain和提示工程,辅助分析访谈记录,提取主题。
- 实验表明,LLM-TA流程显著优于现有LLM辅助方法,在可扩展性、效率和准确性方面具有潜力。
📝 摘要(中文)
本研究探讨了大型语言模型(LLM)在医疗保健研究中增强归纳主题分析(TA)流程的潜力,尤其是在高风险场景下。针对罕见先天性心脏病——冠状动脉起源异常(AAOCA)患儿父母的访谈记录,我们提出了一个LLM增强的主题分析(LLM-TA)流程。该流程集成了经济高效的先进LLM(GPT-4o mini)、LangChain和提示工程,并结合分块技术,按照归纳TA框架分析了九份详细的访谈记录。我们使用主题相似性指标、LLM辅助评估和专家评审,将LLM生成的主题与人工生成的结果进行比较。结果表明,我们的流程显著优于现有的LLM辅助TA方法。虽然该流程尚未达到人工归纳TA的水平,但它在提高可扩展性、效率和准确性方面显示出巨大潜力,同时减少了分析师与领域专家协作的工作量。我们为将LLM纳入高风险TA工作流程提供了实用建议,并强调了与领域专家密切合作以应对与实际应用和数据集复杂性相关的挑战的重要性。
🔬 方法详解
问题定义:论文旨在解决医疗保健研究中主题分析(TA)流程效率低、可扩展性差的问题。传统TA方法需要大量人工参与,成本高昂,且难以处理大规模、复杂的数据集。尤其是在高风险场景下,例如分析罕见疾病患者家属的访谈记录,对分析的准确性和可靠性要求更高。现有LLM辅助的TA方法在归纳主题分析方面表现不佳,无法达到人工水平。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大文本理解和生成能力,自动化或半自动化主题分析流程,从而提高效率、降低成本并提升可扩展性。通过精心设计的提示工程(Prompt Engineering)和分块技术(Chunking Techniques),引导LLM从访谈记录中提取有意义的主题。
技术框架:LLM-TA流程主要包含以下几个阶段:1) 数据准备:将访谈记录进行预处理,例如去除噪音、分句等。2) 分块处理:将长文本分割成更小的块,以适应LLM的输入长度限制。3) LLM主题提取:使用LangChain框架,结合提示工程,调用GPT-4o mini模型,从每个文本块中提取主题。4) 主题整合:将从不同文本块中提取的主题进行整合,去除重复或相似的主题。5) 评估与验证:使用主题相似性指标、LLM辅助评估和专家评审,评估LLM生成主题的质量。
关键创新:论文的关键创新在于提出了一个完整的、可操作的LLM增强的主题分析流程(LLM-TA),并针对高风险医疗场景进行了优化。该流程结合了GPT-4o mini模型、LangChain框架和提示工程,能够有效地从访谈记录中提取主题。此外,论文还提出了一套评估LLM生成主题质量的方法,包括主题相似性指标、LLM辅助评估和专家评审。
关键设计:在提示工程方面,论文设计了详细的提示语,引导LLM进行主题提取,例如明确要求LLM提取主题的类型、数量和格式。在分块处理方面,论文采用了滑动窗口的方法,确保文本块之间的上下文信息得以保留。在主题整合方面,论文使用了余弦相似度等指标,衡量不同主题之间的相似性,并进行聚类,去除重复或相似的主题。具体参数设置未知。
🖼️ 关键图片
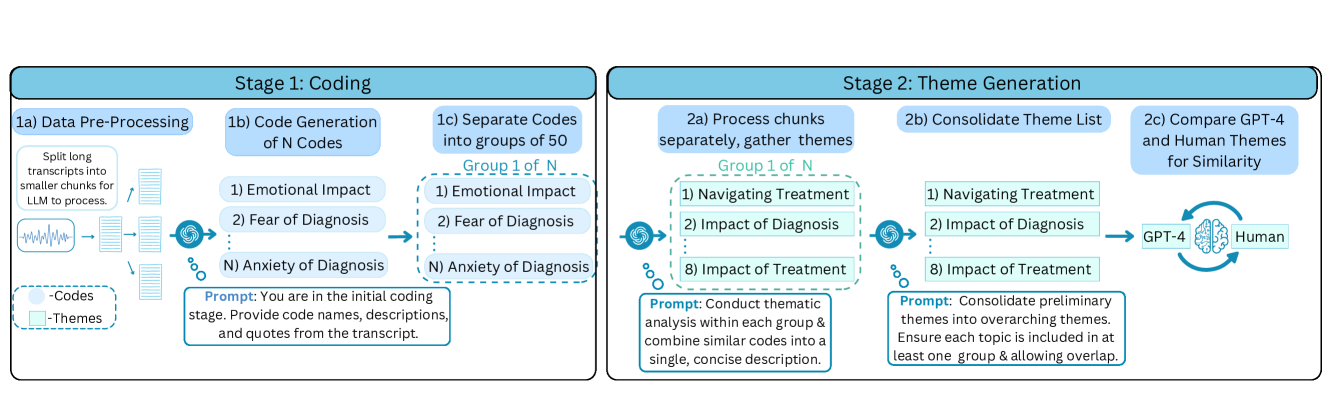


📊 实验亮点
实验结果表明,LLM-TA流程在主题提取方面显著优于现有的LLM辅助方法。具体而言,LLM-TA流程在主题相似性指标上取得了更高的分数,表明其生成的主题与人工生成的主题更加一致。此外,专家评审也认为LLM-TA流程生成的主题具有更高的质量和相关性。具体性能数据未知。
🎯 应用场景
该研究成果可应用于医疗保健领域,例如分析患者访谈记录、临床报告等,以发现疾病的潜在风险因素、评估治疗效果、优化医疗服务。此外,该方法还可以推广到其他领域,例如市场调研、社会科学研究等,用于分析大规模文本数据,提取有价值的信息。
📄 摘要(原文)
Thematic Analysis (TA) is a fundamental method in healthcare research for analyzing transcript data, but it is resource-intensive and difficult to scale for large, complex datasets. This study investigates the potential of large language models (LLMs) to augment the inductive TA process in high-stakes healthcare settings. Focusing on interview transcripts from parents of children with Anomalous Aortic Origin of a Coronary Artery (AAOCA), a rare congenital heart disease, we propose an LLM-Enhanced Thematic Analysis (LLM-TA) pipeline. Our pipeline integrates an affordable state-of-the-art LLM (GPT-4o mini), LangChain, and prompt engineering with chunking techniques to analyze nine detailed transcripts following the inductive TA framework. We evaluate the LLM-generated themes against human-generated results using thematic similarity metrics, LLM-assisted assessments, and expert reviews. Results demonstrate that our pipeline outperforms existing LLM-assisted TA methods significantly. While the pipeline alone has not yet reached human-level quality in inductive TA, it shows great potential to improve scalability, efficiency, and accuracy while reducing analyst workload when working collaboratively with domain experts. We provide practical recommendations for incorporating LLMs into high-stakes TA workflows and emphasize the importance of close collaboration with domain experts to address challenges related to real-world applicability and dataset complexity. https://github.com/jiaweixu98/LLM-TA